
Abstract
Researchers and practitioners who use databases usually feel that it is cumbersome in knowledge discovery or application development due to the issue of missing data. Though some approaches can work with a certain rate of incomplete data, a large portion of them demands high data quality with completeness. Therefore, a great number of strategies have been designed to process missingness particularly in the way of imputation. Single imputation methods initially succeeded in predicting the missing values for specific types of distributions. Yet, the multiple imputation algorithms have maintained prevalent because of the further promotion of validity by minimizing the bias iteratively and less requirement on prior knowledge to the distributions.
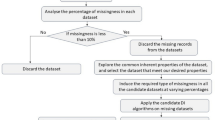
This article carefully reviews the state of the art and proposes a hybrid missing data completion method named Multiple Imputation using Gray-system-theory and Entropy based on Clustering (MIGEC). Firstly, the non-missing data instances are separated into several clusters. Then, the imputed value is obtained after multiple calculations by utilizing the information entropy of the proximal category for each incomplete instance in terms of the similarity metric based on Gray System Theory (GST).
Experimental results on University of California Irvine (UCI) datasets illustrate the superiority of MIGEC to other current achievements on accuracy for either numeric or categorical attributes under different missing mechanisms. Further discussion on real aerospace datasets states MIGEC is also applicable for the specific area with both more precise inference and faster convergence than other multiple imputation methods in general.




Similar content being viewed by others


References
Al-Harbi SH, Rayward-Smith VJ (2006) Adapting k-means for supervised clustering. Appl Intell 24(3):219–226
Ahn KW, Chan K-S (2010) Efficient Markov chain Monte Carlo with incomplete multinomial data. Stat Comput 20(4):447–456
Allison PD (2001) Missing data. Sage university papers series on quantitative applications in the social sciences. Sage, Thousand Oaks
Bache K, Lichman M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science
Baraldi AN, Enders CK (2010) An introduction to modern missing data analyses. J Sch Psychol 48(1):5–37
Bezdek JC, Keller J, Krishnapuram R, Pal NR (1999) Fuzzy models and algorithms for pattern recognition and image processing. In: Dubois D, Prade H (eds) The handbooks of fuzzy sets series. Kluwer Academic, Boston/London/Dordrecht
Biba M, Ferilli S, Esposito F (2011) Boosting learning and inference in Markov logic through metaheuristics. Appl Intell 34(2):279–298
Bose S, Das C, Dutta S, Chattopadhyay S (2012) A novel interpolation based missing value estimation method to predict missing values in microarray gene expression data. In: Proceedings of 2012 international conference on communications, devices and intelligent systems (CODIS), pp 318–321
Bras LP, Menezes JC (2007) Improving cluster-based missing value estimation of DNA microarray data. Biomol Eng 24:273–282
Calle J, Castaño L, Castro E, Cuadra D (2013) Statistical user model supported by R-tree structure. Appl Intell. doi:10.1007/s10489-013-0432-x
Chen SM, Chen HH (2000) Estimating null values in the distributed relational databases environments. Cybern Syst 31(8):851–871
Chen SM, Huang CM (2003) Generating weighted fuzzy rules from relational database systems for estimating null values using genetic algorithms. IEEE Trans Fuzzy Syst 11(4):495–506
Deng JL (1982) Control problems of grey system. Syst Control Lett 1:288–294
Deng JL (1988) Properties of relational space for grey system. In: Deng JL (ed) Essential topics on grey system theory and applications. China Ocean, Beijing, pp 1–13
Di Nuovo AG (2011) Missing data analysis with fuzzy C-means: a study of its application in a psychological scenario. Expert Syst Appl 38(6):6793–6797
Di Zio M, Guarnera U (2009) Semiparametric predictive mean matching. AStA Adv Stat Anal 93(2):175–186
Di Zio M, Guarnera U, Luzi O (2007) Imputation through finite Gaussian mixture models. Comput Stat Data Anal 51(11):5305–5316
Donders AR, van der Heijden GJ, Stijnen T, Moons KG (2006) Review: a gentle introduction to imputation of missing values. J Clin Epidemiol 59(10):1087–1091
Enders CK (2010) Applied missing data analysis. Guilford Press, New York
Enders C, Dietz S, Montague M, Dixon J (2006) Modern alternatives for dealing with missing data in special education research. Adv Learn Behav Disabil 19:101–129
Farhangfar A, Kurgan L, Pedrycz W (2004) Experimental analysis of methods for imputation of missing values in databases. In: Intelligent computing: theory and applications II, Orlando, Florida, 12 April 2004. Proceedings of SPIE, vol 5421. SPIE Press, Bellingham, pp 172–182
García-Laencina PJ, Sancho-Gomez J-L, Figueiras-Vidal AR, Verleysen M (2009) K nearest neighbours with mutual information for simultaneous classification and missing data imputation. Neurocomputing 72(7–9):1483–1493
García JCF, Kalenatic D, Bello CAL (2011) Missing data imputation in multivariate data by evolutionary algorithms. Comput Hum Behav 27:1468–1474
González S, Rueda M, Arcos A (2008) An improved estimator to analyse missing data. Stat Pap 49(4):791–796
Hathaway R, Bezdek J (2001) Fuzzy C-means clustering of incomplete data. IEEE Trans Syst Man Cybern, Part B, Cybern 31(5):735–744
Hruschka ER Jr., Hruschka ER, Ebecken NFF (2011) A Bayesian imputation method for a clustering genetic algorithm. J Comput Methods Sci Eng 11(4):173–183
Huang CC, Lee HM (2004) A grey-based nearest neighbor approach for missing attribute value prediction. Appl Intell 20(3):239–252
Huang CC, Lee HM (2006) An instance-based learning approach based on grey relational structure. Appl Intell 25(3):243–251
Jaynes ET (1957) Information theory and statistical mechanics. Phys Rev 106(4):620–630
Junninen H, Niska H, Tuppurainen K, Ruuskanen J, Kolehmainen M (2004) Methods for imputation of missing values in air quality data sets. Atmos Environ 38(18):2895–2907
Kim KY, Kim BJ, Yi GS (2004) Reuse of imputed data in microarray analysis increases imputation efficiency. BMC Bioinform. doi:10.1186/1471-2105-5-160
Lakshminarayan K, Harp SA, Samad T (1999) Imputation of missing data in industrial databases. Appl Intell 11(3):259–275
Li D, Gu H, Zhang L (2010) A fuzzy C-means clustering algorithm based on nearest-neighbor intervals for incomplete data. Expert Syst Appl 37:6942–6947
Li D, Deogun J, Spaulding W, Shuart B (2004) Towards missing data imputation: a study of fuzzy k-means clustering method. In: Rough sets and current trends in computing. Lecture notes in computer science, vol 3066. Springer, Berlin, pp 573–579
Little RJA, Rubin DB (2002) Statistical analysis with missing data, 2nd edn. Wiley, New York
Liu XH (1999) Progress in intelligent data analysis. Appl Intell 11(3):235–240
Lubinsky D (1994) Classification trees with bivariate splits. Appl Intell 4(3):283–296
Magnani M (2004) Techniques for dealing with missing data in knowledge discovery tasks. http://magnanim.web.cs.unibo.it/index.html
McLachlan GJ, Do KA, Ambroise C (2004) Analyzing microarray gene expression data. Wiley, New York
Muñoz JF, Rueda M (2009) New imputation methods for missing data using quantiles. J Comput Appl Math 232(2):305–317
On BW, Lee I (2011) Meta similarity. Appl Intell 35(3):359–374
Pan M (2011) Based on kernel function and non-parametric multiple imputation algorithm to solve the problem of missing data. In: Proceedings of international conference on management science and industrial engineering (MSIE), pp 905–909
Parveen S, Green P (2004) Speech enhancement with missing data techniques using recurrent neural networks. In: Proceedings of the IEEE international conference on acoustics, speech, and signal processing (ICASSP ’04), vol 1, pp 733–738
Peng CJ, Zhu J (2008) Comparison of two approaches for handling missing covariates in logistic regression. Educ Psychol Meas 68(1):58–77
Posner MA, Ash AS, Freund KM, Moskowitz MA, Shwartz M (2001) Comparing standard regression, propensity score matching, and instrumental variables methods for determining the influence of mammography on stage of diagnosis. Health Serv Outcomes Res Methodol 2(3–4):279–290
Qin Y, Zhang S, Zhu X, Zhang J, Zhang C (2009) POP algorithm: kernel-based imputation to treat missing values in knowledge discovery from databases. Expert Syst Appl 36(2):2794–2804
Quinlan JR (1986) Induction of decision trees. Mach Learn 1(1):81–106
Rosenbaum PR, Rubin DB (1983) The central role of the propensity score in observational studies for causal effects. Biometrika 70:41–55
Schafer JL (1997) Analysis of incomplete multivariate data. Chapman & Hall/CRC Press, London
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Twala B (2009) An empirical comparison of techniques for handling incomplete data when using decision trees. Appl Artif Intell 23(5):373–405
Yap GE, Tan AH, Pang HH (2008) Explaining inferences in Bayesian networks. Appl Intell 29(3):263–278
Zhang C, Qin Y, Zhu X, Zhang J, Zhang S (2006) Clustering-based missing value imputation for data preprocessing. In: Proceedings of IEEE international conference on industrial informatics, Singapore, 16–18 Aug 2006, pp 1081–1086
Zhang ML, Zhou ZH (2009) Multi-instance clustering with applications to multi-instance prediction. Appl Intell 31(1):47–68
Zhang S (2011) Shell-neighbor method and its application in missing data imputation. Appl Intell 35(1):123–133
Zhang S, Jin Z, Zhu X (2011) Missing data imputation by utilizing information within incomplete instances. J Syst Softw 84(3):452–459
Zhang S, Jin Z, Zhu X, Zhang J (2009) Missing data analysis: a kernel-based multi-imputation approach. In: Transactions on computational science III. Lecture notes in computer science, vol 5300. Springer, Berlin, pp 122–142
Zhang S, Zhang J, Zhu X, Qin Y, Zhang C (2008) Missing value imputation based on data clustering. In: Transactions on computational science I. Lecture notes in computer science, vol 4750, pp 128–138
Zhu B, He C, Liatsis P (2012) A robust missing value imputation method for noisy data. Appl Intell 36(1):61–74
Acknowledgements
This work is supported by Project of the State Key Laboratory of Software Development Environment, Beihang University (SKLSDE-2011ZX-09) and National Natural Science Foundation of China (61003016).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Tian, J., Yu, B., Yu, D. et al. Missing data analyses: a hybrid multiple imputation algorithm using Gray System Theory and entropy based on clustering. Appl Intell 40, 376–388 (2014). https://doi.org/10.1007/s10489-013-0469-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-013-0469-x