
Abstract
In this paper, we present a new approach of speech clustering with regards of the speaker identity. It consists in grouping the homogeneous speech segments that are obtained at the end of the segmentation process, by using the spatial information provided by the stereophonic speech signals. The proposed method uses the differential energy of the two stereophonic signals collected by two cardioid microphones, in order to cluster all the speech segments that belong to the same speaker. The total number of clusters obtained at the end should be equal to the real number of speakers present in the meeting room and each cluster should contain the global intervention of only one speaker. The proposed system is suitable for debates or multi-conferences for which the speakers are located at fixed positions.
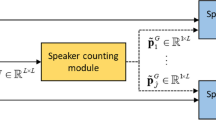
Basically, our approach tries to make a speaker localization with regards to the position of the microphones, taken as a spatial reference. Based on this localization, the new proposed method can recognize the speaker identity of any speech segment during the meeting. So, the intervention of each speaker is automatically detected and assigned to him by estimating his relative position.
In a purpose of comparison, two types of clustering methods have been implemented and experimented: the new approach, which we called Energy Differential based Spatial Clustering (EDSC) and a classical statistical approach called “Mono-Gaussian based Sequential Clustering” (MGSC).
Experiments of speaker clustering are done on a stereophonic speech corpus called DB15, composed of 15 stereophonic scenarios of about 3.5 minutes each. Every scenario corresponds to a free discussion between two or three speakers seated at fixed positions in the meeting room.
Results show the outstanding performances of the new approach in terms of precision and speed, especially for short speech segments, where most of clustering techniques present a strong failure.






Similar content being viewed by others


References
Ajmera, J., Bourlard, H., & Lapidot, I. (2002). Improved unknown-multiple speaker clustering using HMM (Technical report). IDIAP.
Ajmera, J., Lathoud, G., & McCowan, I. (2004). Clustering and segmenting speakers and their locations in meetings. ICASSP Proceedings, 1, 605–608.
Barras, C., Zhu, X., Meignier, S., & Gauvain, J.-L. (2004). Improving speaker diarization. In Proc. fall rich transcription workshop (RT-04), Palisades, NY, Nov. 2004.
Ben, M., Betser, M., Bimbot, F., & Gravier, G. (2004). Speaker diarization using bottom-up clustering based on a parameter-derived distance between adapted GMMs. In Proceedings of the international conference on spoken language processing (ICSLP4), Jeju Islands, South Korea, October 2004.
Bimbot, F., Magrin-Chagnolleau, I., & Mathan, L. (1995). Second-order statistical measures for text-independent broadcaster identification. Speech Communication, 17(1–2), 177–192.
Bjor, O. H., Enger, J., & Winsvold, B. (2001). Sound intensity for identification of aircraft noise. In Inter-noise proceedings, international congress and exhibition on noise control engineering.
Bonastre, J. F., & Besacier, L. (1997). Traitement indépendant de sous-bandes fréquentielles par des méthodes statistiques du second ordre pour la reconnaissance du locuteur. In Actes du 4ème congrès Français d’Acoustique, Marseille, France, 14–18 April 1997 (pp. 357–360).
Chen, S. S., & Gopalakrishnan, P. (1998). Clustering via the Bayesian information criterion with applications in speech recognition. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’1998, Seattle, USA (Vol. 2, pp. 645–648).
Delacourt, P., & Wellekens, C. J. (2000). DISTBIC: a speaker-based segmentation for audio data indexing. Speech Communication, 32, 111–126.
Gish, H., Siu, M.-H., & Rohlicek, R. (1991). Segregation of speakers for speech recognition and speaker identification. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’1991, Toronto, Canada (Vol. 2, pp. 873–876).
Istrate, F., Fredouille, C., Meignier, S., Besacier, L., & Bonastre, J.-F. (2005). Pre-processing techniques and speaker diarization on multiple microphone meetings. In NIST rich transcription 2005 spring meeting recognition evaluation (RT’05S), Lecture notes in computer sciences (LNCS), Edinburgh, Scotland. Berlin: Springer.
Jacobsen, F. (2002). Sound intensity and its measurement and applications. Acoustic Technology, Technical, University of Denmark, Lyngby, Denmark. Note Number 2216.
Jin, H., Kubala, F., & Schwartz, R. (1997). Automatic speaker clustering. In DARPA speech recognition workshop, Chantilly, USA (pp. 108–111).
Jin, Q., Laskowski, K., Schultz, T., & Waibel, A. (2004). Speaker segmentation and clustering in meetings. In NIST 2004 spring rich transcription evaluation workshop, Montreal, Canada.
Johnson, S., & Woodland, P. (1998). Speaker clustering using direct maximization of the MLLRadapted likelihood. In Proc. international conference on speech and language processing, Sydney, Australia, Dec. 1998 (Vol. 5, pp. 1775–1779).
Koh, E. C., Sun, H., Nwe, T. L., Nguyen, T. H., Ma, B., Chng, E.-S., Li, H., & Rahardja, S. (2008). Speaker diarization using direction of arrival estimate and acoustic feature information, the I2R-NTU submission. In NIST RT 2007 evaluation in multimodal technologies for perception of humans (pp. 484–496). Berlin/Heidelberg: Springer.
Magrin-Chagnolleau, I., Bonastre, J. F., & Bimbot, F. (1995). Effect of utterance duration and phonetic content on speaker identification using second-order statistical methods. In Proceedings of EUROSPEECH 95, Madrid, Spain, September 1995 (Vol. 1, pp. 337–340).
Meignier, S. (2002). Indexation en locuteurs de documents sonores: segmentation d’un document et appariement d’une collection. PhD Thesis, Laboratoire Informatique d’Avignon (LIA), Université d’Avignon et des Pays de Vaucluse, Avignon (France).
Moh, Y., Nguyen, P., & Junqua, J.-C. (2003). Towards domain independent speaker clustering. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’2003, Hong Kong, China (pp. 85–88).
Mori, K., & Nakagawa, S. (2001). Speaker change detection and speaker clustering using VQ distortion for broadcast news speech recognition. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’2001, Salt Lake City, USA (pp. 413–416).
Nakagawa, S., & Suzuki, H. (1993). A new speech recognition method based on VQ-distortion and HMM. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’1993, Minneapolis, USA (pp. 676–679).
Ouamour, S., & Sayoud, H. (2009). A new approach for speaker change detection using a fusion of different classifiers and a new relative characteristic. The Mediterranean Journal of Computers and Networks, 5(3), 104–113. ISSN:1744-2400
Ouamour, S., & Sayoud, H. (2012). A pertinent learning machine input feature for speaker discrimination by voice. International Journal of Speech Technology, 15, 181–190.
Reynolds, D. A., & Torres-Carrasquillo, P. (2004). The MIT Lincoln laboratories RT-04F diarization systems: applications to broadcast audio and telephone conversations. In Rich transcription workshop (RTW’04), Palisades, NY.
Reynolds, D. A., Singer, E., Carlson, B. A., O’Leary, G. C., McLaughlin, J. J., & Zixxman, M. A. (1998). Blind clustering of speech utterances based on speaker and language characteristics. In Proc. international conference on speech and language processing, Sidney, Australia.
Rougui, J., Rziza, M., Aboutajdine, D., Gelgon, M., & Martinez, J. (2006). Fast incremental clustering of Gaussian mixture speaker models for scaling up retrieval in on-line broadcast. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’2006, Toulouse, France (Vol. 5).
Sayoud, H., Ouamour, S., & Boudraa, M. (2003). ‘ASTRA’ an automatic speaker tracking system based on SOSM measures and an interlaced indexation. Acta Acustica, 89(4), 702–710.
Sayoud, H., Ouamour, S., & Khennouf, S. (2011). Automatic speaker tracking by camera using two-channel-based sound source localization. International Journal of Intelligent Computing and Cybernetics, 4(1), 40–60.
Schutte, K., & Glass, J. (2007) Features and classifiers for robust automatic speech recognition. In Research abstracts—2007, research project. MIT CSAIL publications and digital archives.
Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6, 461–464.
Singer, E., Torres-Carrasquillo, P., Reynolds, D., McCree, A., Richardson, F., Dehak, N., & Sturim, D. (2012). The MITLL NIST LRE 2011 language recognition system. In Odyssey workshop on speaker and language recognition, Singapore, 26 June 2012.
Siu, M.-H., Yu, G., & Gish, H. (1992). An unsupervised, sequential learning algorithm for the segmentation of speech waveforms with multiple speakers. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’1992, San Francisco, USA (Vol. 2, pp. 189–192).
Solomonov, A., Mielke, A., Schmidt, M., & Gish, H. (1998). Clustering speakers by their voices. In Proc. IEEE international conference on acoustics, speech and signal processing, ICASSP’1998, Seattle, USA (Vol. 2, pp. 757–760).
Tranter, S., & Reynolds, D. (2004). Speaker diarisation for broadcast news. In Proc. ISCA Odyssey 2004 workshop on speaker and language recognition, Toledo, June 2004.
Valente, F. (2005). Variational Bayesian methods for audio indexing. PhD Thesis, Université de Nice-Sophia Antipolis.
Valente, F., & Wellekens, C. J. (2004). Variational Bayesian speaker clustering. In Odyssey’2004, the speaker and language recognition workshop, Toledo, Spain (pp. 207–214).
Valente, F., Motlicek, P., & Vijayasenan, D. (2010). Variational Bayesian speaker diarization of meeting recordings. In Proceedings of the IEEE international conference on acoustics, speech, and signal processing, ICASSP’2010, Dallas, Texas, USA (pp. 4954–4957).
Vijayasenan, D., Valente, F., & Bourlard, H. (2008). Combination of agglomerative and sequential clustering for speaker diarization. In IEEE int. conf. on acoustics, speech, and signal processing (ICASSP).
Wang, W., Lv, P., Zhao, Q., & Yan, Y. (2007). A decision-tree-based online speaker clustering. In Proceedings of the 3rd Iberian conference on pattern recognition and image analysis, Girona, Spain (pp. 555–562).
Wang, H., Zhang, X., Suo, H., Zhao, Q., & Yan, Y. (2009). A novel fuzzy-based automatic speaker clustering algorithm. In Proceedings of the 6th international symposium on neural networks: advances in neural networks, China section: clustering and classification, Wuhan (pp. 639–646).
Xavier, A. M. (2006). Robust speaker diarization for meetings. PhD Thesis, Speech Processing Group Department of Signal Theory and Communications Universitat Politecnica de Catalunya Barcelona (Espagnol), October 2006.
Zhou, B., & Hansen, J. H. (2000). Unsupervised audio stream segmentation and clustering via the Bayesian information criterion. In Proc. international conference on speech and language processing, Beijing, China (Vol. 3, pp. 714–717).
Žibert, J., & Mihelič, F. (2009). Fusion of acoustic and prosodic features for speaker clustering. In Proceedings of the 12th international conference on text, speech and dialogue, Pilsen, Czech Republic (pp. 210–217).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ouamour, S., Sayoud, H. A new approach of speaker clustering based on the stereophonic differential energy. Int J Speech Technol 16, 513–523 (2013). https://doi.org/10.1007/s10772-013-9199-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-013-9199-z