
Abstract
In last decades, Bioinformatics has become an emerging field of science with a wide variety of applications in many research areas. The primary goal of bioinformatics is to detect useful biological knowledge hidden under the large volumes of DNA/RNA sequences and structures, literature and other biological and biomedical data, to gain a greater insight into their relationships and, therefore, to enhance the discovery and the comprehension of biological processes. In order to fully exploit the new opportunities that emerge, novel data and text mining techniques have to be developed to effectively address the fundamental biological issue of managing and uncovering meaningful patterns and correlations from these large biological and biomedical data repositories. In this work, we propose an effective data mining technique for analysing biological and biomedical data. The proposed mining process is efficient enough to be applied to various types of biological and biomedical data. To prove the concept, we experiment with applying the data mining technique into two distinct areas, including biomedical text documents and data. In addition, based on the proposed approach, we develop two mining tools, namely the Bio Search Engine and the Genome-Based Population Clustering.








Similar content being viewed by others


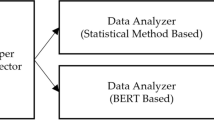
Notes
Available at: ftp://ftp.cs.cornell.edu/pub/smart.
References
Ananiadou S, Mcnaught J (2006) Text mining for biology and biomedicine. Artech House, London
Baeza-Yates R, Ribeiro-Neto B (2011) Modern information retrieval: the concepts and technology behind search, 2nd edn. ACM Press, New York
Berry MW, Dumais ST, O’Brien GW (1995) Using linear algebra for intelligent information retrieval. SIAM Rev 37(4):573–595
Boisclair C (2008) Developing a tokenizer and morphological parser for English text in C#. In: Proceedings of the 46th annual southeast regional conference, Auburn, Alabama, USA. ACM, pp 288–293
Chen B, Harrison R, Pan Y, Tai P (2005) Novel Hybrid hierarchical-K-means clustering method (H-K-means) for microarray analysis. In: Proceedings of the (2005) IEEE computational systems bioinformatics conference—workshops (CSBW ’05). IEEE Computer Society, Washington, DC, USA, pp 105–108
Cohen AM, Herch WR (2005) A survey of current work in biomedical text mining. Brief Bioinform 6(1):57–71. doi:10.1093/bib/6.1.57
Dai HJ, Lin JYW, Huang CH, Chou PH, Tsai RTH, Hsu WL (2008) A survey of state of the art biomedical text mining techniques for semantic analysis. In: Proceedings of the IEEE international conference on sensor networks, ubiquitous and trustworthy computing (SUTC ’08), pp 410–417
Deerwester SC, Dumais ST, Landauer TK, Furnas GW, Harshman RA (1990) Indexing by latent semantic analysis. J Am Soc Inf Sci 41(6):391–407
Dhillon IS, Guan Y, Kogan J (2002) Iterative clustering of high dimensional text data augmented by local search. In: Proceedings of the 2002 IEEE international conference on data mining, pp 131–138
Georgara D, Kermanidis K, Mariolis I (2012), Support vector machine classification of protein sequences to functional families based on motif selection. In: Proceedings of the 8th artificial intelligence applications and innovations conference (AIAI 2012), pp 28–36
Georgitsi M, Viennas E, Gkantouna V, Christodoulopoulou E, Zagoriti Z, Tafrali C, Ntellos F, Giannakopoulou O, Boulakou A, Vlahopoulou P, Kyriacou E, Tsaknakis J, Tsakalidis A, Poulas K, Tzimas G, Patrinos GP (2011a) Population-specific documentation of pharmacogenomic markers and their allelic frequencies in FINDbase. Pharmacogenomics 12(1):49–58. doi:10.2217/pgs.10.169
Georgitsi M, Viennas E, Gkantouna V, van Baal S, Petricoin EF, Poulas K, Tzimas G, Patrinos GP (2011b) FINDbase: a worldwide database for genetic variation allele frequencies updated. Nucleic Acids Res 39:D926–D932
Guyon I, Weston J, Barnhill S, Vapnik V (2002) Gene selection for cancer classification using support vector machines. Mach Learn 4:389–422
Han J, Kamber M (2006) Data mining: concepts and techniques, 2nd edn. Morgan Kaufmann Publishers, San Francisco
Ioannou M, Makris C, Tzimas G, Viennas E (2011) A text mining approach for biomedical documents. In: Proceedings of the 6th conference of the Hellenic Society for computational biology and bioinformatics (HSCBB11), Patras, Greece
Ioannou M, Patrinos G, Tzimas G (2012) Genome-based population clustering: Nuggets of truth buried in a pile of numbers? In: Proceedings of the 1st workshop on algorithms for data and text mining in bioinformatics (WADTMB (2012) organized in the 8th artificial intelligence applications and innovations conference (AIAI 2012), September 27–30, 2012. Halkidiki, Greece
Inoue K, Urahama K (2001) Fuzzy clustering based on cooccurence matrix and its application to data retrieval. Electron Commun Jpn Pt. II 84(8):10–19. doi:10.1002/ecjb.1045
Karypis G, Han EH (2000) Fast supervised dimensionality reduction algorithm with applications to document categorization and retrieval. In: Proceedings of the 9th ACM international conference on information and, knowledge management, pp 12–19
Kogan J (2007) Introduction to clustering large and high-dimensional data. Cambridge University Press, New York
Lu Z (2011) Pubmed and beyond: a survey of web tools for searching biomedical literature. Database (Oxford). doi:10.1093/database/baq036
Manconi A, Vargiu E, Armano G, Milanesi L (2012) Literature retrieval and mining in bioinformatics: state of the art and challenges. Adv Bioinform 2012:573846. doi:10.1155/2012/573846
Papadimitriou CH, Tamaki H, Raghavan P, Vempala S (1998) Latent semantic indexing: a probabilistic analysis. In: Proceedings of the 17th ACM SIGACT-SIGMOD-SIGART symposium on principles of database systems. ACM Press, New York, pp 159–168
Steinbach M, Karypis G, Kumar V (2000) A comparison of document clustering techniques. In: Proceedings of the KDD workshop on text mining, 6th ACM SIGKDD international conference on data mining (KDD’00)
Van Baal S, Kaimakis P, Phommarinh M, Koumbi D, Cuppens H, Riccardino F, Macek M Jr, Scriver CR, Patrinos GP (2007) FINDbase: a relational database recording frequencies of genetic defects leading to inherited disorders worldwide. Nucleic Acids Res 35(Database issue):D690–D695
Viennas E, Gkantouna V, Ioannou M, Georgitsi M, Rigou M, Poulas K, Patrinos GP, Tzimas G (2012) Population-ethnic group specific genome variation allele frequency data: a querying and visualization journey. Genomics 100(2):93–101. doi:10.1016/j.ygeno.2012.05.009
Wang JTL, Zaki MJ, Toivonen HTT, Shasha D (2005) Data mining in bioinformatics. In: Wang JTL, Zaki MJ, Toivonen HTT, Shasha D (eds) Advanced information and knowledge processing, Springer-Verlag, London, UK
Wang W, Wang H, Dai G, Wang H (2006) Visualization of large hierarchical data by circle packing. In: Proceedings of the SIGCHI conference on human factors in computing systems, pp 517–520
Zhang C, Xia S (2009) K-means clustering algorithm with improved initial center, knowledge discovery and data mining, 2009. WKDD 2009, pp 790–792. doi:10.1109/WKDD.2009.210
Zhang T, Ramakrishnan R, Livny M (1996) BIRCH: an efficient data clustering method for very large databases. In: Proceedings of the 1996 ACM SIGMOD international conference on management of data, June 04–06, 1996. Montreal, Quebec, Canada, pp 103–114. doi:10.1145/235968.233324
Zhang T, Ramakrishnan R, Livny M (1997) BIRCH: a new data clustering algorithm and its aApplications. J Data Min Knowl Discov 1(2):141–182
Author information
Authors and Affiliations
Corresponding author
Additional information
Author names appear in alphabetical order.
Rights and permissions
About this article
Cite this article
Ioannou, ZM., Makris, C., Patrinos, G.P. et al. A set of novel mining tools for efficient biological knowledge discovery. Artif Intell Rev 42, 461–478 (2014). https://doi.org/10.1007/s10462-013-9413-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10462-013-9413-z