
Abstract
Robot learning is critically enabled by the availability of appropriate state representations. We propose a robotics-specific approach to learning such state representations. As robots accomplish tasks by interacting with the physical world, we can facilitate representation learning by considering the structure imposed by physics; this structure is reflected in the changes that occur in the world and in the way a robot can effect them. By exploiting this structure in learning, robots can obtain state representations consistent with the aspects of physics relevant to the learning task. We name this prior knowledge about the structure of interactions with the physical world robotic priors. We identify five robotic priors and explain how they can be used to learn pertinent state representations. We demonstrate the effectiveness of this approach in simulated and real robotic experiments with distracting moving objects. We show that our method extracts task-relevant state representations from high-dimensional observations, even in the presence of task-irrelevant distractions. We also show that the state representations learned by our method greatly improve generalization in reinforcement learning.
















Similar content being viewed by others


Notes
Note, however, that we construct a loss function based on the priors that are proposed in this paper. This loss could be interpreted as negative logarithm of a prior probability distribution such that minimizing this loss function is analogous to maximizing the posterior.
The slot car racing task is inspired by an experiment of Lange et al. (2012).
The colors of the distractors were chosen to be equal to their background in the green and the blue color channel of the RGB image. They can be ignored by not taking into account the observation dimensions that correspond to the red color channel.
Fig. 7 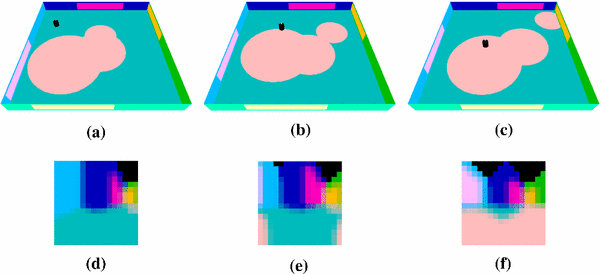
Distractors in the simple navigation task. a–c Show three situations at an interval of ten time steps. The robot is exploring while the distractors move randomly. d–f Show the corresponding observations (note how they are influenced by the distractors)

References
Bengio, Y., Courville, A. C., & Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798–1828.
Boots, B., Siddiqi, S. M., & Gordon, G. J. (2011). Closing the learning-planning loop with predictive state representations. International Journal of Robotics Research, 30(7), 954–966.
Bowling, M., Ghodsi, A., Wilkinson, D. (2005). Action respecting embedding. In 22nd international conference on machine learning (ICML) (pp. 65–72).
Cobo, L. C., Subramanian, K., Isbell, C. L, Jr, Lanterman, A. D., & Thomaz, A. L. (2014). Abstraction from demonstration for efficient reinforcement learning in high-dimensional domains. Artificial Intelligence, 216(1), 103–128.
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, Koray, & Kuksa, Pavel. (2011). Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(8), 2493–2537.
Duell, S., Udluft, S., & Sterzing, V. (2012). Solving partially observable reinforcement learning problems with recurrent neural networks. In G. Montavon, G. Orr, & K.-R. Müller (Eds.), Neural Networks: Tricks of the trade. Lecture notes in computer science (Vol. 7700, pp. 709–733). Berlin: Heidelberg: Springer.
Hadsell, R., Chopra, S., LeCun, Y. (2006). Dimensionality reduction by learning an invariant mapping. In IEEE computer society conference on computer vision and pattern recognition (CVPR) (pp. 1735–1742).
Höfer, S., Hild, M., Kubisch, M. (2010). Using slow feature analysis to extract behavioural manifolds related to humanoid robot postures. In 10th international conference on epigenetic robotics (pp. 43–50).
Hutter, M. (2009). Feature reinforcement learning: Part I: Unstructured MDPs. Journal of Artificial General Intelligence, 1(1), 3–24.
Igel, C., & Hüsken, M. (2003). Empirical evaluation of the improved RPROP learning algorithms. Neurocomputing, 50(1), 105–123.
Jenkins, O. C., Matarić, M. J. (2004). A spatio-temporal extension to ISOMAP nonlinear dimension reduction. In 21st international conference on machine learning (ICML) (p. 56).
Jetchev, N., Lang, T., Toussaint, M. (2013). Learning grounded relational symbols from continuous data for abstract reasoning. In Autonomous learning workshop at the IEEE international conference on robotics and automation.
Jonschkowski, R., Brock, O. (2013). Learning task-specific state representations by maximizing slowness and predictability. In 6th international workshop on evolutionary and reinforcement learning for autonomous robot systems (ERLARS).
Jonschkowski, R., & Brock, O. (2014). State representation learning in robotics: Using prior knowledge about physical interaction. In Robotics: Science and Systems (RSS).
Kaelbling, L. P., & Littman, M. L. (1998). Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1), 99–134.
Kober, J., Bagnell, J. A., & Peters, J. (2013). Reinforcement learning in robotics: A survey. International Journal of Robotics Research, 32(11), 1238–1274.
Konidaris, G., Barto, A. G. (2009). Efficient skill learning using abstraction selection. In 21st international joint conference on artificial intelligence (IJCAI) (pp. 1107–1112).
Krizhevsky, A., Sutskever, I., Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In Advances in neural information processing systems (NIPS) (pp. 1106–1114).
Kruskal, J. B. (1964). Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika, 29(1), 1–27.
Lange, S., Riedmiller, M., Voigtländer, A. (2012). Autonomous reinforcement learning on raw visual input data in a real world application. In International joint conference on neural cetworks (IJCNN) (pp. 1–8).
Legenstein, R., Wilbert, N., & Wiskott, L. (2010). Reinforcement learning on slow features of high-dimensional input streams. PLoS Computational Biology, 6(8), e1000894.
Littman, M. L., Sutton, R. S., Singh, S. (2002). Predictive representations of state. In Advances in neural information processing systems (NIPS) (pp. 1555–1561).
Luciw, M., & Schmidhuber, J. (2012). Low complexity proto-value function learning from sensory observations with incremental slow feature analysis. In 22nd international conference on artificial neural networks and machine learning (ICANN) (pp. 279–287).
Mahadevan, S., & Maggioni, M. (2007). Proto-value functions: A laplacian framework for learning representation and control in markov decision processes. Journal of Machine Learning Research, 8(10), 2169–2231.
Menache, I., Mannor, S., & Shimkin, N. (2005). Basis function adaptation in temporal difference reinforcement learning. Annals of Operations Research, 134(1), 215–238.
Piater, J., Jodogne, S., Detry, R., Kraft, D., Krüger, Norbert, Kroemer, Oliver, et al. (2011). Learning visual representations for perception-action systems. International Journal of Robotics Research, 30(3), 294–307.
Roweis, S. T., & Saul, L. K. (2000). Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500), 2323–2326.
Scholz, J., Levihn, M., Isbell, C., Wingate, D. (2014). A physics-based model prior for object-oriented MDPs. In 31st international conference on machine learning (ICML).
Seide, F., Li, G., Yu, D. (2011). Conversational speech transcription using context-dependent deep neural networks. In Interspeech (pp. 437–440).
Shepard, R. N. (1987). Toward a universal law of generalization for psychological science. Science, 237(4820), 1317–1323.
Singh, S. P., Jaakkola, T., Jordan, M. I. (1995). Reinforcement learning with soft state aggregation. In Advances in neural information processing systems (NIPS) (pp. 361–368).
Sprague, N. (2009). Predictive projections. In 21st international joint conference on artificial intelligence (IJCAI) (pp. 1223–1229).
Sutton, R. S., & Barto, A. G. (1998). Reinforcement Learning: An introduction. Cambridge, MA: MIT Press.
Tenenbaum, J. B., De Silva, V., & Langford, J. C. (2000). A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500), 2319–2323.
van Seijen, H., Whiteson, S., & Kester, L. J. H. M. (2014). Efficient abstraction selection in reinforcement learning. Computational Intelligence, 30(4), 657–699.
Wiskott, L., & Sejnowski, T. J. (2002). Slow feature analysis: Unsupervised learning of invariances. Neural Computation, 14(4), 715–770.
Acknowledgments
We gratefully acknowledge financial support by the Alexander von Humboldt foundation through an Alexander von Humboldt professorship (funded by the German Federal Ministry of Education and Research). We would like to thank Sebastian Höfer, Johannes Kulick, Marc Toussaint, and our anonymous reviewers for their very helpful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
This is one of several papers published in Autonomous Robots comprising the “Special Issue on Robotics Science and Systems”.
Rights and permissions
About this article

Cite this article
Jonschkowski, R., Brock, O. Learning state representations with robotic priors. Auton Robot 39, 407–428 (2015). https://doi.org/10.1007/s10514-015-9459-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10514-015-9459-7