
Abstract
MapReduce, proposed as a programming model, has been widely adopted in large-scale data processing with the capability of exploiting distributed resources and processing large-scale data. Nevertheless, such success is accompanied by the difficulty of fitting applications into MapReduce. This is because MapReduce is limited to one kind of fine-grained parallelism—processing every input key-value pair independently. In this paper, we intend MapReduce to feature data processing for coarse-grained parallelism inside applications. More specifically, we generalize the applicability of one MapReduce job to let processing a set of input key-value pairs be allowed dependence, whereas we preserve independence while processing all sets. However, the advancement in this generalization brings the intricate problem of how two-stage processing structure, inherent in MapReduce, handles the dependence while processing a set of input key-value pairs. To tackle this problem, we propose the design pattern called two-phase data processing. It expresses the application in two phases not only to match the two-stage processing structure but to exploit the power of MapReduce through the cooperation between the mappers and reducers. To enable MapReduce to exploit coarse-grained parallelism, we present the design methodology to offer advice on granularity of parallelism, evaluation of manipulating the design pattern, and analysis of dependence. Of the two experiments, the first is conducted on the GPS records of public transit to demonstrate how to fuse a Big Data application with its data preprocessing into one MapReduce job. The second leads the expedition to the computer vision application and takes background subtraction, a part of video surveillance, to prove that our generalization broadens the feasibility of MapReduce.



















Similar content being viewed by others
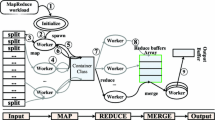

References
(1999) http://hadoop.apache.org/
Afrati, F.N., Sarma, A.D., Menestrina, D., Parameswaran, A., Ullman, J.D.: Fuzzy joins using mapreduce. In: Proceedings of the 2012 IEEE 28th international conference on data engineering, IEEE Computer Society, Washington, DC, USA, ICDE ’12, pp 498–509. doi:10.1109/ICDE.2012.66 (2012a)
Afrati, F.N., Sarma, A.D., Salihoglu, S., Ullman, J.D.: Vision paper: towards an understanding of the limits of map-reduce computation. CoRR arXiv:1204.1754 (2012b)
Akidau, T., Balikov, A., Bekiroglu, K., Chernyak, S., Haberman, J., Lax, R., McVeety, S., Mills, D., Nordstrom, P., Whittle, S. MillWheel: Fault-tolerant stream processing at internet scale. In: Proceedings of the 39th International Conference on Very Large Data Bases (VLDB), pp. 734–746 (2013)
Chambers, C., Raniwala, A., Perry, F., Adams, S., Henry, R.R., Bradshaw, R., Weizenbaum, N.: FlumeJava: easy, efficient data-parallel pipelines. In: Proceedings of the 2010 ACM SIGPLAN Conference on Programming Language Design and Implementation, ACM, New York, NY, USA, PLDI ’10, pp. 363–375 (2010)
Chen, Q., Liu, C., Xiao, Z.: Improving mapreduce performance using smart speculative execution strategy. IEEE Trans. Comput. 63(4), 954–967 (2014)
Dean, J., Ghemawat, S.: MapReduce: simplified data processing on large clusters. In: Proceedings of the 6th Conference on Symposium on Opearting Systems Design and Implementation—Volume 6, USENIX Association, Berkeley, CA, USA, OSDI’04, p. 10 (2004)
Dean, J., Ghemawat, S.: MapReduce: a flexible data processing tool. Commun. ACM 53(1), 72–77 (2010). doi:10.1145/1629175.1629198
Fadika, Z., Govindaraju, M.: DELMA: dynamically elastic mapreduce framework for CPU-intensive applications. In: IEEE International Symposium on Cluster Computing and the Grid, pp. 454–463 (2011). doi:10.1109/CCGrid.2011.71
Halim, F., Yap, RHC., Wu, Y.: A mapreduce-based maximum-flow algorithm for large small-world network graphs. In: Proceedings of the 2011 31st International Conference on Distributed Computing Systems. IEEE Computer Society, Washington, DC, USA, ICDCS ’11, pp. 192–202 (2011). doi:10.1109/ICDCS.2011.62
Hongsakham, W., Pattara-Atikom, W., Peachavanish, R.: Estimating road traffic congestion from cellular handoff information using cell-based neural networks and k-means clustering. In: Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, 2008. ECTI-CON 2008. 5th International Conference on, vol 1, pp. 13–16 (2008)
Ibrahim, S., Jin, H., Lu, L., He, B., Antoniu. G., Wu, S.: Maestro: replica-aware map scheduling for mapreduce. In: Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid 2012), IEEE Computer Society, Washington, DC, USA, CCGRID ’12, pp. 435–442. doi:10.1109/CCGrid.2012.122 (2012)
Jiang, D., Ooi, B.C., Shi, L., Wu, S.: The performance of MapReduce: an in-depth study. Proc. VLDB Endow. 3(1–2), 472–483 (2010)
Jin, H., Yang, X., Sun, X.H., Raicu, I.: ADAPT: availability-aware mapreduce data placement for non-dedicated distributed computing. In: 2012 IEEE 32nd International Conference on Distributed Computing Systems (ICDCS), pp. 516–525 (2012). doi:10.1109/ICDCS.2012.48
Karloff, H., Suri, S., Vassilvitskii, S.: A model of computation for mapreduce. In: Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, SODA ’10, pp. 938–948 (2010)
Kavulya, S., Tan, J., Gandhi, R., Narasimhan, P.: An analysis of traces from a production mapreduce cluster. In: Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, IEEE Computer Society, Washington, DC, USA, CCGRID ’10, pp. 94–103 (2010). doi:10.1109/CCGRID.2010.112
Li, S., Hu, S., Wang, S., Su, L., Abdelzaher, T.F., Gupta, I., Pace, R.: WOHA: Deadline-Aware Map-Reduce Workflow Scheduling Framework over Hadoop Clusters. In: IEEE 34th International Conference on Distributed Computing Systems, ICDCS 2014, Madrid, Spain, June 30–July 3, 2014, pp. 93–103 (2014)
Lim, H., Herodotou, H., Babu, S.: Stubby: A Transformation-Based Optimizer for MapReduce Workflows, vol. 5, 11th edn, pp. 1196–1207 (2012)
Lin, J., Dyer, C.: Data-Intensive Text Processing with MapReduce. Morgan and Claypool Publishers, San Rafael, CA (2010)
Lin, J., Bahety, A., Konda, S., Mahindrakar, S.: Low-latency, high-throughput access to static global resources within the hadoop framework. Tech. Rep. HCIL-2009-01, University of Maryland, College Park, Maryland (2009)
Liu, H., Orban, D.: Cloud MapReduce: a mapreduce implementation on top of a cloud operating system. In: IEEE International Symposium on Cluster Computing and the Grid, pp 464–474 (2011). doi:10.1109/CCGrid.2011.25
Natrella, M.: NIST/SEMATECH e-Handbook of Statistical Methods. NIST/SEMATECH, http://www.itl.nist.gov/div898/handbook/ (2010)
Nykiel, T., Potamias, M., Mishra, C., Kollios, G., Koudas, N.: Sharing across multiple mapreduce jobs. ACM Trans. Database Syst. 39(2), 12:1–12:46 (2014)
Pavlo, A., Paulson, E., Rasin, A., Abadi, D.J., DeWitt, D.J., Madden, S., Stonebraker, M.: A comparison of approaches to large-scale data analysis. In: SIGMOD ’09: Proceedings of the 35th SIGMOD International Conference on Management of Data, ACM, New York, NY, USA, pp. 165–178 (2009). doi:10.1145/1559845.1559865
Piccardi, M.: Background subtraction techniques: a review. In: 2004 IEEE International Conference on Systems, Man and Cybernetics, vol. 4, pp. 3099–3104 (2004). doi:10.1109/ICSMC.2004.1400815
Ranganathan, K., Foster, I.: Decoupling computation and data scheduling in distributed data-intensive applications. In: High Performance Distributed Computing, 2002. HPDC-11 2002. Proceedings. 11th IEEE International Symposium on, pp. 352–358 (2002). doi:10.1109/HPDC.2002.1029935
Stauffer, C., Grimson, W.E.L.: Adaptive background mixture models for real-time tracking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (1999)
Stonebraker, M., Abadi, D., DeWitt, D.J., Madden, S., Paulson, E., Pavlo, A., Rasin, A.: MapReduce and parallel DBMSs: friends or foes? Commun. ACM 53(1), 64–71 (2010). doi:10.1145/1629175.1629197
Stuart, J.A., Chen, C.K., Ma, K.L., Owens, J.D.: Multi-GPU volume rendering using mapreduce. In: Hariri, S., Keahey, K. (eds) Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, HPDC 2010, Chicago, Illinois, USA, June 21–25, 2010, ACM, pp. 841–848 (2010). doi:10.1145/1851476.1851597
Takalo, R., Hytti, H., Ihalainen, H.: Tutorial on univariate autoregressive spectral analysis. J. Clin. Monit. Comput. 19(6), 401–410 (2005). doi:10.1007/s10877-005-7089-x
Tan, J., Kavulya, S., Gandhi, R., Narasimhan, P.: Visual, log-based causal tracing for performance debugging of mapreduce systems. In: Proceedings of the 2010 IEEE 30th International Conference on Distributed Computing Systems, IEEE Computer Society, Washington, DC, USA, ICDCS ’10, pp. 795–806 (2010). doi:10.1109/ICDCS.2010.63
Tang, Z., Liu, M., Ammar, A., Li, K., Li, K.: An optimized MapReduce workflow scheduling algorithm for heterogeneous computing. J. Supercomput. 72(6), 2059–2079 (2016)
Vu, T.T., Huet, F.: A lightweight continuous jobs mechanism for mapreduce frameworks. In: IEEE International Symposium on Cluster Computing and the Grid, pp. 269–276 (2013). doi:10.1109/CCGrid.2013.36
White, B., Yeh, T., Lin, J., Davis, L.: Web-scale Computer Vision Using MapReduce for Multimedia Data Mining. In: Proceedings of the Tenth International Workshop on Multimedia Data Mining, ACM, New York, NY, USA, MDMKDD ’10 (2010). doi:10.1145/1814245.1814254
Yan, C., Yang, X., Yu, Z., Li, M., Li, X.: IncMR: incremental data processing based on mapreduce. In: 2012 IEEE Fifth International Conference on Cloud Computing, pp. 534–541 (2012). doi:10.1109/CLOUD.2012.67
Zaharia, M., Borthakur, D., Sen Sarma, J., Elmeleegy, K., Shenker, S., Stoica, I.: Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling. In: Proceedings of the 5th European conference on Computer Systems, ACM, New York, NY, USA, EuroSys ’10, pp. 265–278 (2010). doi:10.1145/1755913.1755940
Acknowledgments
This research was supported by Grant Number NSC 102-2221-E-001-019 and MOST 103-2221-E-001-035 from the Taiwan National Science Council.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wu, HH., Wang, CM. Generalization of Large-Scale Data Processing in One MapReduce Job for Coarse-Grained Parallelism. Int J Parallel Prog 45, 797–826 (2017). https://doi.org/10.1007/s10766-016-0444-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-016-0444-3