
Abstract
Recent years have witnessed the proliferation of online fashion blogs and communities, where a large amount of fashion model images with chic clothes in various scenarios are publicly available. To facilitate users to find the corresponding clothes, we focus on studying how to generate pure wellshaped clothing items with the best view from the complex model images. Towards this end, inspired by painting, where the initial sketches and following coloring are both essential, we propose a two-stage shape-constrained clothing generative framework, dubbed as PaintNet. PaintNet comprises two coherent components: shape predictor and texture renderer. The shape predictor is devised to predict the intermediate shape map for the to-be-generated clothing item based on the latent representation learning, while the texture renderer is introduced to generate the final clothing image with the guidance of the predicted shape map. Extensive qualitative and quantitative experiments conducted on the public Lookbook dataset verify the effectiveness of PaintNet in clothing generation from fashion model images. Moreover, we also explore the potential of PaintNet in the task of cross-domain clothing retrieval, and the experiment results show that PaintNet can achieve, on average, 5.34% performance improvement over the traditional non-generative retrieval methods.






Similar content being viewed by others

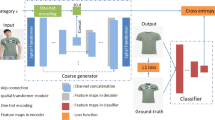
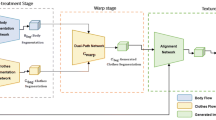
References
Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, Devin M, Ghemawat S, Irving G, Isard M et al (2016) Tensorflow: a system for large-scale machine learning. In: OSDI, pp 265–283
Barnes C, Shechtman E, Finkelstein A, Goldman DB (2009) Patchmatch: A randomized correspondence algorithm for structural image editing. ACM Transactions on Graphics, vol 28. ACM, pp 24
Bay H, Tuytelaars T, Van Gool L (2006) Surf: speeded up robust features. In: European conference on computer vision (ECCV), pp 404–417
Chen H, Hui K, Wang S, Tsao L, Shuai H, Cheng W (2019) Beautyglow: On-Demand Makeup Transfer Framework With Reversible Generative Network. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 10042–10050
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 886–893
Emami H, Aliabadi MM, Dong M, Chinnam RB (2019) Spa-gan: Spatial attention gan for image-to-image translation. arXiv:1908.06616
Gatys L, Ecker AS, Bethge M (2015) Texture synthesis using convolutional neural networks. In: Advances in neural information processing systems (neurIPS), pp 262–270
Gatys LA, Ecker AS, Bethge M (2016) Image style transfer using convolutional neural networks. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 2414-2423
Ge W (2018) Deep metric learning with hierarchical triplet loss. In: European conference on computer vision (ECCV), pp 269–285
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems (neurIPS), pp 2672–2680
Gordo A, Almazan J, Revaud J, Larlus D (2016) Deep image retrieval: Learning global representations for image search. In: European conference on computer vision (ECCV), pp 241–257
Hadi Kiapour M, Han X, Lazebnik S, Berg AC, Berg TL (2015) Where to buy it: Matching street clothing photos in online shops. In: International conference on computer vision (ICCV), pp 3343–3351
He K, Gkioxari G, Dollar P, Girshick R (2017) Mask r-cnn. In: International conference on computer vision (ICCV), pp 2961–2969
Hidayati SC, You C, Cheng W, Hua K (2018) Learning and recognition of clothing genres from Full-Body images. IEEE transactions on Systems, Man, and Cybernetics 48:1647–1659
Hidayati SC, Hua K, Cheng W, Sun S (2014) What are the fashion trends in new york. In: ACM International conference on multimedia, pp 197–200
Hoffer E, Ailon N (2015) Deep metric learning using triplet network. In: International conference on learning representations (ICLR)
Hoffman J, Tzeng E, Park T, Zhu J, Isola P, Saenko K, Darrell T (2018) CyCADA: Cycle-consistent Adversarial Domain Adaptation. In: International conference on machine learning, pp 1989–1998
Huang J, Feris RS, Chen Q, Yan S (2015) Cross-domain image retrieval with a dual attribute-aware ranking network. In: International conference on computer vision (ICCV), pp 1062–1070
Hsieh C, Chen C, Chou C, Shuai H, Liu J, Cheng W (2019) Fashionon: Semantic-guided Image-based Virtual Try-on with Detailed Human and Clothing Information. In: ACM International conference on multimedia, pp 275–283
Isola P, Zhu J, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 1125–1134
Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K (2015) Spatial transformer networks. In: Advances in neural information processing systems (neurIPS), pp 2017–2025
Johnson J, Alahi A, Fei-Fei L (2016) Perceptual losses for real-time style transfer and super-resolution. In: European conference on computer vision (ECCV), pp 694–711
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv:1412.6980
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems (neurIPS), pp 1097–1105
Li C, Wand M (2016) Precomputed real-time texture synthesis with markovian generative adversarial networks. In: European conference on computer vision (ECCV), pp 702–716
Liu Z, Luo P, Qiu S, Wang X, Tang X (2016) Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 1096–1104
Lo L, Liu C, Lin R, Wu B, Shuai H, Cheng W (2019) Dressing for attention: Outfit based fashion popularity prediction. In: International conference on image processing (ICIP), pp 3222–3226
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision (IJCV) 60:91–110
Marques O, Mayron LM, Borba GB, Gamba HR (2006) Using visual attention to extract regions of interest in the context of image retrieval. In: Annual southeast regional conference, pp 638–643
Noh H, De Araujo AF, Sim J, Weyand T, Han B (2017) Large-scale image retrieval with attentive deep local features. In: IEEE International conference on computer vision (ICCV), pp 3456–3465
Ono Y, Trulls E, Fua P, Yi KM (2018) Lf-net: Learning local features from images. In: Advances in neural information processing systems (neurIPS), pp 6234–6244
Radford A, Metz L, Chintala S (2016) Unsupervised representation learning with deep convolutional generative adversarial networks. International Conference on Learning Representations (ICLR)
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Medical image computing and computer assisted intervention (MICCAI), pp 234–241
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X (2016) Improved techniques for training gans. In: Advances in neural information processing systems (neurIPS), pp 2234–2242
Schroff F, Kalenichenko D, Philbin J (2015) Facenet: a unified embedding for face recognition and clustering. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 815–823
Simonyan K, Zisserman A (2015) Very deep convolutional networks for Large-Scale image recognition. In: International conference on learning representations
Sonderby CK, Caballero J, Theis L, Shi W, Huszar F (2017) Amortised map inference for image super-resolution. In: International conference on learning representations (ICLR)
Song Y, Li Y, Wu B, Chen C, Zhang X, Adam H (2017) Learning unified embedding for apparel recognition. In: IEEE International conference on computer vision (ICCV), pp 2243–2246
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 2818–2826
Tian Y, Fan B, Wu F (2017) L2-net: Deep learning of discriminative patch descriptor in euclidean space. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 6128–6136
Tzeng E, Hoffman J, Saenko K, Darrell T (2017) Adversarial discriminative domain adaptation. In: IEEE Conference on computer vision and pattern recognition (CVPR), pp 2962–2971
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP, et al. (2004) Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing (TIP) 13:600–612
Wang X, Sun Z, Zhang W, Zhou Y, Jiang YG (2016) Matching user photos to online products with robust deep features. In: International conference on multimedia retrieval (ICMR), pp 7–14
Wu B, Zhou X, Zhao S, Yue X, Keutzer K (2019) Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In: International conference on robotics and automation (ICRA), pp 4376–4382
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention. In: International conference on machine learning (ICML), pp 2048-2057
Xu Y, Han Y, Hong R, Tian Q (2018) Sequential video VLAD: Training the aggregation locally and temporally. IEEE Transactions on Image Processing (TIP) 27:4933–4944
Yoo D, Kim N, Park S, Paek AS, Kweon IS (2016) Pixel-level domain transfer. In: European conference on computer vision (ECCV), pp 517–532
Yuan Y, Yang K, Zhang C (2017) Hard-aware deeply cascaded embedding. In: IEEE International conference on computer vision (ICCV), pp 814–823
Zhang H, Goodfellow IJ, Metaxas DN, Odena A (2019) Self-attention generative adversarial networks. In: International conference on machine learning (ICML), pp 7354–7363
Zhu J, Park T, Isola P, Efros AA (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In: International conference on computer vision (ICCV), pp 2223–2232
Zhao J, Mathieu M, LeCun Y (2016) Energy-based generative adversarial network. arXiv:1609.03126
Zhao S, Liu Y, Han Y, Hong R, Hu Q, Tian Q (2018) Pooling the Convolutional Layers in Deep ConvNets for Video Action Recognition. IEEE Transactions on Circuits and Systems for Video Technology 28:1839–1849
Zhao S, Zhao X, Ding G, Keutzer K (2018) EmotionGAN: Unsupervised Domain Adaptation for Learning Discrete Probability Distributions of Image Emotions. In: ACM International conference on multimedia, pp 1319–1327
Zhao S, Lin C, Xu P, Zhao S, Guo Y, Krishna R, Keutzer K (2019) CycleemotionGAN: Emotional Semantic Consistency Preserved cycleGAN for Adapting Image Emotions. In: National conference on artificial intelligence, pp 2620–2627
Zhao S, Li B, Yue X, Gu Y, Xu P, Hu R, Keutzer K (2019) Multi-source domain adaptation for semantic segmentation. In: Advances in neural information processing systems (neurIPS), pp 7285–7298
Zhao S, Wang G, Zhang S, Gu Y, Li Y, Song Z, Keutzer K (2020) Multi-source Distilling Domain Adaptation. In: National conference on artificial intelligence
Acknowledgments
This work is supported by the National Natural Science Foundation of China, No.: 61772310, No.:61702300, No.:61702302, No.: 61802231, and No. U1836216; the Project of Thousand Youth Talents 2016; the Shandong Provincial Natural Science and Foundation, No.: ZR2019JQ23, No.:ZR2019QF001; the Young Scholars Program of Shandong University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Lin, J., Song, X., Gan, T. et al. PaintNet: A shape-constrained generative framework for generating clothing from fashion model. Multimed Tools Appl 80, 17183–17203 (2021). https://doi.org/10.1007/s11042-020-09009-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-09009-y