
Abstract
Advancement in semiconductor technology is allowing to pack more and more processing cores on a single die and scalable directory based protocols are needed for maintaining cache coherence. Most of the currently available directory based protocols are designed for mesh based topology and have the problem of delay and scalability. Cluster based coherence protocol is a better option than flat directory based protocol but the problem of mesh based topology is still exits. On the other hand, tree based topology takes fewer hop counts compared to mesh based topology.
In this paper we give a hierarchical cache coherence protocol based on tree based topology. We divide the processing cores into clusters and each cluster shares a higher-level cache. At the next level we form clusters of caches connected to yet another higher-level cache. This is continued up to the top level cache/memory. We give various architectural placements that can benefit from the protocol; hop-count comparison; and memory overhead requirements. Finally, we formally verify the protocol using the Murϕ tool.





Similar content being viewed by others
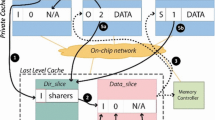
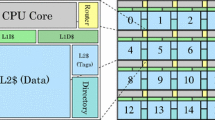
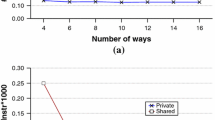
References
Wilson AW Jr (1987) Hierarchical cache/bus architecture for shared memory multiprocessors. In: Proceedings of the 14th international symposium on computer architecture, pp 244–252
Acacio M, Gonzalez J, Garcia J, Duato J (2005) A two-level directory architecture for highly scalable cc-NUMA multiprocessors. IEEE Trans Parallel Distrib Syst 16(1):67–79
Acacio ME, Gonzalez J, Garcia JM, Duato J (2005) A two-level directory architecture for highly-scalable cc-NUMA multiprocessors. IEEE Trans Parallel Distrib Syst 16(1):67–79
Anderson C, Baer JL (1993) A multi-level hierarchical cache coherence protocol for multiprocessors. In: Proceedings of the 7th international parallel processing symposium, pp 142–148
Angiolini F, Meloni P, Carta S, Benini L, Raffo L (2006) Contrasting a NoC and a traditional interconnect fabric with layout awareness. In: Proc of the design, automation and test in Europe (DATE), pp 124–129
Benini L, Micheli D (2002) Networks on chips: a new SoC paradigm. IEEE Comput 35(1):70–78
Bolotin E, Guz Z, Cidon I, Ginosar R, Kolodny A (2007) The power of priority: NoC based distributed cache coherence. In: Proc of 1st international symposium on networks-on-chip, pp 117–126
Chaike D, Field C, Kurihara K, Agarwal A (1990) Directory-based cache coherence in large-scale multiprocessors. IEEE Comput 23:49–58
Cheng L, Muralimanohar N, Ramani K, Balasubramonian R, Carter JB (2006) Interconnect-aware coherence protocols for chip multiprocessors. ACM SIGARCH Comput Archit News 34(2):339–351
Dally W, Towles B (2001) Route packets, not wires: on-chip interconnection networks. In: Proc of design automation conference, pp 684–689
DeHon A (2000) Compact, multilayer layout for butterfly fat-tree. In: Proceedings of the twelfth annual ACM symposium on parallel algorithms and architectures, SPAA’00, pp 206–215
DeHon A (2004) Unifying mesh- and tree-based programmable interconnect. IEEE Trans Very Large Scale Integr Syst 12(10):1051–1065
Dill DL, Drexler AJ, Hu AJ, Yang CH (1992) Protocol verification as a hardware design aid. In: Proc of international conference on computer design, pp 522–525
Eisley N, Peh LS, Shang L (2006) In-network cache coherence. Comput Archit Lett 5:34–37
Feero B, Pande P (2009) Networks-on-chip in a three-dimensional environment: a performance evaluation. IEEE Trans Comput 58:32–45
Gratz P, Kim C, Sankaralingam K, Hanson H, Shivakumar P, Keckler S, Burger D (2007) On-chip interconnection networks of the trips chip. IEEE MICRO 27(5):41–50
Hennessy JL, Patterson DA (2006) Computer architecture, fourth edition: a quantitative approach. Morgan Kaufmann, San Francisco
Hoskote Y, Vangal S, Singh A, Borkar N, Borkar S (2007) A 5-GHz mesh interconnect for a teraflops processor. IEEE MICRO 27(5):51–61
Kim C, Burger D, Keckler S (2002) An adaptive, non-uniform cache structure for wire-delay dominated on-chip caches. In: Proc of the 10th intl conf on architectural support for programming languages and operating systems, pp 211–222
Leiserson CE (1985) Fat-trees: universal networks for hardware-efficient supercomputing. IEEE Trans Comput 34(10):892–901
Lenoski D, Laudon J, Gharachorloo K, Gupta A, Hennessy J (1990) The directory-based cache coherence protocol for the DASH multiprocessor. In: Proceedings of the 17th annual international symposium on computer architecture, pp 148–159
Li F, Nicopoulos C, Richardson T, Xie Y, Narayanan V, Kandemir M (2006) Design and management of 3D chip multiprocessors using network-in-memory. In: Proc intl symposium on computer architecture, pp 131–140
Ludovici D, Villamon FG, Medardoni S, Requena CG, Gomez ME, Lopez P, Gaydadjiev GN, Bertozzi D (2009) Assessing fat-tree topologies for regular network-on-chip design under nanoscale technology constraints. In: Proc of design, automation and test in Europe (DATE), pp 562–565
Martin MMK, Hill MD, Wood DA (2003) Token coherence: a new framework for shared-memory multiprocessors. IEEE MICRO 23(6):108–116
Martin MMK, Hill MD, Wood DA (2003) Token coherence: decoupling performance and correctness. In: Proc of international symposium on computer architecture (ISCA), pp 182–193
Matsutani H, Koibuchi M, Amano H (2007) Performance, cost and energy evaluation of fat H-tree: a cost efficient tree-based on-chip network. In: Proc of parallel and distributed processing symposium (IPDPS), pp 1–10
Matsutani H, Koibuchi M, Yamada Y, Hsu DF, Amano H (2009) Fat H-tree: a cost efficient tree-based on-chip network. IEEE Trans Parallel Distrib Syst 20(8):1126–1141
Stern U, Dill DL (1995) Automatic verification of the SCI cache coherence protocol. In: Correct hardware design and verification methods. LNCS, vol 987, pp 21–34
Tomasevic M, Milutinovic V (1993) A survey of hardware solutions for maintenance of cache coherence in shared memory multiprocessors. In: Proceeding of the twenty-sixth Hawaii international conference on system sciences, 1993, vol 1, pp 863–872.
Tsui J, Aboelaze M (1996) Single copy vs. multiple copies cache coherence protocols for hierarchical bus multiprocessors. In: Proceedings of the international conference on computers and communications, pp 151–157
Wallach DA (1992) A hierarchical cache coherent protocol. PhD thesis, MIT
Wentzlaff D, Griffin P, Hoffmann H, Bao L, Edwards B, Ramey C, Mattina M, Miao CC, Brown JF III, Agarwal A (2007) On-chip interconnection architecture of the tile processor. IEEE MICRO 27(5):15–31
Yang Q, Thangadurai G, Bhuyan LM (1992) Design of an adaptive cache coherence protocol for large scale multiprocessors. IEEE Trans Parallel Distrib Syst 3(3):281–293
Yousif MS, Das CR, Thazhuthaveetil MJ (1993) A cache coherence protocol for MIN-based multiprocessors with limited inclusion. In: International conference on parallel processing, pp 254–257
Zhang Y, Lu Z, Jantsch A, Li L, Gao M (2009) Towards hierarchical cluster based cache coherence for large-scale network-on-chip. In: 4th intl conference on design and technology of integrated systems in nanoscale era (DTIS), pp 119–122
Author information
Authors and Affiliations
Corresponding author
Appendix: Example illustrating the protocol
Appendix: Example illustrating the protocol
Figures 5 to 9 show successive steps and state of the sample topology with various nodes performing read/write on a given block. The L2-1 to L2-4 are assumed to be different L2-caches (and not cache-banks). Two such L2-caches form one cluster connecting to L3-1 and so on. State of the block is shown near each cache. The light colour (filled) nodes are the ones holding/requesting read only copies and the dark colour (filled) nodes are for the writers.
In the beginning, node-1 performs a read. It will acquire a copy of the block (from the memory) and all caches along the hierarchy will have state 001 (Fig. 6).

After Read by node-1
Now suppose node-2 wants to write. It will send a write request to L2-1. As L2-1 has the block (state = 001) it will invalidate the other copies in the cluster [2: inv sent to node-1]. As we assume write-through for intra-cluster, L2-1 will have a dirty copy and this needs to be informed to the parent L3-1 [2: blk-dirty message]. Similarly, L3-1 will inform its parent Memory about blk-dirty. This message will make the state of L3-1 and Memory to 1X1. The state indicates that some child node holds a modified copy of the block. After L2-1 gets all the ack messages it will send the block to node-2 for writing, Fig. 7.

After Write by node-2
Using this as the start state we illustrate the procedure for read request from node-5 in Fig. 8 and a subsequent write request from node-9 in Fig. 9.

After Read by node-5

After Write by node-9
Rights and permissions
About this article
Cite this article
Kapoor, H.K., Kanakala, P., Verma, M. et al. Design and formal verification of a hierarchical cache coherence protocol for NoC based multiprocessors. J Supercomput 65, 771–796 (2013). https://doi.org/10.1007/s11227-012-0865-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-012-0865-8