
Abstract
Computing sparse representation (SR) over an exemplar dictionary is time consuming and computationally expensive for large dictionary size. This also requires huge memory requirement for saving the dictionary. In order to reduce the latency and to achieve some diversity, ensemble of exemplar dictionary based language identification (LID) system is explored. The full diversity can be obtained if each of the exemplar dictionary contains only one feature vector from each of the language class. To achieve full diversity, a large number of multiple dictionaries are required; thus needs to compute SR for a particular test utterance as many times. The other solution to reduce the latency is to use a learned dictionary. The dictionary may contain unequal number of dictionary atoms and it is not guaranteed that each language class information is present. It totally depends upon the number of data and its variations. Motivated by this, language specific dictionary is learned, and then concatenated to form a single learned dictionary. Furthermore, to overcome the problem of ensemble exemplar dictionary based LID system, we investigated the ensemble of learned-exemplar dictionary based LID system. The proposed approach achieves the same diversity and latency as that of ensemble exemplar dictionary with reduced number of learned dictionaries. The proposed techniques are applied on two spoken utterance representations: the i-vector and the JFA latent vector. The experiments are performed on 2007 NIST LRE, 2009 NIST LRE and AP17-OLR datasets in closed set condition.










Similar content being viewed by others
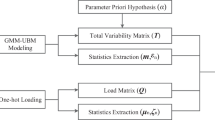

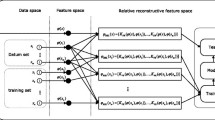
References
Aharon, M., Elad, M., & Bruckstein, A. (2006). K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing, 54(11), 4311–4322.
Ambikairajah, E., Li, H., Wang, L., Yin, B., & Sethu, V. (2011). Language identification: A tutorial. IEEE Circuits and Systems Magazine, 11(2), 82–108.
Brummer, N. (2007). Focal multi-class: Toolkit for evaluation, fusion and calibration of multi-class recognition scores—tutorial and user manual. http://sites.google.com/site/nikobrummer/focalmulticlass.
Davis, S., & Mermelstein, P. (1980). Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, and Signal Processing, 28(4), 357–366.
Dehak, N., Torres-Carrasquillo, P. A., Reynolds, D., & Dehak, R. (2011). Language recognition via i-vectors and dimensionality reduction. In: Proceedings of Interspeech (pp. 857–860).
Dehak, N., Kenny, P., Dehak, R., Dumouchel, P., & Ouellet, P. (2011). Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech and Language, 19(4), 788–798.
Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 39, 1–38.
Haris B.C., & Sinha, R. (2012) Speaker verification using sparse representation over ksvd learned dictionary. In: Proceedings of National Conference on Communications (NCC) (pp. 1–5).
Haris, B. C., & Sinha, R. (2015). Robust speaker verification with joint sparse coding over learned dictionaries. IEEE Transactions on Information Forensics and Security, 10(10), 2143–2157.
Hatch, A.O., Kajarekar, S., & Stolcke, A. (2006). Within-class covariance normalization for svm-based speaker recognition. In: Proceedings of the ICSLP (pp. 1471–1474).
Hermansky, H., & Morgan, N. (1994). Rasta processing of speech. IEEE Transactions on Speech and Audio Processing, 2(4), 578–589.
Ho, T. K. (1998). The random subspace method for constructing decision forests. IEEE Transactions on Pattern Analysis and Machine, 20(8), 832–844.
Jiang, B., Song, Y., Guo, W., & Dai, L.R. (2012). Exemplar-based sparse representation for language recognition on i-vectors. In: Proceedings of ISCA Interspeech.
Kenny, P. (2010). Bayesian speaker verification with heavy-tailed priors. In: Odyssey, p. 14.
Kenny, P., Boulianne, G., & Dumouchel, P. (2005). Eigenvoice modeling with sparse training data. IEEE Transactions on Speech and Audio Processing, 13(3), 345–354.
Kenny, P., Boulianne, G., Ouellet, P., & Dumouchel, P. (2007). Joint factor analysis versus eigenchannels in speaker recognition. IEEE Transactions on Audio Speech and Language Processing, 15(4), 1435–1447.
Kua, J., Ambikairajah, E., Epps, J., & Togneri, R. (2011). Speaker verification using sparse representation classification. In: Proceedings of IEEE ICASSP (pp. 4548–4551).
Mairal, J., Bach, F., Ponce, J., & Sapiro, G. (2010). Online learning for matrix factorization and sparse coding. Journal of Machine Learning Research, 11(Jan), 19–60.
Martinez, D., Plchot, O., Burget, L., Glembek, O., & Matejka, P. (2011). Language recognition in i-vectors space. In: Proceedings of Interspeech (pp. 861–864).
Naseem, I., Togneri, R., & Bennamoun, M. (2010). Sparse representation for speaker identification. In: Proceedings of the 20th International Conference on Pattern Recognition (ICPR) (pp. 4460–4463).
Ng, A.Y. (2004). Feature selection, l 1 vs. l 2 regularization, and rotational invariance. In: Proceedings of the Twenty-first International Conference on Machine Learning, p. 78. ACM.
Pati, Y.C., Rezaiifar, R., & Krishnaprasad, P.S. (1993). Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition. In: Proceedings of 27th Asilomar Conference Signals, Systems and Computers, Pacific Grove, CA (vol. 1, pp. 40–44). https://doi.org/10.1109/ACSSC.1993.342465.
Prince, S.J., & Elder, J.H. (2007). Probabilistic linear discriminant analysis for inferences about identity. In: IEEE 11th International Conference on Computer Vision, 2007. ICCV 2007 (pp. 1–8). IEEE.
Roach, P., Arnfield, S., Barry, W., Baltova, J., Boldea, M., Fourcin, A., Gonet, W., Gubrynowicz, R., Hallum, E., Lamel, L., et al. (1996). Babel: An eastern european multi-language database. In: Proceedings of Fourth International Conference On Spoken Language, 1996. ICSLP 96 (vol. 3, pp. 1892–1893). IEEE.
Singh, O.P., Haris B.C., & Sinha, R. (2013). Language identification using sparse representation: A comparison between gmm supervector and i-vector based approaches. In: Proceedings of Annual IEEE India Conference (INDICON) (pp. 1–4).
Singh, O.P., & Sinha, R. (2017). Sparse representation classification based language recognition using elastic net. In: 2017 4th International Conference on Signal Processing and Integrated Networks (SPIN).
Tang, Z., Wang, D., Chen, Y., & Chen, Q. (2017). Ap17-olr challenge: Data, plan, and baseline. CoRR arXiv:abs/1706.09742.
Tang, Z., Wang, D., Chen, Y., Li, L., & Abel, A. (2017). Phonetic temporal neural model for language identification. arXiv preprint arXiv:1705.03151.
The 2007 NIST Language Recognition Evaluation Plan. (2007). http://www.itl.nist.gov/iad/mig//tests/lre/2007/LRE07EvalPlan-v8b.pdf. Accessed 28 Feb 2015.
The 2009 NIST Language Recognition Evaluation Plan. (2009). http://www.itl.nist.gov/iad/mig//tests/lre/2009/LRE09EvalPlan-v6.pdf. Accessed 5 July 2016.
Torres-Carrasquillo, P.A., Singer, E., Kohler, M.A., Greene, R.J., Reynolds, D.A., & Deller, Jr., J.R. (2002). Approaches to language identification using gaussian mixture models and shifted delta cepstal features. In: Proceedings of ICSLP.
Vapnik, V. (2013). The nature of statistical learning theory. Berlin: Springer.
Viikki, O., & Laurila, K. (1998). Cepstral domain segmental feature vector normalization for noise robust speech recognition. Speech Communication, 25(1), 133–147.
Wang, D., & Zhang, X. (2015). Thchs-30 : A free chinese speech corpus. http://arxiv.org/abs/1512.01882.
Wright, J., Yang, A., Ganesh, A., Sastry, S., & Ma, Y. (2009). Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(2), 210–227.
Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(2), 301–320.
Acknowledgements
The authors would like to thank the linguistic data consortium (LDC) for providing the LDC2014S06 2009 NIST LRE test set under LDC Spring 2016 data scholarships program.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Singh, O.P., Sinha, R. Sparse coding of i-vector/JFA latent vector over ensemble dictionaries for language identification systems. Int J Speech Technol 21, 435–450 (2018). https://doi.org/10.1007/s10772-017-9476-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-017-9476-3