
Abstract
Treebanks, especially the Penn treebank for natural language processing (NLP) in English, play an essential role in both research into and the application of NLP. However, many languages still lack treebanks and building a treebank can be very complicated and difficult. This work has a twofold objective. Firstly, to share our results in constructing a large Vietnamese treebank (VTB) with three levels of annotation including word segmentation, part-of-speech tagging, and syntactic analysis. Major steps in the treebank construction process are described with particular regard to specific Vietnamese properties such as lack of word delimiter and isolation. Those properties make sentences highly syntactically ambiguous, and therefore it is difficult to ensure a high level of agreement among annotators. Various studies of Vietnamese syntax were employed not only to define annotations but also to systematically deal with ambiguities. Annotators were supported by automatic labelling tools, which are based on statistical machine learning methods, for sentence pre-processing and a tree editor for supporting manual annotation. As a result, an annotation agreement of around 90 % was achieved. Our second objective is to present our method for automatically finding errors and inconsistencies in treebank corpora and its application to the construction of the VTB. This method employs the Shannon entropy measure in a manner that the more reduced entropy the more corrected errors in a treebank. The method ranks error candidates by using a scoring function based on conditional entropy. Our experiments showed that this method detected high-error-density subsets of original error candidate sets, and that the corpus entropy was significantly reduced after error correction. The size of these subsets was only about one third of the whole set, while these subsets contained 80–90 % of the total errors. This method can also be applied to languages similar to Vietnamese.







Similar content being viewed by others


Notes
Multi-version treebank publishing has several purposes: error correction, annotation scheme modification, and data addition. For example, major changes in the Penn English Treebank (PTB) Marcus and Marcinkiewicz (1993) upgrade from version I to version II include POS tagging error correction and predicate-argument structure labelling. In the PTB upgrade from version II to version III, more data is appended.
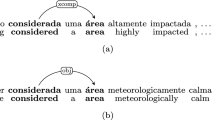
This choice emphasizes the similarity between Chinese and other languages.
JJ: adjective, NN: noun
Note that before Dickinson, Halteren (2000) pointed out that POS taggers can be used to enforce consistency.
ADVP: adverbial phrase, RB: adverb
Steedman et al. (2003) showed that a training set size of around 10,000 syntactic trees was good for English parsing since when using a larger training set, improvement in parsing performance was small (as tested on Collins’ parser).
This term has the same meaning as the term ‘variation nuclei’ in Dickinson and Meurers (2003). In our paper, a variation n-gram is an n-gram which varies in how it is labelled because of ambiguity or annotation error. Contextual information, such as surrounding words, is not included in an n-gram.
They may have a meaning (‘
 ’, ‘hàn\(_{cold}\)’) or not (‘lẽo’, ‘nhánh’)
’, ‘hàn\(_{cold}\)’) or not (‘lẽo’, ‘nhánh’)The other approach is joint processing, in which all tasks are carried out simultaneously.
This classification is widely accepted in the Vietnamese linguistic community.
This term came from the fact that the design for the Penn Treebank tag set was based on the simplification of the Brown Corpus tag set.
Two points nearest to the vertical axis are the number of variation n-grams which have no erroneous instances.
Using \(p(x_{1}, x_{2}, \ldots , x_{K})=Freq(x_{1}, x_{2}, \ldots , x_{K})/L\), the value of empirical entropy reduction was 173.49 on the word-segmented data set.
 ’, ‘hàn
’, ‘hànReferences
Awate, S. P., & Whitaker, R. T. (2006). Unsupervised, information-theoretic, adaptive image filtering for image restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28, 364–376.
Berger, A., Pietra, S. D., & Pietra, V. D. (1996). A maximum entropy approach to natural language processing. Computational Linguistics, 22(1), 39–71.
Black, E., Abney, S., Flickenger, D., Gdaniec, C., Grishman, R., Harrison, P., et al. (1991). A procedure for quantitatively comparing the syntactic coverage of English grammars. In Proceedings of DARPA speech and natural language workshop.
Cao, X.-H. (2007). The Vietnamese language: Phonetics, syntax, and semantics [in Vietnamese]. Cambridge: Education Press.
Chiang, D., & Bikel, D. M. (2002). Recovering latent information in treebanks. In Proceedings of COLING.
Collins, M. (1999). Head-driven statistical models for natural language parsing. Ph.D. thesis, University of Pennsylvania.
Cover, T. M., & Thomas, J. A. (2006). Elements of information theory. New York: Wiley.
Dickinson, M., & Meurers, W. D. (2003). Detecting errors in part-of-speech annotation. In Proceedings of EACL.
Dickinson, M. (2006). From detecting errors to automatically correcting them. In Proceedings of EACL.
Dickinson, M. (2008). Ad hoc treebank structures. In Proceedings of ACL.
Diep, Q.-B. (2005). Vietnamese syntax [in Vietnamese]. Cambridge: Education Press.
Han, C., Han, N., Ko, E., & Palmer, M. (2002). Development and evaluation of a Korean treebank and its application to NLP. In Proceedings of LREC.
Johnson, M. (1998). PCFG models of linguistic tree representation. Computational Linguistics, 24, 613–632.
Jurafsky, D., & Martin, J. H. (2009). Speech and language processing: An introduction to natural language processing., Computational linguistics and speech recognition New Jersey: Prentice Hall.
Klein, D., & Manning, C. D. (2003). Accurate unlexicalized parsing. In Proceedings of ACL.
Lafferty, J., McCallum, A., & Pereira, F. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of ICML.
Marcus, M. P., Marcinkiewicz, M. A., & Santorini, B. (1993). Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19, 313–330.
Mitchell, T. M. (1997). Machine learning. Maidenhead: McGraw-Hill.
Miyao, Y., & Tsujii, J. (2008). Feature forest models for probabilistic HPSG parsing. Computational Linguistics, 34, 35–80.
Nguyen, V.-H. (2009). Vietnamese syntax [in Vietnamese]. Cambridge: Education Press.
Nguyen, T.-M.-H., Vu, X.-L., Le, & H.-P. (2003). A case study of the probabilistic tagger QTAG for tagging Vietnamese texts [in Vietnamese]. In Proceedings of ICT.rda.
Nguyen, T.-C. (2004). Vietnamese syntax [in Vietnamese]. Hanoi: Vietnam National University Press.
Nguyen, P.-T., Vu, X. L., Nguyen, T. M. H., Nguyen, V. H., & Le, H. P. (2009). Building a large syntactically-annotated corpus of Vietnamese. In Proceedings of LAW-3, ACL-IJCNLP.
Nguyen, V.-H. (2009). The history of approaches in describing Vietnamese syntax. Journal of the Research Institute for World Languages, (1), 19–34
Novak, V., & Razimova, M. (2009). Unsupervised detection of annotation inconsistencies using apriori algorithm. In Proceedings of LAW-3, ACL-IJCNLP.
Pajas, P., & Stepanek, J. (2008). Recent advances in a feature-rich framework for treebank annotation. In Proceedings of COLING.
Phuong, L. H., Huyen, N. T. M., Azim, R., & Vinh, H. T. (2008). A hybrid approach to word segmentation of vietnamese texts. In Proceedings of the 2nd international conference on language and automata theory and applications. Springer LNCS 5196, Tarragona, Spain, 2008.
Rambow, O. (2010). The simple truth about dependency and phrase structure representations: An opinion piece. In Proceedings of NAACL.
Santorini, B. (1990). Part-of-speech tagging guidelines for the Penn Treebank Project. In Treebank-3 Documents. Linguistic Data Consortium.
Sciullo, A. M. D., & Williams, E. (1987). On the definition of word. Cambridge: The MIT Press.
Steedman, M., Osborne, M., Sarkar, A., Clark, S., Hwa, R., Hockenmaier, J., et al. (2003). Bootstrapping statistical parsers from small datasets. In Proceedings of EACL.
Thompson, L. C. (1987). A Vietnamese reference grammar. Hawaii: University of Hawaii Press.
van Halteren, H. (2000). The detection of inconsistency in manually tagged text. In Proceedings of LINC.
Xue, N., Xia, F., Chiou, F.-D., & Palmer, M. (2005). The Penn Chinese TreeBank: Phrase structure annotation of a large corpus. Natural Language Engineering, 11, 207–238.
Yamada, H., & Matsumoto, Y. (2003). Statistical dependency analysis with support vector machines. In Proceedings of IWPT.
Yates, A., Schoenmackers, S., & Etzioni, O. (2006). Detecting parser errors using web-based semantic filters. In Proceedings of EMNLP.
Acknowledgments
This paper is supported by the project QGTĐ.12.21 funded by Vietnam National University, Hanoi. We would like to express special thanks to other members of the treebank development team Xuan-Luong Vu and Dr. Thi-Minh-Huyen Nguyen, and linguistic annotators Minh-Thu Dao, Thi-Minh-Ngoc Nguyen, Kim-Ngan Le, Mai-Van Nguyen for the effective cooperation. We also would like to express thanks to Assoc. Prof. Dinh Dien for his comments and discussions during the early stages of the treebank development.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nguyen, PT., Le, AC., Ho, TB. et al. Vietnamese treebank construction and entropy-based error detection. Lang Resources & Evaluation 49, 487–519 (2015). https://doi.org/10.1007/s10579-015-9308-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10579-015-9308-5