
Abstract
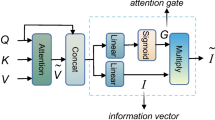
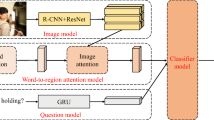
Most existing visual question answering (VQA) models choose to model the dense interactions between each image region and each question word when learning the co-attention between the input images and the input questions. However, to correctly answer a natural language question related to the content of an image usually only requires understanding a few key words of the input question and capturing the visual information contained in a few regions of the input image. The noise information generated by the interactions between the image regions unrelated to the input questions and the question words unrelated to the prediction of the correct answers will distract VQA models and negatively affect the performance of the models. In this paper, to solve this problem, we propose a Sparse Co-Attention Visual Question Answering Network (SCAVQAN) based on thresholds. SCAVQAN concentrates the attention of the model by setting thresholds for attention scores to filter out the image features and the question features that are the most helpful for predicting the correct answers and finally improves the overall performance of the model. Experimental results, ablation studies and attention visualization results based on two benchmark VQA datasets demonstrate the effectiveness and interpretability of our models.










Similar content being viewed by others

References
Minaee S, Kalchbrenner N, Cambria E, Nikzad N, Chenaghlu M, Gao J (2021) Deep learning-based text classification: a comprehensive Review. ACM Comput Surv 54(3):62:1–62:40
Kim J, Jang S, Park EL, Choi S (2020) Text classification using capsules. Neurocomputing 376:214–221
Chen K, Wang R, Utiyama M, Sumita E, Zhao T, Yang M, Zhao H (2020) Towards more diverse input representation for neural machine translation. IEEE ACM Trans Audio Speech Lang Process 28:1586–1597
Sun H, Wang R, Chen K, Utiyama M, Sumita E, Zhao T (2020) Unsupervised neural machine translation with cross-lingual language representation agreement. IEEE ACM Trans Audio Speech Lang Process 28:1170–1182
Fan C, Yi J, Tao J, Tian Z, Liu B, Wen Z (2021) Gated recurrent fusion with joint training framework for robust end-to-end speech recognition. IEEE ACM Trans Audio Speech Lang Process 29:198–209
Miao H, Cheng G, Gao C, Zhang P, Yan Y (2020) Transformer-based Online CTC/attention end-to-end speech recognition architecture. ICASSP:6084–6088
Lee K-H, Xi C, Hua G, Hu H, He X (2018) Stacked cross attention for Image-Text matching. ECCV (4):212–228
Wang L, Li Y, Huang J, Lazebnik S (2019) Learning Two-Branch neural networks for Image-Text matching tasks. IEEE Trans Pattern Anal Mach Intell 41(2):394–407
Yu N, Hu X, Song B, Yang J, Zhang J (2019) Topic-Oriented Image captioning based on Order-Embedding. IEEE Trans Image Process 28(6):2743–2754
Yang M, Liu J, Shen Y, Zhao Z, Chen X, Wu Q, Li C (2020) An ensemble of generation- and Retrieval-Based image captioning with dual generator generative adversarial network. IEEE Trans Image Process 29:9627–9640
Qiao Y, Yu Z, Liu J (2020) VC-VQA: Visual Calibration mechanism for visual question answering. ICIP:1481–1485
Yang C, Jiang M, Jiang B, Zhou W, Li K (2019) Co-Attention Network with question type for visual question answering. IEEE Access 7:40771–40781
Agrawal A, Batra D, Parikh D, Kembhavi A (2018) Don’t just assume; look and answer: Overcoming priors for visual question answering. CVPR:4971–4980
Zhang L, Liu S, Liu D, Zeng P, Li X, Song J, Gao L (2021) Rich visual Knowledge-Based augmentation network for visual question answering. IEEE Trans Neural Netw Learn Syst 32(10):4362–4373
Yu J, Zhang W, Lu Y, Qin Z, Hu Y, Tan J, Wu Q (2020) Reasoning on the relation: Enhancing visual representation for visual question answering and Cross-Modal retrieval. IEEE Trans Multim 22 (12):3196–3209
Guo Z, Han D (2020) Multi-Modal Explicit sparse attention networks for visual question answering. Sensors 20(23):6758
Nam H, Ha J-W, Kim J (2017) Dual attention networks for multimodal reasoning and matching. CVPR:2156–2164
Nguyen D-K, Okatani T (2018) Improved fusion of visual and language representations by dense symmetric Co-Attention for visual question answering. CVPR:6087–6096
Yu Z, Yu J, Cui Y, Tao D, Qi T (2019) Deep modular Co-Attention networks for visual question answering. CVPR:6281– 6290
Ren S, He K, Girshick RB, Sun J (2017) Faster r-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39(6):1137–1149
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li L-J, Shamma DA, Bernstein MS, Li F-F (2017) Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int J Comput Vis 123(1):32–73
Goyal Y, Khot T, Agrawal A, Summers-Stay D, Batra D, Parikh D (2019) Making the v in VQA matter: Elevating the role of image understanding in visual question answering. Int J Comput Vis 127 (4):398–414
Hudson DA, Manning CD (2019) GQA: A new dataset for Real-World visual reasoning and compositional question answering. CVPR:6700–6709
Pennington J, Socher R, Manning CD (2014) Glove: Global vectors for word representation. EMNLP:1532–1543
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is All you Need. NIPS:5998–6008
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. CVPR:770–778
Agrawal A, Lu J, Antol S, Mitchell M, Lawrence Zitnick C, Parikh D, Batra D (2017) VQA: Visual Question answering. Int J Comput Vis 123(1):4–31
Teney D, Anderson P, He X, van den Hengel A (2018) Tips and tricks for visual question answering: Learnings from the 2017 challenge. CVPR:4223–4232
Chen C, Han D, Wang J (2020) Multimodal Encoder-Decoder attention networks for visual question answering. IEEE Access 8:35662–35671
Drew A, Hudson CD (2018) Manning. Compositional Attention Networks for Machine Reasoning. ICLR (Poster)
Acknowledgements
This research is supported by the National Natural Science Foundation of China under Grant 61873160 and Grant 61672338, and the Natural Science Foundation of Shanghai under Grant 21ZR1426500. We thank all the reviewers for their constructive comments and helpful suggestions.
Author information
Authors and Affiliations
Contributions
Methodology, material preparation, data collection, and analysis were performed by Zihan Guo. Zihan Guo wrote the first draft of the manuscript, Dezhi Han and Zihan Guo commented on previous versions of the manuscript. Dezhi Han did the supervision, reviewing, and editing. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Guo, Z., Han, D. Sparse co-attention visual question answering networks based on thresholds. Appl Intell 53, 586–600 (2023). https://doi.org/10.1007/s10489-022-03559-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-03559-4