
Abstract
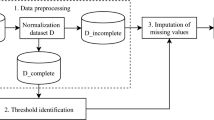
Classification is one of the most important tasks in machine learning with a huge number of real-life applications. In many practical classification problems, the available information for making object classification is partial or incomplete because some attribute values can be missing due to various reasons. These missing values can significantly affect the efficacy of the classification model. So it is crucial to develop effective techniques to impute these missing values. A number of methods have been introduced for solving classification problem with missing values. However they have various problems. So, we introduce an effective method for imputing missing values using the correlation among the attributes. Other methods which consider correlation for imputing missing values works better either for categorical or numeric data, or designed for a particular application only. Moreover they will not work if all the records have at least one missing attribute. Our method, Model based Missing value Imputation using Correlation (MMIC), can effectively impute both categorical and numeric data. It uses an effective model based technique for filling the missing values attribute wise and reusing then effectively using the model. Extensive performance analyzes show that our proposed approach achieves high performance in imputing missing values and thus increases the efficacy of the classifier. The experimental results also show that our method outperforms various existing methods for handling missing data in classification.

Similar content being viewed by others


References
Chechik G, Heitz G, Elidan G, Abbeel P, Koller D (2008) Max-margin classification of data with absent features. J Mach Learn Res 9:1–21
Datta S, Misra D, Das S (2016) A feature weighted penalty based dissimilarity measure for k-nearest neighbor classification with missing features. Pattern Recogn Lett 80:231–237
Farhangfar A, Kurgan LA, Dy JG (2008) Impact of imputation of missing values on classification error for discrete data. Pattern Recogn 41(12):3692–3705
Deb R, Liew AW (2015) Incorrect attribute value detection for traffic accident data. In: 2015 international joint conference on neural networks, IJCNN 2015. Killarney, pp 1–7
Deb R, Liew AW, Oh E (2014) A correlation based imputation method for incomplete traffic accident data. In: PRICAI 2014: trends in artificial intelligence - 13th pacific rim international conference on artificial intelligence. Gold Coast, Proceedings, 2014, pp 905–912
Deb R, Liew AW (2014) Missing value imputation for the analysis of incomplete traffic accident data. In: Machine learning and cybernetics - 13th international conference. Lanzhou, Proceedings, pp 275–286
Datta S, Bhattacharjee S, Das S Clustering with missing features: a penalized dissimilarity measure based approach, CoRR http://arXiv.org/abs/1604.06602
Batista GEAPA, Monard MC (2003) An analysis of four missing data treatment methods for supervised learning. Appl Artif Intell 17(5-6):519–533
Grzymala-Busse JW, Hu M (2000) A comparison of several approaches to missing attribute values in data mining. In: Rough sets and current trends in computing, second international conference, RSCTC 2000 Banff. Canada, Revised Papers, pp 378–385
Cheng K, Law N, Siu W (2012) Iterative bicluster-based least square framework for estimation of missing values in microarray gene expression data. Pattern Recogn 45(4):1281–1289
Deb R, Liew AW (2016) Missing value imputation for the analysis of incomplete traffic accident data. Inf Sci 339:274–289
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm. J R Statist Soc Series B 39:1–38
Fogue M, Garrido P, Martinez FJ, Cano J, Calafate CMT, Manzoni P (2013) A novel approach for traffic accidents sanitary resource allocation based on multi-objective genetic algorithms. Expert Syst Appl 40(1):323–336
Liu C, Dai D, Yan H (2010) The theoretic framework of local weighted approximation for microarray missing value estimation. Pattern Recogn 43(8):2993–3002
Gan XC, Liew AWC, Yan H (2006) Microarray missing data imputation based on a set theoretic framework and biological constraints. In: ICPR, pp III: 842–845
Junninen H, Niska H, Tuppurainen K, Ruuskanen J, Kolehmainen M (2004) Methods for imputation of missing values in air quality data sets. Atmos Environ 38(18):2895–2907
Silva-Ramírez E-L, Pino-Mejías R, López-Coello M, de-la Vega M-DC (2011) Missing value imputation on missing completely at random data using multilayer perceptrons. Neural Netw 24(1):121–129
Schneider T (2001) Analysis of incomplete climate data: estimation of mean values and covariance matrices and imputation of missing values. J Clim 14:5
Dixon JK (1979) Pattern recognition with partly missing data. IEEE Trans Syst Man Cybern 9(10):617–621
Troyanskaya OG, Cantor MN, Sherlock G, Brown PO, Hastie T, Tibshirani R, Botstein D, Altman RB (2001) Missing value estimation methods for DNA microarrays. Bioinformatics 17(6):520–525
Bo T (2004) Lsimpute: accurate estimation of missing values in microarray data with least squares methods. Nucleic Acid Res 32(3):2004
Sehgal M (2005) Collateral missing value imputation: a new robust missing value estimation algorithm fpr microarray data. Bioinformatics 21(10):2005
Ashraf M (2011) Iterative weighted k-nn for constructing missing feature values in wisconsin breast cancer dataset. In: 3rd international conference on data mining and intelligent information technology applications. IEEE
Liu Z, Pan Q, Dezert J, Martin A (2016) Adaptive imputation of missing values for incomplete pattern classification. Pattern Recogn 52:85–95
García-Laencina P J, Sancho-Gȯmez J, Figueiras-Vidal AR, Verleysen M (2009) K nearest neighbours with mutual information for simultaneous classification and missing data imputation. Neurocomputing 72(7–9):1483–1493
Aydilek IB, Arslan A (2013) A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inf Sci 233:25–35
Rahman MG, Islam MZ (2013) Missing value imputation using decision trees and decision forests by splitting and merging records: two novel techniques. Knowl-Based Syst 53:51–65
Rahman M (2013) k-dmi: a novel method for missing values imputation using two levels of horizontal partitioning in a data set. In: Proceeding of ADMA2013 conference. Hangzhou
Rahman MG, Islam MZ (2014) FIMUS: a framework for imputing missing values using co-appearance, correlation and similarity analysis. Knowl-Based Syst 56:311–327
Giggins H, Brankovic L (2012) VICUS - a noise addition technique for categorical data. In: Tenth Australasian data mining conference, AusDM 2012. Sydney, pp 139–148
Silva-Ramirez E.-L. (2011) Missing value imputation on missing completely at random data using multilayer perceptions. Neural Netw 24(1):2011
Amiri M, Jensen R (2016) Missing data imputation using fuzzy-rough methods. Neurocomputing 205:152–164
Zhu X, Zhang S, Jin Z, Zhang Z, Xu Z (2011) Missing value estimation for mixed-attribute data sets. IEEE Trans Knowl Data Eng 23(1):110–121
García-Laencina PJ, Sancho-Gȯmez J, Figueiras-Vidal AR (2013) Classifying patterns with missing values using multi-task learning perceptrons. Expert Syst Appl 40(4):1333–1341
Angiulli F, Fassetti F (2013) Nearest neighbor-based classification of uncertain data. TKDD 7(1):1
Acknowledgments
We would like to express our deep gratitude to the anonymous reviewers of this paper. The useful comments have played a significant role in improving the quality of this work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zahin, S.A., Ahmed, C.F. & Alam, T. An effective method for classification with missing values. Appl Intell 48, 3209–3230 (2018). https://doi.org/10.1007/s10489-018-1139-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-018-1139-9