
Abstract
Squeeze-and-Excitation (SE) Networks won the last ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) classification competition and is very popular in today’s vision community. The SE block is the core of Squeeze-and-Excitation Network (SENet), which adaptively recalibrates channel-wise features and suppresses less useful ones. Since SE blocks can be directly used in existing models and effectively improve performance, SE blocks are widely used in a variety of tasks. In this paper, we propose a novel Parametric Sigmoid (PSigmoid) to enhance the SE block. We named the new module PSigmoid SE (PSE) block. The PSE block can not only suppress features in a channel-wise manner, but also enhance features. We evaluate the performance of our method on four common datasets including CIFAR-10, CIFAR-100, SVHN and Tiny ImageNet. Experimental results show the effectiveness of our method. In addition, we compare the differences between the PSE block and the SE block through a detailed analysis of the configuration. Finally, we use a combination of PSE block and SE block to obtain better performance.


Similar content being viewed by others
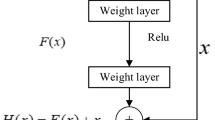


Notes
Width is the number of channels in a layer.
One stage means that only one of the three stages of the model integrates the block.
Two stages means that two of the three stages of the model integrate the block.
References
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436–444. https://doi.org/10.1038/NATURE14539
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L (2015) ImageNet Large Scale Visual Recognition Challenge. Int J Comput Vis 115:211–252. https://doi.org/10.1007/s11263-015-0816-y
Krizhevsky A, Sutskever I, Hinton G (2012) ImageNet classication with deep convolutional neural networks. In: Advances in neural information processing systems, pp 1097–1105. https://doi.org/10.1145/3065386
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: Proceedings of the International conference on learning representations
Szegedy C, Liu W, Jia Y, Sermanet PS et al (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1–9. https://doi.org/10.1109/CVPR.2015.7298594
Bianchini M, Scarselli F (2014) On the Complexity of Neural Network Classifiers: A Comparison Between Shallow and Deep Architectures. IEEE Trans Neural Netw Learn Syst 25(8):1553–1565. https://doi.org/10.1109/TNNLS.2013.2293637
Huang G, Liu Z, Pleiss G, van der Maaten L, Weinberger KQ (2019) Convolutional Networks with Dense Connectivity. IEEE Trans Pattern Anal Mach Intell:1–1. https://doi.org/10.1109/TPAMI.2019.2918284
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Zhang K, Sun M, Han TX, Yuan Xf, Guo L, Liu T (2018) Residual Networks of Residual Networks: Multilevel Residual Networks. IEEE Trans Circ Syst Video Technol 28(6):1303–1314. https://doi.org/10.1109/TCSVT.2017.2654543
Ioffe S, Szegedy C (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the lnternational Conference on Machine Learning, pp 448–456
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feedforward neural networks. J Mach Learn Res 9:249–256
Srivastava RK, Greff K, Schmidhuber J, Schmidhuber (2015) Training very deep networks. In: Advances in Neural Information Processing Systems, pp 2377–2385
Huang G, Sun Y, Liu Z, Sedra D, Weinberger KQ (2016) Deep networks with stochastic depth. In: Proceedings of the European Conference on Computer Vision, pp 646–661. https://doi.org/10.1007/978-3-319-46493-0_39
Veit A, Wilber M, Belongie S (2016) Residual networks are exponential ensembles of relatively shallow networks. In: Advances in neural information processing systems, pp 550–558
Xie S, Girshick R, Dollar P, Tu Z, He K (2017) Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1492–1500. https://doi.org/10.1109/CVPR.2017.634
Chollet F (2017) Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 550–558. https://doi.org/10.1109/CVPR.2017.195
Gao H, Wang Z, Cai L, Ji S (2020) ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions. IEEE Trans Pattern Anal Mach Intell:1–1. https://doi.org/10.1109/TPAMI.2020.2975796
Hu J, Shen L, Sun G (2020) Squeeze-and-Excitation Networks. IEEE Trans Pattern Anal Mach Intell 42(8):2011–2023. https://doi.org/10.1109/TPAMI.2019.2913372
Li Y, Fan C, Li Y, Wu Q, Ming Y (2018) Improving deep neural network with multiple parametric exponential linear units. Neurocomputing 301:11–24. https://doi.org/10.1016/j.neucom.2018.01.084
Zhao H, Liu F, Li L, Luo C (2018) A novel softplus linear unit for deep convolutional neural networks. Appl Intell 48(7):1707–1720. https://doi.org/10.1007/s10489-017-1028-7
He K, Zhang X, Ren S, Sun J (2015) Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1026–1034. https://doi.org/10.1109/ICCV.2015.123
Njikam ANS, Zhao H (2016) A novel activation function for multilayer feed-forward neural networks. Appl Intell 45(1):75–82. https://doi.org/10.1007/s10489-015-0744-0
Ying Y, Su J, Shan P, Miao L, Wang X, Peng S (2019) Rectified exponential units for convolutional neural networks. IEEE Access 7:101633–101640. https://doi.org/10.1109/ACCESS.2019.2928442
Kim D, Kim J, Kim J (2020) Elastic exponential linear units for convolutional neural networks. Neurocomputing 406:253–266. https://doi.org/10.1016/j.neucom.2020.03.051
Yu X, Ye X, Gao Q (2020) Infrared Handprint Image Restoration Algorithm Based on Apoptotic Mechanism. IEEE Access 8:47334–47343. https://doi.org/10.1109/ACCESS.2020.2979018
Liu X, Zhu X, Li M, Wang L, Zhu E, Liu T, Kloft M, Shen D, Yin J, Gao W (2020) Multiple Kernel k k-Means with Incomplete Kernels. IEEE Trans Pattern Anal Mach Intell1191–1204. https://doi.org/10.1109/TPAMI.2019.2892416
Chandra P, Singh Y (2004) An activation function adapting training algorithm for sigmoidal feedforward networks. Neurocomputing 61:429–437. https://doi.org/10.1016/J.NEUCOM.2004.04.001
Sharma SK, Chandra P (2010) An adaptive slope sigmoidal function cascading neural networks algorithm. In: International Conference on Emerging Trends in Engineering and Technology, pp 531–536. https://doi.org/10.1109/ICETET.2010.71
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324. https://doi.org/10.1109/5.726791
Nair V, Hinton G (2010) Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the lnternational Conference on Machine Learning, pp 807–814
Hahnloser RHR, Sarpeshkar R, Mahowald MA, Douglas RJ, Sebastian Seung H (2000) Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature 405(6789):947–951. https://doi.org/10.1038/35016072
Zhao M, Zhong S, Fu X, Tang B, Dong S, Pecht M (2020) Deep Residual Networks with Adaptively Parametric Rectifier Linear Units for Fault Diagnosis. IEEE Trans Indust Electron:1-1. https://doi.org/10.1109/TIE.2020.2972458
Clevert DA, Unterthiner T, Hochreiter S (2016) Fast and accurate deep network learning by exponential linear units (ELUS). In: Proceedings of the International Conference on Learning Representations
Zagoruyko S., Komodakis N. (2016) Wide residual networks. In: British Machine Vision Conference. https://doi.org/10.5244/C.30.87
Lin M, Chen Q, Yan S (2014) Network in network. In: Proceedings of the International Conference on Learning Representations
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2818–2826. https://doi.org/10.1109/CVPR.2016.308
Szegedy C, Ioffe S, Vanhoucke V (2017) Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 4278–4284
Zhang X, Zhou X, Lin M, Sun J (2018) ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6848–6856. https://doi.org/10.1109/CVPR.2018.00716
Hou S, Wang Z (2019) Weighted channel dropout for regularization of deep convolutional neural network. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 8425–8432. https://doi.org/10.1609/AAAI.V33I01.33018425
Krizhevsky A, Hinton G (2009) Learning multiple layers of features from tiny images. Department of Computer Science, University of Toronto, Masters thesis
Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY (2011) Reading digits in natural images with unsupervised feature learning. In: Advances in neural information processing systems workshop on deep learning and unsupervised feature learning
Tiny ImageNet Visual Recognition Challenge. [Online] Available: https://tinyimagenet.herokuapp.com
Zeiler MD, Fergus R (2014) Visualizing and understanding convolutional networks. In: Proceedings of the European Conference on Computer Vision, pp 818–833. https://doi.org/10.1007/978-3-319-10590-1_53
Alain G, Bengio Y (2017) Understanding intermediate layers using linear classifier probes. In: Proceedings of the International Conference on Learning Representations Workshop
Yosinski J, Clune J, Bengio Y, Lipson H (2014) How transferable are features in deep neural networks? In: Advances in neural information processing systems, pp 3320–3328
Lin T-Y, Maire M, Belongie S et al (2014) Microsoft COCO: Common Objects in Context. In: Proceedings of the European Conference on Computer Vision, pp 740–755. https://doi.org/10.1007/978-3-319-10602-1_48
Wah C, Branson S, Welinder P, Perona P, Belongie S (2011) The Caltech-UCSD Birds-200-2011 dataset. California Institute of Technology
Song W, Zheng J, Wu Y, Chen C, Liu F (2020) Discriminative feature extraction for video person re-identification via multi-task network. Applied Intelligence. https://doi.org/10.1007/s10489-020-01844-8
Wu L, Wang Y, Li X, Gao J (2019) Deep Attention-Based Spatially Recursive Networks for Fine-Grained Visual Recognition. IEEE Trans Cybern 49(5):1791–1802. https://doi.org/10.1109/TCYB.2018.2813971
Zheng Z, An G, Wu D, Ruan Q (2020) Global and Local Knowledge-Aware Attention Network for Action Recognition. IEEE Trans Neural Netw Learn Syst:1–14. https://doi.org/10.1109/TNNLS.2020.2978613
Choe J, Lee S, Shim H (2020) Attention-based Dropout Layer for Weakly Supervised Single Object Localization and Semantic Segmentation. IEEE Trans Pattern Anal Mach Intell:1–1. https://doi.org/10.1109/TPAMI.2020.2999099
Woo S, Park J, Lee J-Y, So Kweon I (2018) Cbam: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision, pp 3–19. https://doi.org/10.1007/978-3-030-01234-2_1
Acknowledgements
This work was supported from the following foundations: National Natural Science Foundation of China (Grant no. 61601104) and the Fundamental Research Funds for the Central Universities (Grant no. N2023021).The authors thank Wei Li, Yang Li, Feng Zhang, Feng Jia, Jianlin Su, Xinyu Ou and Shenqi Lai for help discussions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ying, Y., Zhang, N., Shan, P. et al. PSigmoid: Improving squeeze-and-excitation block with parametric sigmoid. Appl Intell 51, 7427–7439 (2021). https://doi.org/10.1007/s10489-021-02247-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-021-02247-z