
Abstract
In order to respect the standards of the “semantic web” which allows the data to be shared and reused between several applications, it became necessary to model web text documents with a vision based on the concepts and exploit available linguistic resources. It’s evident that the extraction of semantic tokens ensures semantic modelling of web documents. Unfortunately, terminology extraction techniques from unstructured Web text remain unable to provide powerful results. Indeed, systems developed based on the classical techniques extract massively high amounts of candidate terms and leave the task of separation between relevant and irrelevant candidates for post-processing. In this paper, we introduce HMM-Extract a novel model for terminology retrieval based on Markov model. Our model integrates two modules that work in cascade: a module based on Hidden Markov Model (HMM) for complex term extraction and a module based on Markov Chain for filtering terms provided by the HMM. Thus, we try to focus on three main contributions: firstly, we provide a linguistic and statistical specification of relevant terms. Secondly, we show the possibility of using a HMM to extract relevant terms from unstructured textual documents. Finally, we prove the importance of integrating statistical knowledge in a Markov Chain and we show, experimentally, its contribution to the field of terminology extraction.











Similar content being viewed by others


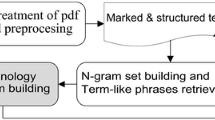
Notes
References
Aggarwal CC (2018) Information extraction. Springer International Publishing, Cham, pp 381–411
Anthony L (2013) Developing antconc for a new generation of corpus linguists. In: Proceedings of the corpus linguistics conference (CL 2013), pp 14–16
Aubin S, Hamon T (2006) Improving term extraction with terminological resources. In: Proceedings of the 5th international conference on advances in natural language processing, FinTAL’06. Springer, Berlin, pp 380–387
Avinash M, Sivasankar E (2019) A study of feature extraction techniques for sentiment analysis. In: Abraham A, Dutta P, Mandal JK, Bhattacharya A, Dutta S. (eds) Emerging technologies in data mining and information security. Springer, Singapore, pp 475–486
Barkman J (1958) Phytosociology and ecology of cryptogamic epiphytes: including a taxonomic survey and description of their vegetation units in Europe. Van Gorcum
Boukhari K, Omri MN (2015) SAID: a new stemmer algorithm to indexing unstructured document. In: 15th International conference on intelligent systems design and applications, ISDA 2015, Marrakech, Morocco, December 14-16, 2015, pp 59–63
Bourigault D (1993) Analyse syntaxique locale pour le repérage de termes complexes dans un texte. T.A.L. Traitement automatique des langues 34(2):105–117
Bourigault D (1995) Lexter: a terminology extraction software for knowledge acquisition from texts. In: KAW’95
Bourigault D, Jacquemin C (2000) Construction de ressources terminologiques. In: Ingénierie des langues. Hermes Science, pp 215–233
Cai Z, He Z, Guan X, Li Y (2018) Collective data-sanitization for preventing sensitive information inference attacks in social networks. IEEE Trans Depend Secur Comput 15(4):577–590
Cao Y, Yang WY, Lin CY, Yu Y (2011) A structural support vector method for extracting contexts and answers of questions from online forums. Inf Process Manage 47(6):886–898
Castellví MT, Bagot RE, Palatresi JV (2001) Automatic term detection: a review of current systems. In: Bourigault D, Jacquemin C, L’Homme MC (eds) Recent advances in computational terminology. John Benjamins, Amsterdam, pp 53–88
Chen J, Yeh CH, Chau R (2006) A multi-word term extraction system. In: Yang Q, Webb G (eds) PRICAI 2006: trends in artificial intelligence: 9th pacific rim international conference on artificial intelligence Guilin, China, August 7-11, 2006 Proceedings. Springer, Berlin, pp 1160–1165
Cheng M, Li L, Ren Y, Lou Y, Gao J (2019) A hybrid method to extract clinical information from Chinese electronic medical records. IEEE Access 7:70624–70633
Church KW, Hanks P (1990) Word association norms, mutual information, and lexicography. Comput Linguist 16(1):22–29
Cramér H (1999) Mathematical methods of statistics. Mathematical Series. Princeton University Press, Princeton
Daille B (1994) Approche mixte pour l’extraction automatique de terminologie : statistique lexicale et filtres linguistiques. Ph.D. thesis, Université, Paris, p 7
Fano R (1961) Transmission of information: a statistical theory of communications. M.I.T Press
Felber H (1984) Terminology manual. Unesco and Infoterm, Paris
Fkih F (2016) Modèles d’indexation et algorithmes de recherche d’information à partir de documents non structurés. Ph.D. thesis, Faculty of Economics and Management of Sfax
Fkih F, Omri MN (2012) Complex terminology extraction model from unstructured web text based linguistic and statistical knowledge. IJIRR 2(3):1–18
Fkih F, Omri MN (2012) Information retrieval from unstructured web text document based on automatic learning of the threshold. IJIRR 2(4):12–30
Fkih F, Omri MN (2012) Learning the size of the sliding window for the collocations extraction: a roc-based approach. In: The 2012 international conference on artificial intelligence, ICAI’12, pp 1071–1077
Fkih F, Omri MN (2013) Estimation of a priori decision threshold for collocations extraction: an empirical study. Int J Inf Technol Web Eng 8(3):34–49
Fkih F, Omri MN (2016) IRAFCA: an o(n) information retrieval algorithm based on formal concept analysis. Knowl Inf Syst 48(2):465–491
Florescu C, Caragea C (2017) Positionrank: an unsupervised approach to keyphrase extraction from scholarly documents. In: Proceedings of the 55th annual meeting of the association for computational linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, volume 1: Long Papers, pp 1105–1115
Garrouch K (2017) Modèles de recherche d’information basés sur les réseaux bayésiens et les réseaux possibilistes. Ph.D. thesis, Faculty of Economics and Management of Sfax
Gollapalli SD, Caragea C (2014) Extracting keyphrases from research papers using citation networks. In: Proceedings of the Twenty-Eighth AAAI conference on artificial intelligence, AAAI’14. AAAI Press, pp 1629–1635
Guerreiro Ja, Gonçalves D, de Matos DM (2013) Towards a fair comparison between name disambiguation approaches. In: Proceedings of the 10th conference on open research areas in information retrieval, OAIR ’13. Centre de Hautes Etudes Internationales d’Informatique Documentaire, France, pp 17–20
Guilbert L (1965) La formation du vocabulaire de l’aviation. Larousse
Hasan KS, Ng V (2014) Automatic keyphrase extraction: a survey of the state of the art. In: Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: long papers). Association for Computational Linguistics, Baltimore, pp 1262–1273
Ittoo A, Bouma G (2013) Term extraction from sparse, ungrammatical domain-specific documents. Expert Syst Appl 40(7):2530–2540
Jacquemin C (1994) Fastr: a unification-based front-end to automatic indexing. In: RIAO, pp 34–48
Khan I, Kulkarni A (2013) Knowledge extraction from survey data using neural networks. Proced Comput Sci 20(0):433–438. Complex Adaptive Systems
Lerat P (1995) Les langues spécialisées. Linguistique nouvelle Presses universitaires de France
Li Z, Yang Z, Shen C, Xu J, Zhang Y, Xu H (2019) Integrating shortest dependency path and sentence sequence into a deep learning framework for relation extraction in clinical text. BMC Med Inform Decis Mak 19(1):22
Liu Z, Huang W, Zheng Y, Sun M (2010) Automatic keyphrase extraction via topic decomposition. In: Proceedings of the 2010 conference on empirical methods in natural language processing, EMNLP ’10. Association for Computational Linguistics, Stroudsburg, pp 366–376
Manek AS, Shenoy PD, Mohan MC, R VK (2016) Aspect term extraction for sentiment analysis in large movie reviews using gini index feature selection method and svm classifier. World Wide Web, 1–20
Mihalcea R, Tarau P (2004) TextRank: bringing order into texts. In: Proceedings of EMNLP-04and the 2004 conference on empirical methods in natural language processing
Nazar R (2016) Distributional analysis applied to terminology extraction. Terminol Int J Theor Appl Issues Special Commun 22(2):141–170
Nguyen TD, Kan MY (2007) Keyphrase extraction in scientific publications. In: Proceedings of the 10th international conference on asian digital libraries: looking back 10 years and forging new frontiers, ICADL’07. Springer, Berlin, pp 317–326
Nugumanova A, Bessmertny I, Baiburin Y, Mansurova M (2016) A new operationalization of contrastive term extraction approach based on recognition of both representative and specific terms. Springer International Publishing, Cham
OCHIAI A (1957) Zoogeographical studies on the soleoid fishes found in Japan and its neighhouring regions-ii. NIPPON SUISAN GAKKAISHI 22(9):526–530
Omri MN (2004) Pertinent knowledge extraction from a semantic network: Application of fuzzy sets theory. Int J Artif Intell Tools 13(3):705–720
Parisi F (2016) Clinical term recognition: from local to LOINC terminology. An application for italian language. Springer International Publishing, Cham
Rabiner LR (1989) A tutorial on hidden Markov models and selected applications in speech recognition. Proc IEEE 77(2):257–286
Roche M, Azé J, Kodratoff Y, Sebag M (2004) Learning interestingness measures in terminology extraction - a roc-based approach. In: Proceedings of “ROC analysis in AI” workshop (ECAI), pp 81–88
Roche M, Heitz T, Matte-Tailliez O, Kodratoff Y (2004) Exit : extraction itérative de la terminologie. Revue RNTI (Revue des Nouvelles Technologies de l’Information), numéro spécial EGC’2004 (résumé) E2:478
Ropero J, Gómez A, Carrasco A, León C (2012) A fuzzy logic intelligent agent for information extraction: introducing a new fuzzy logic-based term weighting scheme. Expert Syst Appl 39(4):4567–4581
Silberztein M (1999) Text indexation with intex. Comput Hum 33(3):265–280
da Silva Conrado M, Felippo AD, Salgueiro Pardo TA, Rezende SO (2014) A survey of automatic term extraction for brazilian portuguese. J Braz Comput Soc 20(1):12
Smadja F (1993) Retrieving collocations from text: xtract. Comput Linguist 19(1):143–177
Teneva N, Cheng W (2017) Salience rank: efficient keyphrase extraction with topic modeling. In: Barzilay R, Kan MY (eds) Proceedings of the 55th annual meeting of the association for computational linguistics, vol 2. ACL, Vancouver, pp 530–535
Tesnière L. (1959) Elements de syntaxe structurale. Editions Klincksieck
Uzun E, Agun HV, Yerlikaya T (2013) A hybrid approach for extracting informative content from web pages. Inf Process Manage 49(4):928–944
Viterbi A (2006) Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans Inf Theor 13(2):260–269
Wan X, Xiao J (2008) Single document keyphrase extraction using neighborhood knowledge. In: Proceedings of the 23rd national conference on artificial intelligence - volume 2, AAAI’08. AAAI Press, pp 855–860
Wei X, Croft B, Mccallum A (2006) Table extraction for answer retrieval. Inf Retr 9(5):589–611
Witten IH, Paynter GW, Frank E, Gutwin C, Nevill-Manning CG (1999) Kea: practical automatic keyphrase extraction. In: Proceedings of the fourth ACM conference on digital libraries, DL ’99. ACM, New York, pp 254–255
Wüster E (1991) Einführung in die allgemeine Terminologielehre und terminologische Lexikographie. Abhandlungen zur Sprache und Literatur Romanistischer Verlag
Wüster E, for Europe UNEC (1967) The machine tool: an interlingual dictionary of basic concepts, comprising an alphabetical dictionary and a classified vocabulary with definitions and illustration: prepared under the auspices of the United Nations economic commission for Europe and under the direction of Eugene Wunster... Technical Press Limited
Zhang W, Liu T, Yin Q, Zhang Y (2019) Neural recovery machine for chinese dropped pronoun. Front Comput Sci 13(5):1023–1033
Zhong P, Chen J (2006) A generalized hidden Markov model approach for web information extraction. In: Proceedings of the 2006 IEEE/WIC/ACM international conference on web intelligence, WI ’06. IEEE Computer Society, Washington, DC, pp 709–718
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Fkih, F., Omri, M.N. Hidden data states-based complex terminology extraction from textual web data model. Appl Intell 50, 1813–1831 (2020). https://doi.org/10.1007/s10489-019-01568-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01568-4