
Abstract
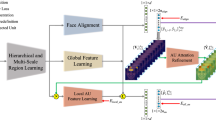
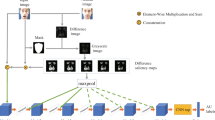
Though the standard convolutional neural networks (CNNs) have been proposed to increase the robustness of facial action unit (AU) detection regarding pose variations, it is hard to enhance detection performance because the standard CNNs are not robust enough to affine transformation. To address this issue, two novel architectures termed as AUCaps and AUCaps++ are proposed for multi-view and multi-label facial AU detection in this work. In these two architectures, one or more dense blocks and one capsule networks (CapsNets) are stacked. Specifically, The dense blocks prefixed before CapsNets are used to learn more discriminative high-level AU features, and the CapsNets is exploited to learn more view-invariant AU features. Moreover, the capsule types and digit capsule dimension are optimized to avoid the computation and storage burden caused by the dynamic routing in standard CapsNets. Because the AUCaps and AUCaps++ are trained by jointly optimizing multi-label loss of AU and reconstruction loss of viewpoint image, the proposed method could achieve high F1 score and learn human face roughly in the reconstruction images over different AUs. Numerical results of within-dataset and cross-dataset show that the average F1 scores of the proposed method outperform the competitors using hand-crafted features or deep learning features by a big margin on two public datasets.







Similar content being viewed by others

References
Afshar P, Mohammadi A, Plataniotis K (2018) Brain tumor type classification via capsule networks. In: International conference on image processing. IEEE, pp 3129–3133
Almaev T, Valstar M (2013) Local gabor binary patterns from three orthogonal planes for automatic facial expression recognition. In: Humaine association conference on affective computing and intelligent interaction. IEEE, pp 356–361
Baltrusaitis T, Mahmoud M, Robinson P (2015) Cross-dataset learning and person-specific normalisation for automatic action unit detection. In: International conference on automatic face and gesture. IEEE, pp 1–6
Batista J, Albiero V, Bellon O, Silva L (2017) AUMPNEt: Simultaneous action units detection and intensity estimation on multipose facial images using a single convolutional neural network. In: International conference on automatic face and gesture recognition. IEEE, pp 866–871
Chu W, Torre F, Cohn J (2017) Learning spatial and temporal cues for multi-label facial action unit detection. In: International conference on automatic face and gesture. IEEE, pp 25–32
Cootes T, Edwards G, Taylor C (2001) Active appearance models. IEEE Trans Pattern Anal Mach Intell 23(6):681–685
Ekman P, Rosenberg E (1997) What the face reveals: Basic and applied studies of spontaneous expression using the Facial Action Coding System (FACS). Oxford University Press, USA
Eleftheriadis S, Rudovic O, Pantic M (2015) Multi-conditional latent variable model for joint facial action unit detection. In: International conference on computer vision. IEEE, pp. 3792–3800
Ertugrul I, Jeni L, Cohn J (2018) FACSCAps: Pose-independent facial action coding with capsules. In: Conference on computer vision and pattern recognition. IEEE, pp. 2130–2139
Fabian C, Srinivasan R, Martinez A (2016) Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In: Conference on computer vision and pattern recognition. IEEE, pp 5562–5570
Gudi A, Tasli H, Uyl TD, Maroulis A (2015) Deep learning based facs action unit occurrence and intensity estimation. In: International conference and workshops on automatic face and gesture recognition. IEEE, pp 1–5
He J, Li D, Yang B, Cao S, Sun B, Yu L (2017) Multi view facial action unit detection based on CNN and BLSTM-RNN. In: International conference on automatic face and gesture. IEEE, pp 848–853
Hinton G, Sabour S, Frosst N (2018) Matrix capsules with em routing. In: International conference on learning representations, pp 1–15
Huang G, Liu Z, Maaten L, Weinberger K (2017) Densely connected convolutional networks. In: Conference on computer vision and pattern recognition. IEEE, pp 2261–2269
Jaiswal A, Abdalmageed W, Natarajan P (2018) Capsulegan: Generative adversarial capsule network
Jung H, Lee S, Yim J, Park S, Kim J (2015) Joint fine-tuning in deep neural networks for facial expression recognition. In: International conference on computer vision. IEEE, pp 2983–2991
Kingma D, Adam JB (2015) A method for stochastic optimization. In: ICLR
Lakshminarayana N, Setlur S, Govindaraju V (2020) Learning guided attention masks for facial action unit recognition. In: International conference on automatic face and gesture recognition. IEEE, pp 465–472
Li X, Chen S, Jin Q (2017) Facial action units detection with multi-features and -AUs fusion. In: International conference on automatic face and gesture. IEEE, pp 860–865
Li Y, Chen J, Zhao Y, Ji Q (2013) Data-free prior model for facial action unit recognition. Trans Affect Comput 4(2):127–141
Liang L, Lang C, Li Y, Feng S, Zhao J (2021) Fine-grained facial expression recognition in the wild. IEEE Trans Inform Forens Secur 16:482–494
Lucey P, Cohn J, Kanade T, Saragih J, Ambadar Z, Matthews I (2010) The extended cohn-kanade dataset (ck+): a complete dataset for action unit and emotion-specified expression. In: Conference on computer vision and pattern recognition workshops. IEEE, pp 94–101
Mehrabian A, Russell J (1974) An approach to environmental psychology. MIT, Cambridge
Pantic M, Valstar M, Rademaker R, Maat L (2005) Web-based database for facial expression analysis. In: International conference on multimedia and expo. IEEE, pp 317–321
Peng G, Wang S (2018) Weakly supervised facial action unit recognition through adversarial training. In: Conference on computer vision and pattern recognition. IEEE, pp 2188–2196
Phaye S, Sikka A, Dhall A, Bathula D (2018) Dense and diverse capsule networks: Making the capsules learn better. arXiv:1805.04001
Ruiz A, Weijer J, Binefa X (2015) From emotions to action units with hidden and semi-hidden-task learning. In: International conference on computer vision. IEEE, pp 3703–3711
Sabour S, Frosst N, Hinton GE (2017) Dynamic routing between capsules. Adv Neural Inform Process Syst 3859–3869
Sanchez-Lozano E, Martinez B, Tzimiropoulos G, Valstar M (2016) Cascaded continuous regression for real-time incremental face tracking. In: European conference on computer vision. Springer, pp 645–661
Sander K, Maja P, Ioannis P (2010) A dynamic texture-based approach to recognition of facial actions and their temporal models. IEEE Trans Pattern Anal Machine Intell 32(11):1940–1954
Senechal T, Rapp V, Salam H, Seguier R, Bailly K, Prevost L (2012) Facial action recognition combining heterogeneous features via multikernel learning. IEEE Trans Syst Man Cybern Part B 42(4):993–1005
Shao Z, Liu Z, Cai J, Ma L (2017) Deep adaptive attention for joint facial action unit detection and face alignment. In: European conference on computer vision. Springer, pp 725–740
Tang C, Zheng W, Yan J, Li Q, Li Y, Zhang T, Cui Z (2017) View-independent facial action unit detection. In: International conference on automatic face and gesture. IEEE, pp 878–882
Toser Z, Jeni L, Lorincz A, Cohn J (2016) Deep learning for facial action unit detection under large head poses. In: European conference on computer vision. Springer, pp 359–371
Valstar M, Sánchezlozano E., Cohn J, Jeni L, Girard J, Zhang Z, Yin L, Pantic M (2017) Fera 2017 - addressing head pose in the third facial expression recognition and analysis challenge. In: International conference on automatic face and gesture recognition. IEEE, pp 839–847
Valstar MF, Mehu M, Jiang B, Pantic M, Scherer K (2012) Meta-analyis of the first facial expression recognition challenge. IEEE Trans Syst Man Cybern Part B 42(4):966–979
Wang K, Peng X, Yang J, Lu S, Qiao Y (2020) Suppressing uncertainties for large-scale facial expression recognition. In: Conference on computer vision and pattern recognition. IEEE, pp 6896–6905
Wang Y, Sun A, Han J, Liu Y, Zhu X (2018) Sentiment analysis by capsules. In: Proceedings of the 2018 World Wide Web Conference, pp 1165–1174
Wang Z, Li Y, Wang S, Ji Q (2014) Capturing global semantic relationships for facial action unit recognition. In: International conference on computer vision. IEEE, pp 3304–3311
Wu S, Wang S, Pan B, Ji Q (2017) Deep facial action unit recognition from partially labeled data. In: International conference on computer vision. IEEE, pp 3971–3979
Xi E, Bing S, Jin Y (2017) Capsule network performance on complex data. arXiv:1712.03480
Yang H, Liu L, Min W, Yang X, Xiong X (2021) Driver yawning detection based on subtle facial action recognition. IEEE Trans Multimed 23:572–583
Yuce A, Gao H, Thiran J (2015) Discriminant multi-label manifold embedding for facial action unit detection. In: International conference on automatic face and gesture. IEEE, pp 1–6
Zhang F, Zhang T, Mao Q, Xu C (2018) Joint pose and expression modeling for facial expression recognition. In: Conference on computer vision and pattern recognition. IEEE, pp 3359–3368
Zhang X, Yin L, Cohn J, Canavan S, Reale M, Horowitz A, Liu P, Girard J (2013) BP4D-spontaneous: a high-resolution spontaneous 3d dynamic facial expression database. Image Vis Comput 32(10):692–706
Zhang Y, Jiang H, Wu B, Fan Y, Ji Q (2019) Context-aware feature and label fusion for facial action unit intensity estimation with partially labeled data. In: International conference on computer vision. IEEE, pp 733–742
Zhang Y, Wu B, Dong W, Li Z, Liu W (2019) B., Ji, Q.: Joint representation and estimator learning for facial action unit intensity estimation. In: Conference on computer vision and pattern recognition. IEEE, pp 3457–3466
Zhang Y, Zhao R, Dong W, Hu B, Ji Q (2018) Bilateral ordinal relevance multi-instance regression for facial action unit intensity estimation. In: Conference on computer vision and pattern recognition. IEEE, pp 7034–7043
Zhang Z, Girard J, Wu Y, Zhang X, Ciftci PLU, Canavan S, Reale M, Horowitz A, Yang H (2016) Multimodal spontaneous emotion corpus for human behavior analysis. In: Conference on computer vision and pattern recognition. IEEE, pp 3438–3446
Zhao K, Chu W, Torre F, Cohn J, Zhang H (2015) Joint patch and multi-label learning for facial action unit detection. In: Conference on computer vision and pattern recognition. IEEE, pp 2207–2216
Zhao K, Chu W, Zhang H (2016) Deep region and multi-label learning for facial action unit detection. In: Computer vision and pattern recognition. IEEE, pp 3391–3399
Acknowledgment
This work was supported in part by the Beijing Nova Program (Z201100006820123) from Beijing Municipal Science and Technology Commission, in part by the Natural Science Foundation of China under Grant U1536203 and 61972169, in part by the National key research and development program of China (2016QY01W0200), in part by the Major Scientific and Technological Project of Hubei Province (2018AAA068 and 2019AAA051).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ren, D., Wen, X., Chen, J. et al. Multi-view facial action unit detection via DenseNets and CapsNets. Multimed Tools Appl 81, 19377–19394 (2022). https://doi.org/10.1007/s11042-021-11147-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11147-w