
Abstract
In this work, we investigate the problem of secure wildcard search over encrypted data. The setting comprises of three entities, viz. the data owner, the server and the client. The data owner outsources the encrypted data to the server, who obliviously services the clients’ queries. We first analyze efficiency and security of two recent proposals from International Journal of Information Security, called, respectively, the Wei–Reiter (WR) and Hu–Han (HH) protocol. We demonstrate that HH protocol is completely insecure while WR is not scalable for the problem of wildcard search over encrypted data. Our main contribution consists of three protocols, viz. \(\mathsf {\Pi }_{\mathsf {OXT}}\), \(\mathsf {\Pi }_{{\mathsf {BS}}}\) and \(\mathsf {\Pi }_{{\mathsf {OTE}}}\), to support secure wildcard search over encrypted data. Protocols \(\mathsf {\Pi }_{\mathsf {OXT}}\) and \(\mathsf {\Pi }_{{\mathsf {BS}}}\) reduce the problem of secure wildcard search to that of boolean search. The search time in \(\mathsf {\Pi }_{\mathsf {OXT}}\) and \(\mathsf {\Pi }_{{\mathsf {BS}}}\) is sub-linear in the number of keywords. \(\mathsf {\Pi }_{\mathsf {OXT}}\) and \(\mathsf {\Pi }_{{\mathsf {BS}}}\) do not rule out false positives completely, but our experiment results indicate that the false positive rate of both the protocols is very less. Our third protocol \(\mathsf {\Pi }_{{\mathsf {OTE}}}\) utilizes Oblivious Transfer Extension protocols to achieve linear time wildcard search with no false positive. \(\mathsf {\Pi }_{\mathsf {OXT}}\)/\(\mathsf {\Pi }_{{\mathsf {BS}}}\) and \(\mathsf {\Pi }_{{\mathsf {OTE}}}\) can be easily combined to obtain the first construction that addresses the problem of wildcard search in the three-party setting achieving sub-linear search time with no false positives or false negatives. We provide performance analysis based on our prototype implementations to depict the feasibility of our proposed constructions.

















Similar content being viewed by others



Notes
The authors in [41] miscalculated the same expression as \((1-1/2^{15})^{\ell +1}\). Note that in the correct expression the advantage increases as \(\ell \) increases.
A subsequence is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
Our encoding is inspired by and a formalization of the structure used in Hu–Han protocol. We observed that the metrics used in Hu–Han protocol (Sect. 3.2.1) still leave significant false positives. We introduce more metrics to filter out those false positives in our protocol.
Here, we only consider all n length subsequences \(c_{1}\cdots c_{n}\) with encodings \((c_{1}\cdots c_{n}\Vert o)\) (Occurrence) and \((c_{1}\cdots c_{n}\Vert d_{1}\Vert \cdots \Vert d_{n-1} \Vert o)\) (Distance with Occurrence), where o denotes the occurrence number and \(\forall i\) \(\in \) \([n-1]\), \(d_{i}\) denotes the distance between \(c_{i}\) and \(c_{i+1}\), in our encodings.
To achieve sub-linear time complexity, the client should represent the query in the form \(x_1\wedge \phi (x_2,\dots ,x_n)\), where \(x_1\) does not have too many matches.
In \(\mathsf {OSPIR}-\mathsf {OXT}\) of [21], such a hash function was used implicitly in the \({\mathsf {TSet}}\) realization.
References
Anderlik, M.R., Rothstein, M.A.: Privacy and confidentiality of genetic information: what rules for the new science? Ann. Rev. Genom. Hum. Genet. 2(1), 401–433 (2001)
Bellare, M., Hoang, V.T., Keelveedhi, S., Rogaway, P.: Efficient garbling from a fixed-key blockcipher. In: IEEE Symposium on Security and Privacy, pp. 478–492. IEEE Computer Society Press (2013)
Bloom, B.H.: Space/time trade-offs in hash coding with allowable errors. Commun. ACM 13(7), 422–426 (1970)
Boneh, D., Goh, E.J., Nissim, K.: Evaluating 2-DNF formulas on ciphertexts. In: TCC. LNCS, vol. 3378, pp. 325–341. Springer (2005)
Bösch, C., Brinkman, R., Hartel, P., Jonker, W.: Conjunctive wildcard search over encrypted data. In: SDM. LNCS, vol. 6933, pp. 114–127. Springer (2011)
Cash, D., Jaeger, J., Jarecki, S., Jutla, C.S., Krawczyk, H., Rosu, M., Steiner, M.: Dynamic Searchable encryption in very-large databases: data structures and implementation. In: NDSS. The Internet Society (2014)
Cash, D., Jarecki, S., Jutla, C., Krawczyk, H., Roşu, M.C., Steiner, M.: Highly-scalable searchable symmetric encryption with support for boolean queries. In: CRYPTO-I. LNCS, vol. 8042, pp. 353–373. Springer (2013)
Chase, M., Kamara, S.: Structured encryption and controlled disclosure. In: ASIACRYPT. LNCS, vol. 6477, pp. 577–594. Springer (2010)
Curtmola, R., Garay, J.A., Kamara, S., Ostrovsky, R.: Searchable symmetric encryption: improved definitions and efficient constructions. J. Comput. Secur. 19(5), 895–934 (2011)
Demertzis, I., Papadopoulos, S., Papapetrou, O., Deligiannakis, A., Garofalakis, M.N.: Practical private range search revisited. In: SIGMOD, pp. 185–198. ACM (2016)
Faber, S., Jarecki, S., Krawczyk, H., Nguyen, Q., Rosu, M., Steiner, M.: Rich queries on encrypted data: beyond exact matches. In: ESORICS. LNCS, vol. 9327, pp. 123–145. Springer (2015)
Fips, P.: 186-2. Digital signature standard (DSS). National Institute of Standards and Technology (NIST), vol. 20, p. 13 (2000)
Fisch, B.A., Vo, B., Krell, F., Kumarasubramanian, A., Kolesnikov, V., Malkin, T., Bellovin, S.M.: Malicious-client security in blind seer: a scalable private DBMS. In: IEEE Symposium on Security and Privacy, pp. 395–410. IEEE Computer Society Press (2015)
Gerbet, T., Kumar, A., Lauradoux, C.: The power of evil choices in bloom filters. In: IEEE/IFIP International Conference on Dependable Systems and Networks. pp. 101–112. IEEE Computer Society (2015)
Gertner, Y., Ishai, Y., Kushilevitz, E., Malkin, T.: Protecting data privacy in private information retrieval schemes. J. Comput. Syst. Sci. 60(3), 592–629 (2000)
Goh, E.: Secure Indexes. IACR Cryptology ePrint Archive, vol. 2003, p. 216 (2003)
Hopcroft, J.E., Ullman, J.D.: Introduction to Automata Theory, Languages and Computation, 2nd edn. Addison-Wesley, Boston (2000)
Hu, C., Han, L.: Efficient wildcard search over encrypted data. IJIS 15(5), 539–547 (2016)
Huang, Y., Evans, D., Katz, J., Malka, L.: Faster secure two-party computation using garbled circuits. In: USENIX Security Symposium. USENIX Association (2011)
Ishai, Y., Kilian, J., Nissim, K., Petrank, E.: Extending oblivious transfers efficiently. In: CRYPTO. LNCS, vol. 2729, pp. 145–161. Springer (2003)
Jarecki, S., Jutla, C.S., Krawczyk, H., Rosu, M., Steiner, M.: Outsourced symmetric private information retrieval. In: ACM CCS, pp. 875–888. ACM Press (2013)
Kamara, S., Moataz, T.: Boolean searchable symmetric encryption with worst-case sub-linear complexity. In: EUROCRYPT. LNCS, vol. 10212, pp. 94–124. Springer (2017)
Kamara, S., Papamanthou, C., Roeder, T.: Dynamic searchable symmetric encryption. In: ACM CCS, pp. 965–976. ACM Press (2012)
Katz, J., Lindell, Y.: Introduction to Modern Cryptography (Chapman & Hall/Crc Cryptography and Network Security Series). Chapman & Hall/CRC, New York (2007)
Kolesnikov, V., Kumaresan, R.: Improved OT extension for transferring short secrets. In: CRYPTO. LNCS, vol. 8043, pp. 54–70. Springer (2013)
Kolesnikov, V., Kumaresan, R., Rosulek, M., Trieu, N.: Efficient batched oblivious PRF with applications to private set intersection. In: ACM CCS, pp. 818–829. ACM Press (2016)
Kolesnikov, V., Rosulek, M., Trieu, N.: SWiM: Secure Wildcard Pattern Matching From OT Extension. IACR Cryptology ePrint Archive, vol. 2017, p. 1150 (2017)
Kushilevitz, E., Ostrovsky, R.: Replication is not needed: SINGLE database, computationally-private information retrieval. In: FOCS, pp. 364–373. IEEE Computer Society (1997)
Lai, S., Patranabis, S., Sakzad, A., Liu, J.K., Mukhopadhyay, D., Steinfeld, R., Sun, S., Liu, D., Zuo, C.: Result pattern hiding searchable encryption for conjunctive queries. In: CCS, pp. 745–762. ACM (2018)
Lindell, Y., Pinkas, B.: A proof of security of Yao’s protocol for two-party computation. J. Cryptol. 22(2), 161–188 (2009)
Naor, D., Naor, M., Lotspiech, J.: Revocation and tracing schemes for stateless receivers. In: CRYPTO, LNCS, vol. 2139, pp. 41–62. Springer (2001)
Pappas, V., Krell, F., Vo, B., Kolesnikov, V., Malkin, T., Choi, S.G., George, W., Keromytis, A.D., Bellovin, S.M.: Blind Seer: a scalable private DBMS. In: IEEE Symposium on Security and Privacy. pp. 359–374. IEEE Computer Society Press (2014)
Rabin, M.O.: How to Exchange Secrets with Oblivious Transfer. IACR Cryptology ePrint Archive, vol. 2005, p. 187 (2005)
Rindal, P.: libOTe: an efficient, portable, and easy to use Oblivious Transfer Library. https://github.com/osu-crypto/libOTe. Accessed 11 Dec 2019
Shamir, A.: How to share a secret. Commun. ACM 22(11), 612–613 (1979)
Smart, N.P.: Cryptography Made Simple. Information Security and Cryptography. Springer, New York (2016)
Song, D.X., Wagner, D.A., Perrig, A.: Practical techniques for searches on encrypted data. In: IEEE Symposium on Security and Privacy. pp. 44–55. IEEE Computer Society Press (2000)
Sun, S., Liu, J.K., Sakzad, A., Steinfeld, R., Yuen, T.H.: An efficient non-interactive multi-client searchable encryption with support for boolean queries. In: ESORICS. LNCS, vol. 9878, pp. 154–172. Springer (2016)
The OpenSSL Project: OpenSSL Cryptography and SSL/TLS Toolkit. https://www.openssl.org/, Accessed 14 May 2018
Wei, L., Reiter, M.K.: Third-party private DFA evaluation on encrypted files in the cloud. In: ESORICS. LNCS, vol. 7459, pp. 523–540. Springer (2012)
Wei, L., Reiter, M.K.: Toward practical encrypted email that supports private, regular-expression searches. IJIS 14(5), 397–416 (2015)
WSJ: U.S. Terrorism Agency to Tap a Vast Database of Citizens. Wall Street Journal 12/13/12. http://alturl.com/ot72x. Accessed 14 May 2018
Yao, A.C.: Protocols for secure computations (extended abstract). In: FOCS, pp. 160–164. IEEE Computer Society (1982)
Yao, A.C.: How to generate and exchange secrets (extended abstract). In: FOCS, pp. 162–167. IEEE Computer Society (1986)
Zahur, S., Evans, D.: Obliv-C: A language for extensible data-oblivious computation. IACR Cryptology ePrint Archive, vol. 2015, p. 1153 (2015)
Zahur, S., Rosulek, M., Evans, D.: Two halves make a whole—reducing data transfer in garbled circuits using half gates. In: EUROCRYPT. LNCS, vol. 9057, pp. 220–250. Springer (2015)
Zhao, F., Nishide, T.: Searchable symmetric encryption supporting queries with multiple-character wildcards. In: NSS. LNCS, vol. 9955, pp. 266–282. Springer (2016)
Funding
The authors did not receive any funding to carry out the research work reported in this paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Three-party OXT protocol
Here, we present a formal description of \({\mathsf {3P}}-{\mathsf {OXT}}\). We follow the following notation: \({\mathsf {DO}}\) encrypts the keyword database  into encrypted database \(\mathsf{EDB}\); \({\textsf {C}}\) and \({\mathsf {DO}}\) run a two-party protocol to encrypt a formula
into encrypted database \(\mathsf{EDB}\); \({\textsf {C}}\) and \({\mathsf {DO}}\) run a two-party protocol to encrypt a formula  into a trapdoor \(\mathscr {T}\). Finally, \({\textsf {C}}\) and \({\textsf {S}}\) run a two-party protocol to find keyword that satisfies the formula.
into a trapdoor \(\mathscr {T}\). Finally, \({\textsf {C}}\) and \({\textsf {S}}\) run a two-party protocol to find keyword that satisfies the formula.
1.1 Construction
The following cryptographic primitives are used in \({\mathsf {3P}}-{\mathsf {OXT}}\) protocol. Four PRFs are used of which the PRF \(\mathsf {F}\) is defined as follows: \(\mathsf {F}(k, x)=\mathsf {H}(x)^k\) where \(\mathsf {H}:\mathbb {Z}_p\rightarrow \mathbb {G}\) is a hash function where \(\mathbb {G}\) is a prime order group. The other three PRFs are  , \(F_\xi :\mathbb {G}\times \mathbb {Z}_p\rightarrow \mathbb {Z}_p\) and
, \(F_\xi :\mathbb {G}\times \mathbb {Z}_p\rightarrow \mathbb {Z}_p\) and  where
where  . \({\mathsf {3P}}-{\mathsf {OXT}}\) also uses an \(\mathsf {IND}-\mathsf {CPA}\) secure symmetric encryption scheme \(\mathsf{sk}=(\mathsf {Gen}, \mathsf {Encrypt}, \mathsf {Decrypt})\) and an authenticated encryption scheme \(\varSigma _{A}=({\mathsf {AuthGen}}, {\mathsf {AuthEncrypt}}, {\mathsf {AuthDecrypt}})\).
. \({\mathsf {3P}}-{\mathsf {OXT}}\) also uses an \(\mathsf {IND}-\mathsf {CPA}\) secure symmetric encryption scheme \(\mathsf{sk}=(\mathsf {Gen}, \mathsf {Encrypt}, \mathsf {Decrypt})\) and an authenticated encryption scheme \(\varSigma _{A}=({\mathsf {AuthGen}}, {\mathsf {AuthEncrypt}}, {\mathsf {AuthDecrypt}})\).
1.1.1 Index generation
The index generation mostly follows [7, 21]. Recall from above \({\mathsf {TSet}}\) array stored the inverted index data structure \({\mathsf{kDB}}\) securely. Here, in Algorithm 9 we use a dictionary \(\mathscr {D}\) in place of using \({\mathsf {TSet}}\) array to store the data structure \({\mathsf{kDB}}\) securely. We now explain \(\mathsf {Setup}\) of \({\mathsf {3P}}-{\mathsf {OXT}}\) next informally.
In general, previous SSE constructions [7, 9] store the (inverted indexed) relation \({\mathsf{kDB}}\subset {\mathcal {Z}}\times {{\mathcal {ID}}}\) in ‘random locations’ of the array. Here, we use a dictionary \(\mathscr {D}\) to store such relation. Recall that a dictionary is a collection of (key, value) pairs. We evaluate a PRF on  to get a ‘random looking’ key of the dictionary and further compute a hash function on the PRF outputs which allowed proper simulation during the proof.Footnote 6 We store ciphertext corresponding to
to get a ‘random looking’ key of the dictionary and further compute a hash function on the PRF outputs which allowed proper simulation during the proof.Footnote 6 We store ciphertext corresponding to  in \(\mathscr {D}\). To enable searching, we also store two different commitments of the pair
in \(\mathscr {D}\). To enable searching, we also store two different commitments of the pair  in \(\mathscr {D}\) and \({\mathsf {XSet}}\). Basically during search we compute on the commitment stored in \(\mathscr {D}\) to test if the resultant commitment belongs to \({\mathsf {XSet}}\). We discuss these steps a little more concretely next.
in \(\mathscr {D}\) and \({\mathsf {XSet}}\). Basically during search we compute on the commitment stored in \(\mathscr {D}\) to test if the resultant commitment belongs to \({\mathsf {XSet}}\). We discuss these steps a little more concretely next.
Note that, for every \(c\)th \(\mathsf {id}\) in  , we evaluate the PRF \(F_\xi \) on \(\mathsf {stag}_\mathsf {id}\) to define corresponding ‘random looking’ dictionary key \(\ell _{c}\) where ‘secure information’ about \(\mathsf {id}\) will be stored. The ‘secure information’ about \(\mathsf {id}\) consists of encrypted \(\mathsf {id}\) \(e_{c}\), and a commitment of ‘\(\mathsf {id}\) is the \(c\)th identifier that contains
, we evaluate the PRF \(F_\xi \) on \(\mathsf {stag}_\mathsf {id}\) to define corresponding ‘random looking’ dictionary key \(\ell _{c}\) where ‘secure information’ about \(\mathsf {id}\) will be stored. The ‘secure information’ about \(\mathsf {id}\) consists of encrypted \(\mathsf {id}\) \(e_{c}\), and a commitment of ‘\(\mathsf {id}\) is the \(c\)th identifier that contains  ’ \(y_{c}\) (i.e., \({\texttt {xind}}\cdot v_{c}^{-1}\) in Line 7 of Algorithm 9). Note that there is another data structure \({\mathsf {XSet}}\) that is used to store \({\mathsf {xtag}}\); a commitment of ‘\(\mathsf {id}\) is an identifier that contains
’ \(y_{c}\) (i.e., \({\texttt {xind}}\cdot v_{c}^{-1}\) in Line 7 of Algorithm 9). Note that there is another data structure \({\mathsf {XSet}}\) that is used to store \({\mathsf {xtag}}\); a commitment of ‘\(\mathsf {id}\) is an identifier that contains  ’ (viz.
’ (viz.  in Line 9 of Algorithm 9). One important point to mention is \({\mathsf {DO}}\) chooses an authenticated encryption key
in Line 9 of Algorithm 9). One important point to mention is \({\mathsf {DO}}\) chooses an authenticated encryption key  only to share it with \({\textsf {S}}\) alone.
only to share it with \({\textsf {S}}\) alone.

1.1.2 Search
The search protocol also follows [7, 21] keeping in mind that a hash function is evaluated before inserting data in the dictionary \(\mathscr {D}\). Here, we describe the ‘trapdoor generation’ part and ‘performing search based on boolean queries’ part separately as two two-party protocols as follows:
Trapdoor generation To generate a trapdoor, \({\textsf {C}}\) invokes \({\mathsf {DO}}\) on boolean formula  . In this interactive trapdoor generation protocol, similar to [21], \({\textsf {C}}\) has a formula
. In this interactive trapdoor generation protocol, similar to [21], \({\textsf {C}}\) has a formula  and \({\mathsf {DO}}\) has few secret keys and has an authorization mechanism in place to verify policy \(\mathfrak {P}\) to check if \({\textsf {C}}\) is allowed to perform this search. After the protocol, \({\textsf {C}}\) learns a trapdoor \(\mathscr {T}\) but \({\mathsf {DO}}\) won’t learn anything about the formula
and \({\mathsf {DO}}\) has few secret keys and has an authorization mechanism in place to verify policy \(\mathfrak {P}\) to check if \({\textsf {C}}\) is allowed to perform this search. After the protocol, \({\textsf {C}}\) learns a trapdoor \(\mathscr {T}\) but \({\mathsf {DO}}\) won’t learn anything about the formula  [21]. The protocol has three rounds as described in Algorithm 10.
[21]. The protocol has three rounds as described in Algorithm 10.
-
1.
\({\textsf {C}}\) evaluates a randomized PRF \(\mathsf {F}\) (due to random seeds \(r_1,\ldots ,r_n\)) and an injective encoding I on each of
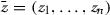 .
. -
2.
\({\mathsf {DO}}\) here follows [21] to receive the PRF outputs \((a_s, a_1,\ldots , a_n)\) and
 , \({\mathsf {DO}}\) checks if
, \({\mathsf {DO}}\) checks if  is satisfied by policy \(\mathfrak {P}\). Notice that
is satisfied by policy \(\mathfrak {P}\). Notice that 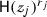 is linear in \(r_j\). \({\mathsf {DO}}\) exponentiates each \(a_i\) with secret key \(k_i\) and blinding factor \(\rho _i\) to get
is linear in \(r_j\). \({\mathsf {DO}}\) exponentiates each \(a_i\) with secret key \(k_i\) and blinding factor \(\rho _i\) to get 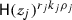 which also is
which also is  . Furthermore, \({\mathsf {DO}}\) gives all the used blinding factors in an envelope \({\mathsf {env}}\). Notice that the aim of \({\mathsf {DO}}\) here is to enable \({\textsf {C}}\) to perform two searches:
. Furthermore, \({\mathsf {DO}}\) gives all the used blinding factors in an envelope \({\mathsf {env}}\). Notice that the aim of \({\mathsf {DO}}\) here is to enable \({\textsf {C}}\) to perform two searches: 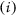 Find
Find  and
and 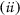 and find
and find  for \(j\in [2,n]\). To enable \({\textsf {C}}\) to search for
for \(j\in [2,n]\). To enable \({\textsf {C}}\) to search for  , \({\mathsf {DO}}\) gives trapdoor related to s-term and for cross-search for
, \({\mathsf {DO}}\) gives trapdoor related to s-term and for cross-search for  gives trapdoor related to x-terms.
gives trapdoor related to x-terms.More formally, \({\mathsf {DO}}\) creates \({\mathsf {token}}''=({\mathsf {strap}}', \mathsf {stag}', {\mathsf {xtrap}}'_2, \ldots , {\mathsf {xtrap}}'_n)\). In \({\mathsf {token}}''\), \({\mathsf {strap}}'\) is a commitment on the s-term
 , \(\mathsf {stag}\) lets one recompute \((\ell _{c}, R_{c})\) to retrieve
, \(\mathsf {stag}\) lets one recompute \((\ell _{c}, R_{c})\) to retrieve 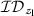 from \(\mathscr {D}\), and each of \({\mathsf {xtrap}}_j\) lets one perform the cross-check if an
from \(\mathscr {D}\), and each of \({\mathsf {xtrap}}_j\) lets one perform the cross-check if an  also satisfies
also satisfies  . However, \({\mathsf {DO}}\) blinds \(\mathsf {stag}'\) and \(\{{\mathsf {xtrap}}'_j\}_{j\in [2,n]}\) to \({\mathsf {bstag}}'\) and \(\{{\mathsf {bxtrap}}'_j\}_{j\in [2,n]}\), respectively, and encrypts the blinding factors as \({\mathsf {env}}\) using authenticated encryption key
. However, \({\mathsf {DO}}\) blinds \(\mathsf {stag}'\) and \(\{{\mathsf {xtrap}}'_j\}_{j\in [2,n]}\) to \({\mathsf {bstag}}'\) and \(\{{\mathsf {bxtrap}}'_j\}_{j\in [2,n]}\), respectively, and encrypts the blinding factors as \({\mathsf {env}}\) using authenticated encryption key 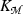 . \({\mathsf {DO}}\) sends \({\mathsf {token}}'=({\mathsf {strap}}', {\mathsf {bstag}}', {\mathsf {bxtrap}}'_2, \ldots , {\mathsf {bxtrap}}'_n)\) to \({\textsf {C}}\) where first two are trapdoor parts related to s-term and rest are related to x-terms.
. \({\mathsf {DO}}\) sends \({\mathsf {token}}'=({\mathsf {strap}}', {\mathsf {bstag}}', {\mathsf {bxtrap}}'_2, \ldots , {\mathsf {bxtrap}}'_n)\) to \({\textsf {C}}\) where first two are trapdoor parts related to s-term and rest are related to x-terms. -
3.
\({\textsf {C}}\) then removes the randomness \({\bar{r}}\) due to \(\mathsf {F}\) and sets \({\mathsf {token}}=({\mathsf {env}},{\mathsf {strap}}, {\mathsf {bstag}}, {\mathsf {bxtrap}}_2, \ldots , {\mathsf {bxtrap}}_n)\).
 .
. ,
,  is satisfied by policy
is satisfied by policy 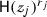 is linear in
is linear in 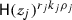 which also is
which also is  . Furthermore,
. Furthermore, 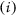 Find
Find  and
and 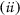 and find
and find  for
for  ,
,  gives trapdoor related to x-terms.
gives trapdoor related to x-terms. ,
, 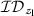 from
from  also satisfies
also satisfies  . However,
. However, 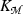 .
. 
Boolean search To perform the search, \({\textsf {C}}\) invokes \({\textsf {S}}\) on boolean formula \({\mathsf {token}}\). Note that the \({\mathsf {token}}\) was created from formula  and \({\textsf {S}}\) has
and \({\textsf {S}}\) has  (output of Setup in Algorithm 9). After the protocol, \({\textsf {C}}\) learns file identifiers \(\mathsf {id}\) that satisfies
(output of Setup in Algorithm 9). After the protocol, \({\textsf {C}}\) learns file identifiers \(\mathsf {id}\) that satisfies  and \({\textsf {S}}\) learns nothing new about \({\mathsf{kDB}}\). The protocol has three rounds as described in Algorithm 11.
and \({\textsf {S}}\) learns nothing new about \({\mathsf{kDB}}\). The protocol has three rounds as described in Algorithm 11.
-
1.
From \({\mathsf {strap}}\) in \({\mathsf {token}}\), \({\textsf {C}}\) creates several trapdoors iteratively until \({\textsf {S}}\) sends \(\mathsf {stop}\) in between Line 2 and Line 8 of Algorithm 11.
-
2.
\({\textsf {S}}\) first opens the envelope \({\mathsf {env}}\) to receive all the blinding factors. Recall that \({\textsf {S}}\) has received blinded s-tag \({\mathsf {bstag}}\) and blinded cross-search trapdoors \(\{{\mathsf {bxtoken}}[1],{\mathsf {bxtoken}}[2],\ldots \}\), respectively, where each \({\mathsf {bxtoken}}[c]=({\mathsf {bxtoken}}[c,2],\ldots ,{\mathsf {bxtoken}}[c,n])\). Note that \({\mathsf {bstag}}\) and \({\mathsf {bxtoken}}[c,j]\) are
 and
and  . \({\textsf {S}}\) removes blinding factors and gets
. \({\textsf {S}}\) removes blinding factors and gets  and
and  , respectively. Now \({\textsf {S}}\) applies secure cross-search technique from [7] to find satisfying identifiers.
, respectively. Now \({\textsf {S}}\) applies secure cross-search technique from [7] to find satisfying identifiers.To put it a little more formally, \({\textsf {S}}\) first uses
 to decrypt \({\mathsf {env}}\) to get the blinding factors \((\rho _1,\ldots ,\rho _n)\) and unblinds \(\mathsf {stag}\) and \(\{\mathsf {xtoken}_j\}_{j\in {[2,n]}}\) from \({\mathsf {bstag}}\) and \(\{{\mathsf {bxtoken}}_j\}_{j\in {[2,n]}}\), respectively. Then, \({\mathsf {DO}}\) retrieves all \((e_{c},y_{c})\) with respect to
to decrypt \({\mathsf {env}}\) to get the blinding factors \((\rho _1,\ldots ,\rho _n)\) and unblinds \(\mathsf {stag}\) and \(\{\mathsf {xtoken}_j\}_{j\in {[2,n]}}\) from \({\mathsf {bstag}}\) and \(\{{\mathsf {bxtoken}}_j\}_{j\in {[2,n]}}\), respectively. Then, \({\mathsf {DO}}\) retrieves all \((e_{c},y_{c})\) with respect to 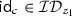 by applying \(\mathsf {stag}\) on \(\mathscr {D}\) (in Lines 4 and 5). Then, \({\mathsf {DO}}\) checks if the file identifier ‘\(\mathsf {id}_c\) contains
by applying \(\mathsf {stag}\) on \(\mathscr {D}\) (in Lines 4 and 5). Then, \({\mathsf {DO}}\) checks if the file identifier ‘\(\mathsf {id}_c\) contains  ’ using \(\mathsf {xtoken}_\alpha \) where \(\alpha \in [2,n]\). Based on these membership tests, \({\mathsf {DO}}\) evaluates \(\varPhi \). In case \(\varPhi \) is satisfied, \({\mathsf {DO}}\) outputs \(e_{c}\) (i.e., encrypted \(\mathsf {id}_c\)).
’ using \(\mathsf {xtoken}_\alpha \) where \(\alpha \in [2,n]\). Based on these membership tests, \({\mathsf {DO}}\) evaluates \(\varPhi \). In case \(\varPhi \) is satisfied, \({\mathsf {DO}}\) outputs \(e_{c}\) (i.e., encrypted \(\mathsf {id}_c\)). -
3.
Finally, \({\textsf {C}}\) decrypts \(e_{c}\) using \({\mathsf {strap}}\) and gets back keyword \(\mathsf {id}\in {{\mathcal {ID}}}(={\mathcal {W}})\) that satisfied the formula
 .
.
 and
and  .
.  and
and  , respectively. Now
, respectively. Now  to decrypt
to decrypt 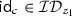 by applying
by applying  ’ using
’ using  .
.
The above three algorithms (Algorithms 9 to 11) define \({\mathsf {3P}}-{\mathsf {OXT}}\) completely. Note that the only difference our version of \({\mathsf {3P}}-{\mathsf {OXT}}\) has over the \(\mathsf {OSPIR}-\mathsf {OXT}\) [21, Appendix B] is that we use dictionary \(\mathscr {D}\) unlike array \({\mathsf {TSet}}\) used over there, since dictionary gives compact representation of a collection and therefore gives better space efficiency than array \({\mathsf {TSet}}\). However, a natural question arises here if such a replacement is secure. Informally speaking, such a change does not hamper the security of \({\mathsf {3P}}-{\mathsf {OXT}}\) as before storing the data in the dictionary, a hash function is evaluated which in the security proof will be modeled as random oracle. Nonetheless, the proof of \({\mathsf {3P}}-{\mathsf {OXT}}\) basically follows from the proof of \({\mathsf {OSPIR}}-{\mathsf {OXT}}\) [21].
1.2 Leakage functions for \(\mathsf {\Pi }_{{\mathsf {OXT}}}\)
The \(\mathsf {\Pi }_{{\mathsf {OXT}}}\) protocol, as presented in Sect. 5.2.4, takes \({\mathcal {W}}\) as input and converts it into another dataset \({\mathsf{kDB}}\). On a query on queryword \({\omega }^*\), the protocol converts it into formula  where
where  denotes the input wires for \(\varPhi \). The leakage of \(\mathsf {\Pi }_{{\mathsf {OXT}}}\) is described in terms of \({\mathsf{kDB}}\) and
denotes the input wires for \(\varPhi \). The leakage of \(\mathsf {\Pi }_{{\mathsf {OXT}}}\) is described in terms of \({\mathsf{kDB}}\) and  below.
below.
1.2.1 Leakage to \({\mathsf {S}}\) (\({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{\textsf {S}}=({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {S}},\mathsf {Setup}}, {\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {S}},\mathsf {Search}})\)).
Here, \({\mathcal {L}}_{{\textsf {S}},\mathsf {Setup}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}({\mathcal {W}})=\mathscr {b}\) and \({\mathcal {L}}_{{\textsf {S}},\mathsf {Search}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}({\mathcal {W}}, {\omega }^*)=(\mathscr {b}, {\bar{s}}|_\ell , {\text {SP}}|_\ell , {\text {RP}}|_\ell ,\) \({\text {XT}}|_\ell ,{\text {IP}}|_\ell )\) where
-
\(\mathscr {b}=\underset{i\in [\mathscr {d}]}{\sum } |{\mathcal {Z}}_{{ i }}|\).
-
\({\bar{s}}|_\ell \in [\mathscr {m}]^\ell \) is the s-term equality pattern of \(\mathbf{s }|_\ell \in {\mathcal {Z}}_{{ }}^{\ell }\). If two formulas have same s-term, corresponding components in \({\bar{s}}\) will have same value.
-
\({\text {SP}}|_\ell \in [\mathscr {d}]^\ell \) is the s-term cardinality list where \({\text {SP}}_i=|{\mathsf{kDB}}(s_i)|\). Here, essentially \(\left|{{\mathcal {ID}}}_{s_i} \right|\) is stored in \({\text {SP}}_i\) where \(i\in [Q]\).
-
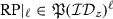 is the intermediate results pattern where \({\text {RP}}_{i,\alpha }={\mathsf{kDB}}(s_i)\cap {\mathsf{kDB}}(x_{i,\alpha })\). Recall, OXT-based protocols find \(\mathsf {id}\in {{\mathcal {ID}}}_{s_i}\cap {{\mathcal {ID}}}_{x_{i,\alpha }}\). Here, such information is stored in \({\text {RP}}_i\) for all \(i\in [Q]\).
is the intermediate results pattern where \({\text {RP}}_{i,\alpha }={\mathsf{kDB}}(s_i)\cap {\mathsf{kDB}}(x_{i,\alpha })\). Recall, OXT-based protocols find \(\mathsf {id}\in {{\mathcal {ID}}}_{s_i}\cap {{\mathcal {ID}}}_{x_{i,\alpha }}\). Here, such information is stored in \({\text {RP}}_i\) for all \(i\in [Q]\). -
\({\text {XT}}|_\ell =(n_1, n_2,\ldots , n_\ell )\) where \({\text {XT}}_i=|\mathbf{x }_i|\). This contains information of number of cross-tag searches that are needed for any ith query.
-
\({\text {IP}}|_{\ell }\) is a \((\ell \times n)\times (\ell \times n)\) table where \(n=\underset{i\in \ell }{max} ({\text {XT}}_i)\). This contains information of \(\mathsf {id}\)-s that satisfy s-terms of any two different queries if these queries \({\omega }^*_i\) and \({\omega }^*_j\) share some x-terms. This is called the intersection pattern and is realized by a four-dimensional array.
$$\begin{aligned}&{\text {IP}}[(i,\alpha ),(j,\beta )]\\&\quad =\left\{ \begin{array}{ll} {\mathsf{kDB}}(s_i)\cap {\mathsf{kDB}}(s_j) &{} \quad \text{ if } i\ne j \text{ and } x_{i,\alpha }=x_{j,\beta } \\ \phi &{} \quad \text{ otherwise }\\ \end{array} \right. \end{aligned}$$
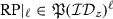 is the intermediate results pattern where
is the intermediate results pattern where 1.2.2 Leakage to \({\textsf {C}}\) (\({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{\textsf {C}}=({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {C}},\mathsf {Setup}}, {\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {C}},\mathsf {Search}})\)).
Here, \({\mathcal {L}}_{{\textsf {C}},\mathsf {Setup}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}({\mathcal {W}})=\left|{\mathcal {Z}} \right|\), \({\mathcal {L}}_{{\textsf {C}},\mathsf {Search}_1}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}({\omega }^*)=\bot \),  where
where  . Note that \({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {C}},\mathsf {Search}_1}\) and \({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {C}},\mathsf {Search}_2}\) denote the leakage to \({\textsf {C}}\) in \(\mathsf {GenTrapdoor}\) and \(\mathsf {Search}\) protocols, respectively.
. Note that \({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {C}},\mathsf {Search}_1}\) and \({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {C}},\mathsf {Search}_2}\) denote the leakage to \({\textsf {C}}\) in \(\mathsf {GenTrapdoor}\) and \(\mathsf {Search}\) protocols, respectively.
1.2.3 Leakage to \({\textsf {DO}}\) (\({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{\textsf {S}}=({\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {DO}},\mathsf {Setup}}, {\mathcal {L}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}_{{\textsf {DO}},\mathsf {Search}})\)).
Here, \({\mathcal {L}}_{{\mathsf {DO}},\mathsf {Setup}}^{\mathsf {\Pi }_{{\mathsf {OXT}}}}({\mathcal {W}})=\bot \) and  , where
, where  is a function of
is a function of  that is given to \({\mathsf {DO}}\) during search.
that is given to \({\mathsf {DO}}\) during search.
Blind Seer protocol
The Blind Seer protocol involves three parties: the data owner \({\mathsf {DO}}\), the server \({\mathsf {S}}\) and the clients (end users) \({\mathsf {C}}\). \({\mathsf {DO}}\), who owns the database \({\mathsf {DB}}\), encrypts the database and outsources it to \({\mathsf {S}}\). The construction consists of two phases, \(\mathsf {Setup}\) and \({\mathsf{Search}}\), which are described next.
\(\mathsf {Setup}\) In this phase, \({\mathsf {DO}}\) permutes \({\mathsf {DB}}\), encrypts it and constructs the Bloom filter search tree. The encrypted database and search tree are sent to \({\mathsf {S}}\). \({\mathsf {S}}\), then blinds the record decryption keys and sends it to \({\mathsf {DO}}\), so that \({\mathsf {DO}}\) doesn’t learn the search results.
-
Input: (\({\mathsf {DB}}\);\(\bot \);\(\bot \))
-
Output: \(({\mathsf {st}}_{{\mathsf {{\mathsf {DO}}}}};{\mathsf {st}}_{{\mathsf {{\mathsf {C}}}}};{\mathsf {st}}_{{\mathsf {{\mathsf {S}}}}})\), where \({\mathsf {st}}_{{\mathsf {{\mathsf {DO}}}}}\) comprises of the set of blinded permuted keys \(\{{\tilde{s}}_{i}'\}_{i \in [n_{r}]}\), \({\mathsf {st}}_{{\mathsf {{\mathsf {C}}}}}\) comprises of the \(\mathsf {PRF}\) key \(k\) and the hash functions used in the Bloom filter construction, and \({\mathsf {st}}_{{\mathsf {{\mathsf {S}}}}}\) comprises of the encrypted database \(\mathsf{EDB}\).
-
1.
The data owner \({\mathsf {DO}}\) generates a key pair \((\mathsf {pk},\mathsf{sk})\) for a public key semi-homomorphic (e.g., additively homomorphic) encryption scheme \(({\mathsf{Gen}},\mathsf{Enc},\mathsf{Dec})\). Given a database of \(n_{r}\) records, \({\mathsf {DO}}\) randomly shuffles the database and obtains the shuffled database \((R_1,\dots , R_{n_{r}})\). To encrypt the database, for each record \(R_i\), \({\mathsf {DO}}\) picks a random string \(s_i\), computes \({\tilde{s}}_i \leftarrow \mathsf{Enc}_\mathsf {pk}(s_i)\) and sets \({\tilde{R}}_i=G(s_i) \oplus R_i\), where \(G\) is a PRG.
-
2.
\({\mathsf {DO}}\) constructs a Bloom filter search tree corresponding to the permuted records \((R_1,\dots , R_{n_{r}})\). It then samples a key \(k\) at random for a \(\mathsf {PRF}\) \(F\). It encrypts the Bloom filter \({\mathcal {B}}_v\) corresponding to each node v as follows: \({\tilde{{\mathcal {B}}}}_v:={\mathcal {B}}_v \oplus F_{k}(v)\). Let \(\mathsf {T}\) denote the encrypted Bloom filter search tree.
-
3.
At the end, \({\mathsf {DO}}\) sends \(\mathsf{EDB}\) consisting of the encrypted database of records \((\mathsf {pk},({\tilde{s}}_1,{\tilde{R}}_1),\dots ,({\tilde{s}}_{n_{r}},{\tilde{R}}_{n_{r}}))\) and the encrypted search tree to the server \({\mathsf {S}}\). The client \({\mathsf {C}}\) receives the key \(k\) of \(\mathsf {PRF}\) \(F\) and the keyed hash functions used in the Bloom filter construction.
-
4.
The server \({\mathsf {S}}\) picks a random permutation \(\pi : [n_{r}]\rightarrow [n_{r}]\). For each \(i\in [n_{r}]\), it randomly chooses \(r_i\) and computes \({\tilde{s}}_{\pi (i)}'\leftarrow {\tilde{s}}_i\cdot \mathsf{Enc}_{\mathsf {pk}}(r_i)\). It sends \(({\tilde{s}}_1',\dots ,{\tilde{s}}_{n_{r}}')\) to \({\mathsf {DO}}\). Then, \({\mathsf {DO}}\) decrypts each \({\tilde{s}}_{i}'\) to obtain the blinded key \(s_i'\).
Search In this phase, the client and the server will run a secure function evaluation protocol to traverse \(\mathsf {T}\). At the end, the client obtains the expected encrypted records for the search query \(\mathsf {q}\). Then, the client gets the corresponding secret key from the data owner and decrypts the records to obtain the final output.
-
Input: \(({\mathsf {st}}_{{\mathsf {{\mathsf {DO}}}}};\mathsf {q},{\mathsf {st}}_{{\mathsf {{\mathsf {C}}}}};{\mathsf {st}}_{{\mathsf {{\mathsf {S}}}}})\)
-
Output: \((\bot ;{\mathsf {Res}};\bot )\), where \({\mathsf {Res}}\) denotes the set of records that satisfy query \(\mathsf {q}\).
-
1.
Starting from the root of \(\mathsf {T}\), \({\mathsf {C}}\) constructs a query garbled circuit corresponding to the given boolean query \(\varPhi \). Then, \({\mathsf {C}}\) and \({\mathsf {S}}\) run the circuit to check whether it contains the query keywords. If so, both parties run the secure function evaluation for its all children. For a search query \(\mathsf {q}\), as \({\mathsf {C}}\) has the hash functions used to construct the Bloom filter, it first identifies the positions in the Bloom filter \({\mathcal {B}}_{v}\) that need to be checked for a node v and communicates them to \({\mathsf {S}}\). Note that \({\mathsf {S}}\) has an encrypted Bloom filter \({\tilde{{\mathcal {B}}}}_{v}={\mathcal {B}}_v \oplus F_{k}(v)\) and \({\mathsf {C}}\) has the \(\mathsf {PRF}\) key \(\mathsf{k}\). Hence, \({\mathsf {C}}\) and \({\mathsf {S}}\) can perform a secure function evaluation protocol, where the input of \({\mathsf {C}}\) is the bits at the positions to be checked of \(F_{k}(v)\) and the input of \({\mathsf {S}}\) is bits at the positions to be checked of \(\tilde{{\mathcal {B}}_{v}}\).
-
2.
If the search reaches the leaf node i, \({\mathsf {S}}\) returns \((\pi (i), r_i , {\tilde{R}}_i )\) to \({\mathsf {C}}\).
-
3.
\({\mathsf {C}}\) sends \(\pi (i)\) to \({\mathsf {DO}}\) and \({\mathsf {DO}}\) returns \(s_{\pi (i)}'\). Since \(s_{\pi (i)}'=s_i\cdot r_i\) and \({\mathsf {C}}\) receives \(r_{i}\) from \({\mathsf {S}}\), it can compute \(s_i\) and decrypt \({\tilde{R}}_i\) to obtain the plain record.
Instantiation of \(\mathsf {PRF}\) in Blind Seer protocol Here, we begin with a discussion on why instantiating the \(\mathsf {PRF}\) \(F\) naively in Blind Seer protocol leads to linear computation time in certain cases. Next, we propose a remedy to overcome this issue. First, let us describe how the length of Bloom filter in BF Tree is determined in [32]. The length \(\ell _{v}\) of Bloom filter \({\mathcal {B}}_v\) is determined by the upper bound of the number of possible keywords, derived from \({\mathsf {DB}}\) schema, so that two nodes of the same level in the search tree have an equal-length Bloom filters. For example, consider attribute ‘Gender’ in the database, which has very few possible values. Each Bloom filter in the bottom layer of the tree (leaves) will store one of the few possible values. However, their parent nodes need not keep space for \(d\) items, where \(d\) is the branching factor. In fact, we only need to keep space for the minimum between cardinality of the field and the number of leaf nodes of the current subtree. Here, the cardinality of the ‘Gender’ field would usually be the minimum of the two.
Now, let us consider an attribute which can take values from a large universe, e.g., salary. Therefore, for a node v at level \(\mathsf {L}\), the minimum between the cardinality of the field salary and the number of leaf nodes of the current subtree is usually the number of leaf nodes of the current subtree. For the root of Bloom filter tree, this value is \(n_{r}\), where \(n_{r}\) denotes the number of records in the database. Therefore, the length of the Bloom filter corresponding to root node is \(O(n_{r})\).
In the protocol, \({\mathsf {C}}\) needs to determine certain bits of the output of \(\mathsf {PRF}\) \(F\) which is used as input to the garbled circuit. If the Blind Seer protocol is naively instantiated with an arbitrary \(\mathsf {PRF}\) \(F\), \({\mathsf {C}}\) needs to compute a \(\mathsf {PRF}\) of output size \(O(n_{r})\). Therefore, it defeats the goal of achieving sub-linear time complexity.
We need to instantiate Blind Seer protocol with a \(\mathsf {PRF}\) \(F\) that allows \({\mathsf {C}}\) to determine certain bits, say c bits of the output of \(\mathsf {PRF}\) \(F\) through \(O(\lambda c)\) computation. One way to instantiate \(\mathsf {PRF}\) \(F\) is to use a base \(\mathsf {PRF}\) \(F_{0}\) as described below:
Here, \(x_{\mathsf {trunc}(t)}\) denotes string x is truncated to t bits; if \(t < |x|\), else it is left unchanged. It is easy to see that if \(F_{0}\) is secure, then \(F\) is secure. Now, we can determine bit at position i by just computing \(F_{0}\) at necessary counter value.
1.1 Leakage functions for \(\mathsf {\Pi }_{{\mathsf {BS}}}\)
The protocol \(\mathsf {\Pi }_{{\mathsf {BS}}}\) is essentially the Blind Seer protocol instantiated on the output of \(\mathsf {GenkDB}_{\mathsf {\Pi }_{{\mathsf {BS}}}}\) and \(\mathsf {GenFormula}_{\mathsf {\Pi }_{{\mathsf {BS}}}}\). Hence, the leakage profile of \(\mathsf {\Pi }_{{\mathsf {BS}}}\) is analogous to the leakage profile of Blind Seer protocol which is described below.
Leakage in \(\mathsf {Setup}\) (\({\mathcal {L}}_{{\mathsf {DO,Setup}}}^{\mathsf {\Pi }_{{\mathsf {BS}}}}({\mathcal {W}}),{\mathcal {L}}_{{\mathsf {C,Setup}}}^{\mathsf {\Pi }_{{\mathsf {BS}}}}({\mathcal {W}}),{\mathcal {L}}_{{\mathsf {S,Setup}}}^{\mathsf {\Pi }_{{\mathsf {BS}}}}({\mathcal {W}})\) ). Since the data owner has all input, there is no leakage to \({\mathsf {DO}}\). The common leakage to \({\mathsf {S}}\) and \({\mathsf {C}}\) is the total number of keywords in the database, i.e., \(n_{k}\). The additional leakage to \({\mathsf {S}}\) is the length of each keyword in the database.
Leakage to \({\mathsf {DO}}\) in each \({\mathsf{Search}}\) query (\({\mathcal {L}}_{{\mathsf {DO,Search}}}^{\mathsf {\Pi }_{{\mathsf {BS}}}}({\mathcal {W}},{\omega }^*)\)). \({\mathsf {DO}}\) is involved when a matched keyword is retrieved. Let \(((i_1,{\omega }_{i_1}),\dots ,(i_j,{\omega }_{i_j}))\) be the query results. Then, the leakage to \({\mathsf {DO}}\) is \((\pi (i_1),\dots ,\pi (i_j))\).
Leakage to \({\mathsf {C}}\) in each \({\mathsf{Search}}\) query (\({\mathcal {L}}_{{\mathsf {C,Search}}}^{\mathsf {\Pi }_{{\mathsf {BS}}}}({\mathcal {W}},{\omega }^*)\)). The leakage to \({\mathsf {C}}\) is the Bloom filter tree traversal paths, i.e., all the nodes v in which the query passes according to the filter \({\mathcal {B}}_v\).
Leakage to \({\mathsf {S}}\) in each \({\mathsf{Search}}\) query (\({\mathcal {L}}_{{\mathsf {S,Search}}}^{\mathsf {\Pi }_{{\mathsf {BS}}}}({\mathcal {W}},{\omega }^*)\)). In addition to what is leaked to \({\mathsf {C}}\) in the \({\mathsf{Search}}\) protocol, the server learns the topology of the query circuit. The server also learns the Bloom filter indices (although not the content), but assuming that the hash functions are modeled as random oracle, those indices reveal very little information about the query. Based on the above leakage, after multiple queries, the server can infer correlations among \({\mathsf {C}}\)’s queries.
Rights and permissions
About this article

Cite this article
Chatterjee, S., Kesarwani, M., Modi, J. et al. Secure and efficient wildcard search over encrypted data. Int. J. Inf. Secur. 20, 199–244 (2021). https://doi.org/10.1007/s10207-020-00492-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10207-020-00492-w