
Abstract
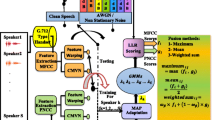
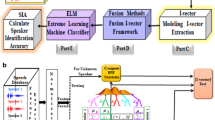
In this work, a speaker identification system is proposed which employs two feature extraction models, namely: the power normalized cepstral coefficients and the mel frequency cepstral coefficients. Both features are subjected to acoustic modeling using a Gaussian mixture model–universal background model. The purpose of this work is to provide a thorough evaluation of the effect of different types of noise on the speaker identification accuracy (SIA) and thereby providing benchmark figures for future comparative studies. In particular, the additive white Gaussian noise and eight non-stationary noise types (with and without the G.712 type handset) corresponding to various signal to noise ratios are tested. Fusion strategies are also employed using late fusion methods: maximum, weighted sum, and mean fusion. The measurements of randomly selected 120 speakers from the TIMIT database are employed and the SIA is used to measure the system performance. The weighted sum fusion resulted in the best performance in terms of SIA with noisy speech. The proposed model given in this work and its related analysis paves the way for further work in this important area.








Similar content being viewed by others

References
Abdullah, M.A., Chambers, J.A., Woo, W.L., & Dlay, S.S. (2015). Iris biometrie: Is the near-infrared spectrum always the best? In: 2015 IEEE 3rd IAPR Asian conference on pattern recognition (ACPR) (pp. 816–819). IEEE.
Al-Kaltakchi, M.T., Woo, W.L., Dlay, S.S., & Chambers, J.A. (2016). Study of statistical robust closed set speaker identification with feature and score-based fusion. In: 2016 IEEE statistical signal processing workshop (SSP) (pp. 1–5). IEEE.
Al-Kaltakchi, M.T., Woo, W.L., Dlay, S.S., & Chambers, J.A. (2017). Speaker identification evaluation based on the speech biometric and i-vector model using the timit and ntimit databases. In: 2017 IEEE 5th international workshop on biometrics and forensics (IWBF) (pp. 1–6). IEEE.
Al-Kaltakchi, M. T., Woo, W. L., Dlay, S., & Chambers, J. A. (2017). Evaluation of a speaker identification system with and without fusion using three databases in the presence of noise and handset effects. EURASIP Journal on Advances in Signal Processing, 2017(1), 80.
Al-Nima, R. R. O., Abdullah, M. A., Al-Kaltakchi, M. T., Dlay, S. S., Woo, W. L., & Chambers, J. A. (2017). Finger texture biometric verification exploiting multi-scale sobel angles local binary pattern features and score-based fusion. Digital Signal Processing, 70, 178–189.
Alkassar, S., Woo, W. L., Dlay, S. S., & Chambers, J. A. (2015). Robust sclera recognition system with novel sclera segmentation and validation techniques. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(3), 474–486.
Chaki, J., Dey, N., Shi, F., & Sherratt, R. S. (2019). Pattern mining approaches used in sensor-based biometric recognition: A review. IEEE Sensors Journal, 19(10), 3569–3580.
Chin, Y. H., Wang, J. C., Huang, C. L., Wang, K. Y., & Wu, C. H. (2017). Speaker identification using discriminative features and sparse representation. IEEE Transactions on Information Forensics and Security, 12(8), 1979–1987.
El-Ouahabi, S., Atounti, M., & Bellouki, M. (2019). Toward an automatic speech recognition system for amazigh-tarifit language. International Journal of Speech Technology, 22(2), 421–432. https://doi.org/10.1007/s10772-019-09617-6.
Faragallah, O. S. (2018). Robust noise MKMFCC-SVM automatic speaker identification. International Journal of Speech Technology, 21(2), 185–192.
Hasan, T., & Hansen, J. H. (2011). A study on universal background model training in speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(7), 1890–1899.
Hezil, N., & Boukrouche, A. (2017). Multimodal biometric recognition using human ear and palmprint. IET Biometrics, 6(5), 351–359.
Kim, C., & Stern, R. M. (2016). Power-normalized cepstral coefficients (PNCC) for robust speech recognition. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 24(7), 1315–1329.
Kumari, R. S. S., Nidhyananthan, S. S., et al. (2012). Fused mel feature sets based text-independent speaker identification using gaussian mixture model. Procedia Engineering, 30, 319–326.
Ma, Z., Yu, H., Tan, Z. H., & Guo, J. (2016). Text-independent speaker identification using the histogram transform model. IEEE Access, 4, 9733–9739.
Ming, J., Hazen, T. J., Glass, J. R., & Reynolds, D. A. (2007). Robust speaker recognition in noisy conditions. IEEE Transactions on Audio, Speech, and Language Processing, 15(5), 1711–1723.
Morales, A., Morocho, D., Fierrez, J., & Vera.Rodriguez, R. (2017). Signature authentication based on human intervention: Performance and complementarity with automatic systems. IET Biometrics, 6(4), 307–315.
Nijhawan, G., & Soni, M. (2013). A new design approach for speaker recognition using MFCC and VAD. International Journal of Image Graphics Signal Process (IJIGSP), 5(9), 43–49.
Rajeswari, P., Raju, S.V., Ashour, A.S., & Dey, N. (2017). Multi-fingerprint unimodel-based biometric authentication supporting cloud computing. In: Intelligent techniques in signal processing for multimedia security (pp. 469–485). New York: Springer.
Sghaier, S., Farhat, W., & Souani, C. (2018). Novel technique for 3d face recognition using anthropometric methodology. International Journal of Ambient Computing and Intelligence (IJACI), 9(1), 60–77.
Sun, L., Gu, T., Xie, K., & Chen, J. (2019). Text-independent speaker identification based on deep gaussian correlation supervector. International Journal of Speech Technology, 22(2), 449–457. https://doi.org/10.1007/10772-019-09618-5.
Tazi, E.B., El-Makhfi, N. (2017). An hybrid front-end for robust speaker identification under noisy conditions. In: IEEE 2017 Intelligent Systems Conference (IntelliSys) (pp. 764–768).
Togneri, R., & Pullella, D. (2011). An overview of speaker identification: Accuracy and robustness issues. IEEE Circuits and Systems Magazine, 11(2), 23–61.
Univaso, P. (2017). Forensic speaker identification: A tutorial. IEEE Latin America Transactions, 15(9), 1754–1770.
Verma, P., & Das, P. K. (2015). i-vectors in speech processing applications: A survey. International Journal of Speech Technology, 18(4), 529–546.
Yadav, I. C., Shahnawazuddin, S., & Pradhan, G. (2019). Addressing noise and pitch sensitivity of speech recognition system through variational mode decomposition based spectral smoothing. Digital Signal Processing, 86, 55–64.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Al-Kaltakchi, M.T.S., Al-Nima, R.R.O., Abdullah, M.A.M. et al. Thorough evaluation of TIMIT database speaker identification performance under noise with and without the G.712 type handset. Int J Speech Technol 22, 851–863 (2019). https://doi.org/10.1007/s10772-019-09630-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-019-09630-9