
Abstract
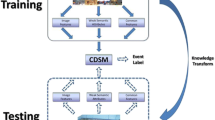
In this paper, we propose an approach of inferring the labels of unlabeled consumer videos and at the same time recognizing the key segments of the videos by learning from Web image sets for video annotation. The key segments of the videos are automatically recognized by transferring the knowledge learned from related Web image sets to the videos. We introduce an adaptive latent structural SVM method to adapt the pre-learned classifiers using Web image sets to an optimal target classifier, where the locations of the key segments are modeled as latent variables because the ground-truth of key segments are not available. We utilize a limited number of labeled videos and abundant labeled Web images for training annotation models, which significantly alleviates the time-consuming and labor-expensive collection of a large number of labeled training videos. Experiment on the two challenge datasets Columbia’s Consumer Video (CCV) and TRECVID 2014 Multimedia Event Detection (MED2014) shows our method performs better than state-of-art methods.






Similar content being viewed by others


References
Baktashmotlagh M, Harandi MT, Lovell BC, Salzmann M (2013) Unsupervised domain adaptation by domain invariant projection. In: Computer Vision (ICCV), 2013 IEEE International Conference on, pp. 769–776. IEEE
Bhattacharya S, Yu FX, Chang SF (2014) Minimally needed evidence for complex event recognition in unconstrained videos. In: Proceedings of International Conference on Multimedia Retrieval, International Conference on Multimedia Retrieval, pp. 105:105–105:112, numpages = 8
Bianco S, Ciocca G, Napoletano P, Schettini R (2015) An interactive tool for manual, semi-automatic and automatic video annotation. Comput Vis Image Underst 131:88–99
Blank M, Gorelick L, Shechtman E, Irani M, Basri R (2005) Actions as space-time shapes. In: International Conference on Computer Vision, vol. 2, pp. 1395–1402. IEEE
Bruzzone L, Marconcini M (2010) Domain adaptation problems: A dasvm classification technique and a circular validation strategy. Pattern Recogn Mach Intell 32(5):770–787
Chen L, Duan L, Xu D, Xu D (2013) Event recognition in videos by learning from heterogeneous web sources. In: Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pp. 2666–2673. IEEE
Cheng WH, Chuang YY, Lin YT, Hsieh CC, Fang SY, Chen BY, Wu JL (2008) Semantic analysis for automatic event recognition and segmentation of wedding ceremony videos. IEEE Transactions on Circuits and Systems for Video Technology 1639–1650
Divakaran A, Javed O, Ali S, Sawhney H, Yu Q, Liu J, Cheng H, Tamrakar A (2013) Video event recognition using concept attributes. In: IEEE Winter Conference on Applications of Computer Vision, pp 339–346
Do TMT, Artières T (2009) Large margin training for hidden markov models with partially observed states. In: International Conference on Machine Learning, pp. 265–272. ACM
Duan L, Xu D, fu Chang S (2012) Exploiting web images for event recognition in consumer videos: A multiple source domain adaptation approach. In: Computer Vision and Pattern Recognition
Duan L, Xu D, Tsang IWH (2012) Domain adaptation from multiple sources: A domain-dependent regularization approach. IEEE Trans Neural Netw Learn Syst 23(3):504–518
Fang M, Guo Y, Zhang X, Li X (2015) Multi-source transfer learning based on label shared subspace. Pattern Recogn Lett 51:101–106
Habibian A, Snoek CG (2014) Recommendations for recognizing video events by concept vocabularies. Comput Vis Image Underst 124:110–122
Ikizler-Cinbis N, Cinbis R, Sclaroff S (2009) Learning actions from the web. In: International Conference on Computer Vision, pp 995–1002
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: Convolutional architecture for fast feature embedding. arXiv preprint. 1408:5093
gang Jiang Y, Ye G, fu Chang S, Ellis D, Loui EC (2011) Consumer video understanding: A benchmark database and an evaluation of human and machine performance. In: International Conference on Multimedia Retrieval, p. 29
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: NIPS, pp. 1097–1105
Li W, Duan L, Xu D, Tsang IW (2014) Learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation. IEEE Trans Pattern Anal Mach Intell 36(6):1134–1148
Li W, Yu Q, Sawhney H, Vasconcelos N (2013) Recognizing activities via bag of words for attribute dynamics. In: Computer Vision and Pattern Recognition, pp 2587–2594
Long M, Wang J, Ding G, Pan SJ, et al. (2014) Adaptation regularization: A general framework for transfer learning. IEEE Trans Knowl Data Eng 26(5):1076–1089
Mazloom M, Gavves E, van de Sande K, Snoek C (2013) Searching informative concept banks for video event detection. In: Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval, International Conference on Multimedia Retrieval, pp 255–262
Ni B, Song Z, Yan S (2011) Web image and video mining towards universal and robust age estimator. IEEE Trans Multimedia 13(6):1217–1229
Pan SJ, Yang Q (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22(10):1345–1359. doi:10.1109/TKDE.2009.191
Schroff F, Criminisi A, Zisserman A (2011) Harvesting image databases from the web. IEEE Trans Pattern Anal Mach Intell 33(4):754–766
Schuldt C, Laptev I, Caputo B (2004) Recognizing human actions: a local svm approach. In: International Conference on Pattern Recognition, vol. 3, pp. 32–36. IEEE
Sun C, Burns B, Nevatia R, Snoek C, Bolles B, Myers G, Wang W, Yeh E (2014) Isomer: Informative segment observations for multimedia event recounting. In: Proceedings of International Conference on Multimedia Retrieval, International Conference on Multimedia Retrieval, pp. 241:241–241:248. ACM
Sun C, Nevatia R (2014) Discover: Discovering important segments for classification of video events and recounting
Sun Q, Chattopadhyay R, Panchanathan S, Ye J (2011) A two-stage weighting framework for multi-source domain adaptation. In: Advances in neural information processing systems, pp 505–513
Tang K, Ramanathan V, Fei-fei L, Koller D (2012) Shifting weights: Adapting object detectors from image to video. In: NIPS, pp. 647–655
Wang H, Wu X, Jia Y (2014) Video annotation via image groups from the web. IEEE Trans Multimedia 16(5):1282–1291
Yan Y, Yang Y, Meng D, Liu G, Tong W, Hauptmann AG, Sebe N (2015) Event oriented dictionary learning for complex event detection. IEEE Trans Image Process 24(6):1867–1878
Yang Y, Zha ZJ, Gao Y, Zhu X, Chua TS (2014) Exploiting web images for semantic video indexing via robust sample-specific loss. IEEE Trans Multimedia 16(6):1677–1689
Zhang X, Yang Y, Zhang Y, Luan H, Li J, Zhang H, Chua TS (2015) Enhancing video event recognition using automatically constructed semantic-visual knowledge base
Acknowledgements
This work was supported in part by the 973 Program of China under grant No. 2012CB720000, the Natural Science Foundation of China(NSFC) under Grant No. 61375044 and 61472038, the Specialized Research Fund for the Doctoral Program of Higher Education of China (20121101120029), the Specialized Fund for Joint Building Program of Beijing Municipal Education Commission, and the Excellent young scholars Research Fund of BIT (2013).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Song, H., Wu, X., Liang, W. et al. Recognizing key segments of videos for video annotation by learning from web image sets. Multimed Tools Appl 76, 6111–6126 (2017). https://doi.org/10.1007/s11042-016-3253-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-016-3253-1