
Abstract
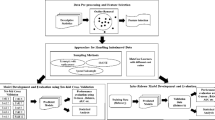
As the complexity of software systems is increasing; software maintenance is becoming a challenge for software practitioners. The prediction of classes that require high maintainability effort is of utmost necessity to develop cost-effective and high-quality software. In research of software engineering predictive modeling, various software maintainability prediction (SMP) models are evolved to forecast maintainability. To develop a maintainability prediction model, software practitioners may come across situations in which classes or modules requiring high maintainability effort are far less than those requiring low maintainability effort. This condition gives rise to a class imbalance problem (CIP). In this situation, the minority classes’ prediction, i.e., the classes demanding high maintainability effort, is a challenge. Therefore, in this direction, this study investigates three techniques for handling the CIP on ten open-source software to predict software maintainability. This empirical investigation supports the use of resampling with replacement technique (RR) for treating CIP and develop useful models for SMP.
Similar content being viewed by others

Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.References
Kaur A, Kaur K. Statistical comparison of modelling methods for software maintainability prediction. International Journal of Software Engineering and Knowledge Engineering, 2013, 23(6): 743–774
Kumar L, Rath S K. Hybrid functional link artificial neural network approach for predicting maintainability of object-oriented software. Journal of Systems and Software, 2016, 121: 170–190
Malhotra R, Lata K. An exploratory study for predicting maintenance effort using hybridized techniques. In: Proceedings of the 10th Innovations in Software Engineering Conference. 2017, 26–33
Kumar L, Naik D K, Rath S K. Validating the effectiveness of object-oriented metrics for predicting maintainability. Procedia Computer Science, 2015, 57: 798–806
Elish M O, Elish K O. Application of TreeNet in predicting object-oriented software maintainability: a comparative study. In: Proceeding of the 13th European Conference on Software Maintenance and Reengineering. 2009, 69–78
Chug A, Malhotra R. Benchmarking framework for maintainability prediction of open source software using object oriented metrics. International Journal of Innovative Computing, Information and Control, 2016, 12(2): 615–634
Thwin M M T, Quah T S. Application of neural networks for software quality prediction using object-oriented metrics. Journal of Systems and Software, 2005, 76(2): 147–156
Van Koten C, Gray A R. An application of Bayesian network for predicting object-oriented software maintainability. Information and Software Technology, 2006, 48(1): 59–67
Aggarwal K K, Singh Y, Kaur A, Malhotra R. Application of artificial neural network for predicting maintainability using object-oriented metrics. International Journal of Computer and Information Engineering, 2008, 2(10): 3552–3556
Zhang W, Huang L, Ng V, Ge J. SMPLearner: learning to predict software maintainability. Automated Software Engineering, 2015, 22(1): 111–141
Kumar L, Rath S K. Software maintainability prediction using hybrid neural network and fuzzy logic approach with parallel computing concept. International Journal of System Assurance Engineering and Management, 2017, 8(S2): 1487–1502
Zhou L. Performance of corporate bankruptcy prediction models on imbalanced dataset: the effect of sampling methods. Knowledge-Based Systems, 2013, 41: 16–25
Napierala K, Stefanowski J. Types of minority class examples and their influence on learning classifiers from imbalanced data. Journal of Intelligent Information Systems, 2016, 46(3): 563–597
Loyola-González O, Martínez-Trinidad J F, Carrasco-Ochoa J A, García-Borroto M. Study of the impact of resampling methods for contrast pattern based classifiers in imbalanced databases. Neurocomputing, 2016, 175: 935–947
Yu H, Mu C, Sun C, Yang W, Yang X, Zuo X. Support vector machine-based optimized decision threshold adjustment strategy for classifying imbalanced data. Knowledge-Based Systems, 2015, 76: 67–78
Cheng F, Zhang J, Wen C. Cost-sensitive large margin distribution machine for classification of imbalanced data. Pattern Recognition Letters, 2016, 80: 107–112
Wang S, Yao X. Using class imbalance learning for software defect prediction. IEEE Transactions on Reliability, 2013, 62(2): 434–443
Khoshgoftaar T M, Gao K, Seliya N. Attribute selection and imbalanced data: problems in software defect prediction. In: Proceedings of the 22nd IEEE International Conference on Tools with Artificial Intelligence. 2010, 137–144
Tan M, Tan L, Dara S, Mayeux C. Online defect prediction for imbalanced data. In: Proceedings of the 37th IEEE International Conference on Software Engineering. 2015, 99–108
Pelayo L, Dick S. Applying novel resampling strategies to software defect prediction. In: Proceedings of 2007 Annual Meeting of the North American Fuzzy Information Processing Society. 2007, 69–72
Sun Z, Song Q, Zhu X. Using coding-based ensemble learning to improve software defect prediction. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2012, 42(6): 1806–1817
Siers M J, Islam M Z. Software defect prediction using a cost sensitive decision forest and voting, and a potential solution to the class imbalance problem. Information Systems, 2015, 51: 62–71
Laradji I H, Alshayeb M, Ghouti L. Software defect prediction using ensemble learning on selected features. Information and Software Technology, 2015, 58: 388–402
Zheng J. Cost-sensitive boosting neural networks for software defect prediction. Expert Systems with Applications, 2010, 37(6): 4537–4543
Choeikiwong T, Vateekul P. Software defect prediction in imbalanced data sets using unbiased support vector machine. In: Kim K J. ed. Information Science and Applications. Berlin, Heidelberg: Springer, 2015, 923–931
Malhotra R, Khanna M. An empirical study for software change prediction using imbalanced data. Empirical Software Engineering, 2017, 22(6): 2806–2851
Giger E, Pinzger M, Gall H C. Can we predict types of code changes? An empirical analysis. In: Proceedings of the 9th IEEE Working Conference on Mining Software Repositories. 2012, 217–226
Singh Y, Kaur A, Malhotra R. Empirical validation of object-oriented metrics for predicting fault proneness models. Software Quality Journal, 2010, 18(1): 3–35
Martin R C. Agile Software Development: Principles, Patterns, and Practices. Upper Saddle River: Prentice Hall, 2002
Henderson-Sellers B. Object-Oriented Metrics: Measures of Complexity. Upper Saddle River: Prentice Hall, 1995
He H, Garcia E A. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263–1284
Gao K, Khoshgoftaar T M, Napolitano A. Combining feature subset selection and data sampling for coping with highly imbalanced software data. In: Proceedings of the 27th International Conference on Software Engineering and Knowledge Engineering. 2015, 439–444
Lessmann S, Baesens B, Mues C, Pietsch S. Benchmarking classification models for software defect prediction: a proposed framework and novel findings. IEEE Transactions on Software Engineering, 2008, 34(4): 485–496
Malhotra R, Pritam N, Nagpal K, Upmanyu P. Defect collection and reporting system for Git based open source software. In: Proceedings of 2014 International Conference on Data Mining and Intelligent Computing. 2014, 1–7
Chawla N V, Bowyer K W, Hall L O, Kegelmeyer W P. SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 2002, 16: 321–357
Han J, Pei J, Kamber M. Data Mining: Concepts and Techniques. 3rd ed. New York: Elsevier, 2011
Haykin S. Neural Networks: A Comprehensive Foundation. Upper Saddle River: Prentice Hall, 1994
Breiman L. Random forests. Machine Learning, 2001, 45(1): 5–32
Witten I H, Frank E. Data Mining: Practical Machine Learning Tools and Techniques. 2nd ed. San Francisco: Morgan Kaufmann, 2005
Breiman L. Bagging predictors. Machine Learning, 1996, 24(2): 123–140
Friedman J, Hastie T, Tibshirani R. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). The Annals of Statistics, 2000, 28(2): 337–407
Ma Y, Luo G, Zeng X, Chen A. Transfer learning for cross-company software defect prediction. Information and Software Technology, 2012, 54(3): 248–256
Nguyen H A, Nguyen T T, Pham N H, Al-Kofahi J, Nguyen T N. Clone management for evolving software. IEEE Transactions on Software Engineering, 2012, 38(5): 1008–1026
Duala-Ekoko E, Robillard M P. Tracking code clones in evolving software. In: Proceedings of the 29th International Conference on Software Engineering. 2007, 158–167
De Wit M, Zaidman A, Van Deursen A. Managing code clones using dynamic change tracking and resolution. In: Proceedings of 2009 IEEE International Conference on Software Maintenance. 2009, 169–178
Author information
Authors and Affiliations
Corresponding author
Additional information
Ruchika Malhotra is Associate Head and Associate Professor in the Discipline of Software Engineering, Department of Computer Science and Engineering, Delhi Technological University (formerly Delhi College of Engineering), India. She has been awarded the prestigious UGC Raman Postdoctoral Fellowship by the Indian government for pursuing postdoctoral research from Department of Computer and Information Science, Indiana University-Purdue University, USA. She was an assistant professor at the University School of Information Technology, Guru Gobind Singh Indraprastha University, India. She has received IBM Faculty Award 2013. Her h-index is 30 as reported by Google Scholar. She can be contacted by email at ruchikamalhotra@dtu.ac.in.
Kusum Lata is currently working as Assistant Professor in University School of Management and Entrepreneurship, Delhi Technological University, India. She completed her master’s degree in Computer Technology and Applications in 2010 from the Delhi College of Engineering, University of Delhi, India. She has received her doctoral degree in Computer Science and Engineering from Delhi Technological University, India. Her research interests are in software quality improvement, applications of machine learning techniques in maintainability prediction, and validation of software metrics. She can be contacted by email at kusumlata@dtu.ac.in.
Electronic supplementary material
Rights and permissions
About this article

Cite this article
Malhotra, R., Lata, K. Handling class imbalance problem in software maintainability prediction: an empirical investigation. Front. Comput. Sci. 16, 164205 (2022). https://doi.org/10.1007/s11704-021-0127-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11704-021-0127-0