
Abstract
OpenMP is an industry and academic standard for parallel programming. However, using it for developing parallel stream processing applications is complex and challenging. OpenMP lacks key programming mechanisms and abstractions for this particular domain. To tackle this problem, we used a high-level parallel programming framework (named SPar) for automatically generating parallel OpenMP code. We achieved this by leveraging SPar’s language and its domain-specific code annotations for simplifying the complexity and verbosity added by OpenMP in this application domain. Consequently, we implemented a new compiler algorithm in SPar for automatically generating parallel code targeting the OpenMP runtime using source-to-source code transformations. The experiments in four different stream processing applications demonstrated that the execution time of SPar was improved up to 25.42% when using the OpenMP runtime. Additionally, our abstraction over OpenMP introduced at most 1.72% execution time overhead when compared to handwritten parallel codes. Furthermore, SPar significantly reduces the total source lines of code required to express parallelism with respect to plain OpenMP parallel codes.




Similar content being viewed by others

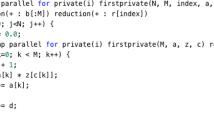

Notes
Obtained with SLOCCOUNT tool.
References
Aldinucci M, Danelutto M, Kilpatrick P, Meneghin M, Torquati M (2011) Accelerating code on multi-cores with FastFlow. Euro-Par 2011 parallel processing, vol 6853. Lecture notes in computer science. Springer, Berlin, pp 170–181
Aldinucci M, Danelutto M, Kilpatrick P, Torquati M (2014) FastFlow: high-level and efficient streaming on multi-core. In: Programming Multi-core and Many-core Computing Systems, PDC, vol 1, p 14
Bienia C, Kumar S, Singh JP, Li K (2008) The PARSEC benchmark suite: characterization and architectural implications. In: 17th International Conference on Parallel Architectures and Compilation Techniques. PACT ’08. ACM, Toronto, Ontario, Canada, pp 72–81
Bradski G (2000) The OpenCV library. Dr. Dobb’s journal of software tools
Danelutto M, Matteis TD, Sensi DD, Mencagli G, Torquati M, Aldinucci M, Kilpatrick P (2019) The rephrase extended pattern set for data intensive parallel computing. Int J Parallel Progr 47:74–93. https://doi.org/10.1007/s10766-017-0540-z
del Rio Astorga D, Dolz MF, Sanchez LM, Blas JG, García JD (2016) A c++ generic parallel pattern interface for stream processing. In: Algorithms and Architectures for Parallel Processing, Springer International Publishing, Cham, pp 74–87
Gilchrist J (2004) Parallel Compression with BZIP2. In: 16th IASTED International Conference on Parallel and Distributed Computing and Systems. PDCS’ 04. ACTA Press, MIT, Cambridge, USA, pp 559–564
Griebler D (2016) Domain-specific language and support tool for high-level stream parallelism. Ph.D. thesis, Faculdade de Informática - PPGCC - PUCRS, Porto Alegre, Brazil. http://tede2.pucrs.br/tede2/handle/tede/6776
Griebler D, Danelutto M, Torquati M, Fernandes LG (2017) SPar: a DSL for high-level and productive stream parallelism. Parallel Process Lett 27(01):1740005. https://doi.org/10.1142/S0129626417400059
Griebler D, Hoffmann RB, Danelutto M, Fernandes LG (2017) Higher-level parallelism abstractions for video applications with SPar. In: Parallel Computing is Everywhere, Proceedings of the International Conference on Parallel Computing, ParCo’17, IOS Press, Bologna, Italy, pp 698–707 https://doi.org/10.3233/978-1-61499-843-3-698
Griebler D, Hoffmann RB, Danelutto M, Fernandes LG (2018) High-level and productive stream parallelism for Dedup, Ferret, and Bzip2. Int J Parallel Progr 47(1):253–271. https://doi.org/10.1007/s10766-018-0558-x
Griebler D, Hoffmann RB, Danelutto M, Fernandes LG (2018) Stream parallelism with ordered data constraints on multi-core systems. J Supercomput 75(8):4042–4061. https://doi.org/10.1007/s11227-018-2482-7
Hoffmann RB, Griebler D, Danelutto M, Fernandes LG (2020) Stream parallelism annotations for multi-core frameworks. In: XXIV Brazilian Symposium on Programming Languages (SBLP), SBLP’20, ACM, Natal, Brazil, pp 48–55 https://doi.org/10.1145/3427081.3427088
ISO/IEC-14882:2011 (2011) Information technology - programming languages - C++. Technical report, International Standard, Geneva, Switzerland
Jacqueline FD, Buttlar BN (1996) PThreads programming. O’Reilly, Sebastopol, CA, USA
Lee ITA, Leiserson CE, Schardl TB, Zhang Z, Sukha J (2015) On-the-fly pipeline parallelism. ACM Trans Parallel Comput. https://doi.org/10.1145/2809808
Leiserson CE (2009) The cilk++ concurrency platform. In: Proceedings of the 46th Annual Design Automation Conference, DAC ’09, Association for Computing Machinery, New York, NY, USA, pp 522–527 https://doi.org/10.1145/1629911.1630048
Mattson T, Sanders B, Massingill B (2004) Patterns for parallel programming, 1st edn. Addison-Wesley Professional, New York
McCool M, Reinders J, Robison A (2012) Structured parallel programming: patterns for efficient computation. Morgan Kaufmann Publishers Inc., San Francisco
Memeti S, Pllana S (2018) Hstream: a directive-based language extension for heterogeneous stream computing. In: 2018 IEEE International Conference on Computational Science and Engineering (CSE), pp 138–145 https://doi.org/10.1109/CSE.2018.00026
Nakao M, Murai H, Sato M (2019) Multi-accelerator extension in openmp based on pgas model. In: Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region, HPC Asia 2019, Association for Computing Machinery, New York, NY, USA, pp 18–25 https://doi.org/10.1145/3293320.3293324
OmpSs: The ompss programming model (2020). https://pm.bsc.es/ompss
OpenMP (2020) Open multi-processing api specification for parallel programming http://openmp.org/
Pop A, Cohen A (2013) Openstream: expressiveness and data-flow compilation of openmp streaming programs. ACM Trans Archit Code Optim. https://doi.org/10.1145/2400682.2400712
Reinders J (2007) Intel threading building blocks. O’Reilly, Sebastopol
Rockenbach DA, Griebler D, Danelutto M, Fernandes LG (2019) High-level stream parallelism abstractions with SPar targeting GPUs. In: Parallel Computing is Everywhere, Proceedings of the International Conference on Parallel Computing (ParCo), ParCo’19, IOS Press, Prague, Czech Republic, vol 36, pp 543–552 https://doi.org/10.3233/APC200083
Thies W, Karczmarek M, Amarasinghe S (2002) Streamit: a language for streaming applications. In: Horspool RN (ed) Compiler construction. Springer, Berlin, pp 179–196
Vogel A, Griebler D, Fernandes LG (2021) Providing high-level self-adaptive abstractions for stream parallelism on multicores. Software: practice and experience 51(6):1194–1217. https://doi.org/10.1002/spe.2948
Acknowledgements
We would like to acknowledge the support of LAD-PUCRS, GMAP research group and PUCRS university. This research is partially funded by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001, FAPERGS 05/2019-PQG project ParAS (N\(^{o}\) 19/2551-0001895-9), FAPERGS 10/2020-ARD project SPar4.0 (N\(^{o}\) 21/2551-0000725-7), Universal MCTIC/CNPq N\(^{o}\) 28/2018 project SParCloud (N\(^{o}\) 437693/2018-0), and MCTIC/CNPq call 25/2020 (N\(^{o}\) 130484/2021-0)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hoffmann, R.B., Löff, J., Griebler, D. et al. OpenMP as runtime for providing high-level stream parallelism on multi-cores. J Supercomput 78, 7655–7676 (2022). https://doi.org/10.1007/s11227-021-04182-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-021-04182-9