
Abstract
Traditional activation functions such as hyperbolic tangent and logistic sigmoid have seen frequent use historically in artificial neural networks. However, nowadays, in practice, they have fallen out of favor, undoubtedly due to the gap in performance observed in recognition and classification tasks when compared to their well-known counterparts such as rectified linear or maxout. In this paper, we introduce a simple, new type of activation function for multilayer feed-forward architectures. Unlike other approaches where new activation functions have been designed by discarding many of the mainstays of traditional activation function design, our proposed function relies on them and therefore shares most of the properties found in traditional activation functions. Nevertheless, our activation function differs from traditional activation functions on two major points: its asymptote and global extremum. Defining a function which enjoys the property of having a global maximum and minimum, turned out to be critical during our design-process since we believe it is one of the main reasons behind the gap observed in performance between traditional activation functions and their recently introduced counterparts. We evaluate the effectiveness of the proposed activation function on four commonly used datasets, namely, MNIST, CIFAR-10, CIFAR-100, and the Pang and Lee’s movie review. Experimental results demonstrate that the proposed function can effectively be applied across various datasets where our accuracy, given the same network topology, is competitive with the state-of-the-art. In particular, the proposed activation function outperforms the state-of-the-art methods on the MNIST dataset.

Similar content being viewed by others

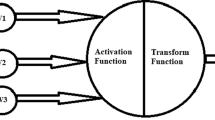
References
Graves A, Bordes A, Mohamed A, Hinton G (2013) Speech recognition with deep recurrent neural network. In: Proceedings of the IEEE international conference on acoustics, speech, and signal processing (ICASSP)
Martens J (2010) Deep learning via Hessian-Free optimization. In: Proceedings of the ICML
Duda RO, Hart PE, Stork DG (2000) Pattern classification, 2nd edn. Wiley, New York
Mandic DP, Goh SL (2009) Complex valued nonlinear adaptive filters: noncircularity, widely linear and neural models, research monograph in the Wiley series in adaptive and learning systems for signal processing, communications, and control. Wiley, New York. ISBN-10: 0470066350
Sibi P, Bordes A, Jones SA, Siddarth P (2013) Analysis of different activation functions using back propagation neural network. J Theor Appl Inf Technol 47(3)
Karlik B, Olgac AV (2011) Performance analysis of various activation functions in generalized MLP architectures of neural networks. IJAE 1(4)
Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY (2011) Reading digits in natural images with unsupervised feature learning. Deep learning and unsupervised feature learning workshop, NIPS
Glorot X, Bordes A, Bengio Y (2011) Deep sparse rectifier neural networks. In: JMLR W&CP: proceedings of the 14th international conference on artificial intelligence and statistics (AISTATS 2011)
Krizhevsky A, Sutskever I, Hinton G (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pp 1106– 1114
Maas AL, Hannun AY, Ng AY (2013) Rectifier nonlinearities improve neural network acoustic models. In: ICML
Goodfellow IJ, Warde-Farley D, Mirza M, Courville A, Bengio Y (2013) Maxout networks. In: Proceedings of the ICML
Srivastava RK, Masci J, Kazerounian S, Gomez F, Schmidhuber J (2013) Compete to compute. In: Advances in neural information processing systems 25 (NIPS’2013)
Chatfield K, Simonyan K, Vedaldi A, Zisserman A (2014) Return of the devil in the details: Delving deep into convolutional nets. arXiv:1405.3531
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Lecun Y, Bottou L, Orr BG, Muller K-R (1998) Efficient BackProp. Lect Notes Comput Sci 1524:9–50
Bergstra J, Breuleux O, Bastien F, Lamblin P, Pascanu R, Desjardins G, Turian J, Warde-Farley D, Bengio Y (2010) Theano: a CPU and GPU math expression compiler. In: Proceedings of the python for scientific (SciPy 2010). Oral Presentation
Bastien F, Lamblin P, Pascanu R, Bergstra J, Goodfellow IJ, Bergeron A, Bouchard N, Bengio Y (2012) Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R (2012) Improving neural networks by preventing co-adaptation of feature detectors. Technical report, arXiv:1207.0580
Srivastava N, et al. (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res (JMLR) 15: 1929–1958
Simard PY, Steinkraus D, Plat JC (2003) Best practices for convolutional neural networks applied to visual document analysis. In: International conference on document analysis and recognition (ICDAR)
Srivastava N (2013) Improving neural networks with dropout. Master’s thesis, U. Toronto
Jarrett K et al (2009) What is the best multi-stage architecture for object recognition?. In: Proceedings international conference on computer vision (ICCV’ 09), pp 2146–2153
Zeiler MD, Fergus R (2013) Stochastic pooling for regularization of deep convolutional neural networks. In: International conference on learning representations
Mairal J, Koniusz P, Harchaoui Z, Schmid C (2015) Convolutional kernel networks. In: Advances in neural information processing systems (NIPS)
Lee C-Y, Xie S, Patrick G, Zhengyou Z, Tu Z (2015) Deeply-Supervised nets. In: Proceedings of the 12th international conference on artificial intelligence and statistics (AISTATS)
Kim Y (2014) Convolutional neural networks for sentence classification. In: Conference on EMNLP, pp 1746–1751
Pang B, Lee L (2005) Seeing stars: exploiting class relationships for sentiment categorization with respect to rating scales. In: Proceedings of ACL, p 2005
Krizhevsky A, Hinton G (2009) Learning multiple layers of features from tiny images. Technical report, University of Toronto
Graham B (2014) Spatially-sparse convolutional neural networks. arXiv:1409.6070
Acknowledgments
This work was sponsored by National Nature Science Foundation of China (61173106).
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article

Cite this article
Samatin Njikam, A.N., Zhao, H. A novel activation function for multilayer feed-forward neural networks. Appl Intell 45, 75–82 (2016). https://doi.org/10.1007/s10489-015-0744-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-015-0744-0