
Abstract
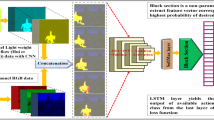
Action recognition is an important research topic in video analysis that remains very challenging. Effective recognition relies on learning a good representation of both spatial information (for appearance) and temporal information (for motion). These two kinds of information are highly correlated but have quite different properties, leading to unsatisfying results of both connecting independent models (e.g., CNN-LSTM) and direct unbiased co-modeling (e.g., 3DCNN). Besides, a long-lasting tradition on this task with deep learning models is to just use 8 or 16 consecutive frames as input, making it hard to extract discriminative motion features. In this work, we propose a novel network structure called ResLNet (Deep Residual LSTM network), which can take longer inputs (e.g., of 64 frames) and have convolutions collaborate with LSTM more effectively under the residual structure to learn better spatial-temporal representations than ever without the cost of extra computations with the proposed embedded variable stride convolution. The superiority of this proposal and its ablation study are shown on the three most popular benchmark datasets: Kinetics, HMDB51, and UCF101. The proposed network could be adopted for various features, such as RGB and optical flow. Due to the limitation of the computation power of our experiment equipment and the real-time requirement, the proposed network is tested on the RGB only and shows great performance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.References
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015, 1–9
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016, 770–778
Huang G, Liu Z, Van Der Maaten L, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, 4700–4708
Hara K, Kataoka H, Satoh Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, 6546–6555
Qiu Z, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3d residual networks. In: Proceedings of the IEEE International Conference on Computer Vision. 2017, 5533–5541
Tran D, Wang H, Torresani L, Ray J, LeCun Y, Paluri M. A closer look at spatiotemporal convolutions for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, 6450–6459
Hara K, Kataoka H, Satoh Y. Learning spatio-temporal features with 3d residual networks for action recognition. In: Proceedings of the IEEE International Conference on Computer Vision. 2017, 3154–3160
Tran D, Ray J, Shou Z, Chang S F, Paluri M. Convnet architecture search for spatiotemporal feature learning. 2017, arXiv preprint arXiv: 1708.05038
Ye M, Li J, Ma A J, Zheng L, Yuen P C. Dynamic graph co-matching for unsupervised video-based person re-identification. IEEE Transactions on Image Processing, 2019, 28(6): 2976–2990
Ye M, Lan X, Yuen P C. Robust anchor embedding for unsupervised video person re-identification in the wild. In: Proceedings of the European Conference on Computer Vision. 2018, 170–186
Ye M, Shen J, Lin G, Xiang T, Shao L, Hoi S C. Deep learning for person re-identification: a survey and outlook. 2020, arXiv preprint arXiv: 2001.04193
Shi X, Chen Z, Wang H, Yeung D Y, Wong W K, Woo W C. Convolutional lstm network: a machine learning approach for precipitation nowcasting. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. 2015, 802–810
Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of International Conference on International Conference on Machine Learning. 2015
Laptev I. On space-time interest points. International Journal of Computer Vision, 2005, 64(2–3): 107–123
Scovanner P, Ali S, Shah M. A 3-dimensional sift descriptor and its application to action recognition. In: Proceedings of the 15th ACM International Conference on Multimedia. 2007, 357–360
Klaser A, Marszalek M, Schmid C. A spatio-temporal descriptor based on 3d-gradients. In: Proceedings of the British Machine Vision Conference. 2008
Wang T, Snoussi H. Detection of abnormal visual events via global optical flow orientation histogram. IEEE Transactions on Information Forensics and Security, 2014, 9(6): 988–998
Dalal N, Triggs B, Schmid C. Human detection using oriented histograms of flow and appearance. In: Proceedings of the European Conference on Computer Vision. 2006, 428–441
Wang H, Schmid C. Action recognition with improved trajectories. In: Proceedings of the IEEE International Conference on Computer Vision. 2013, 3551–3558
Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. 2017, 4724–4733
He K, Zhang X, Ren S, Sun J. Identity mappings in deep residual networks. In: Proceedings of European Conference on Computer Vision. 2016, 630–645
Xie S, Girshick R, Dollár P, Tu Z, He K. Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, 1492–1500
Wang L, Li W, Li W, Van Gool L. Appearance-and-relation networks for video classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, 1430–1439
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the International Conference on Learning Representations. 2015, 1–14
Kong C, Lucey S. Take it in your stride: do we need striding in CNNs? 2017, arXiv preprint arXiv: 1712.02502
Guo C, Liu Yl, Jiao X. Study on the influence of variable stride scale change on image recognition in CNN. Multimedia Tools and Applications, 2019, 78(21): 30027–30037
Zaniolo L, Marques O. On the use of variable stride in convolutional neural networks. Multimedia Tools and Applications, 2020, 79(19): 13581–13598
Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. 2014, 568–576
Wang T, Qiao M, Zhu A, Shan G, Snoussi H. Abnormal event detection via the analysis of multi-frame optical flow information. Frontiers of Computer Science, 2020, 14(2): 304–313
Zhang L, Zhu G, Shen P, Song J, Shah S A, Bennamoun M. Learning spatiotemporal features using 3dcnn and convolutional lstm for gesture recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, 3120–3128
Kay W, Carreira J, Simonyan K, Zhang B, Hillier C, Vijayanarasimhan S, Viola F, Green T, Back T, Natsev P, et al. The kinetics human action video dataset. 2017, arXiv preprint arXiv: 1705.06950
Yue-Hei Ng J, Hausknecht M, Vijayanarasimhan S, Vinyals O, Monga R, Toderici G. Beyond short snippets: deep networks for video classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015, 4694–4702
Donahue J, Anne Hendricks L, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T. Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015, 2625–2634
Shen L, Hong R, Hao Y. Advance on large scale near-duplicate video retrieval. Frontiers of Computer Science, 2020, 14(5): 145702
Zhu G, Zhang L, Shen P, Song J. Multimodal gesture recognition using 3-d convolution and convolutional LSTM. IEEE Access, 2017, 5: 4517–4524
Laurent C, Pereyra G, Brakel P, Zhang Y, Bengio Y. Batch normalized recurrent neural networks. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. 2016, 2657–2661
Amodei D, Ananthanarayanan S, Anubhai R, Bai J, Battenberg E, Case C, Casper J, Catanzaro B, Cheng Q, Chen G, et al. Deep speech 2: end-to-end speech recognition in english and mandarin. In: Proceedings of International Conference on Machine Learning. 2016, 173–182
Cooijmans T, Ballas N, Laurent C, Gülçehre Ç, Courville A. Recurrent batch normalization. 2016, arXiv preprint arXiv: 1603.09025
Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T. Hmdb: a large video database for human motion recognition. In: Proceedings of the IEEE International Conference on Computer Vision. 2011, 2556–2563
Soomro K, Zamir A R, Shah M. Ucf101: a dataset of 101 human actions classes from videos in the wild. 2012, arXiv preprint arXiv: 1212.0402
Varol G, Laptev I, Schmid C. Long-term temporal convolutions for action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510–1517
Zheng J, Cao X, Zhang B, Zhen X, Su X. Deep ensemble machine for video classification. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(2): 553–565
Tu N A, Huynh-The T, Khan K U, Lee Y K. Ml-hdp: a hierarchical bayesian nonparametric model for recognizing human actions in video. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(3): 800–814
Acknowledgements
This work was supported in part by the National Key Research and Development Program of China (2018AAA0101400), the National Natural Science Foundation of China (Grant Nos. 61972016, 62032016, 61866022), the Natural Science Foundation of Beijing (L191007).
Author information
Authors and Affiliations
Corresponding author
Additional information
Tian Wang received the MS degree and PhD degree from Xi’an Jiaotong University, China and University of Technology of Troyes, France in 2010 and 2014, respectively. He is an assistant professor at the School of Automation of Science and Electrical Engineering, Beihang University, China. His research interests include computer vision and pattern recognition.
Jiakun Li received the MS degree in School of Automation Science and Electrical Engineering in Beihang University, China. He is involved in human action recognition and video understanding. His academic interests are computer vision and machine learning.
Huai-Ning Wu received the BE degree in automation from Shandong Institute of Building Materials Industry, China and the PhD degree in control theory and control engineering from Xi’an Jiaotong University, China in 1992 and 1997, respectively. From August 1997 to July 1999, he was a Postdoctoral Research Fellow with the Department of Electronic Engineering at Beijing Institute of Technology, China. Since August 1999, he has been with the School of Automation Science and Electrical Engineering, Beihang University, China. From December 2005 to May 2006, he was a Senior Research Associate with the City University of Hong Kong(CityU), China. From October to December during 2006–2008 and from July to August in 2010, 2011, and 2013, he was a Research Fellow with CityU, China. He is currently a Professor with Beihang University, China. His current research interests include robust control, fault-tolerant control, distributed parameter systems, and fuzzy/neural modeling and control.
Ce Li received his PhD degree in pattern recognition and intelligence system from Xi’an Jiao tong University, China in 2013. He is a professor at the College of Electrical and Information Engineering, Lanzhou University of Technology, China. His research interests include computer vision and pattern recognition.
Hichem Snoussi received his diploma from Ecole Supérieure d’Electricité (Supelec) in 2000, and his DEA and PhD degrees from the University of Paris-Sud, France in 2000 and 2003, respectively. From 2003 to 2004, he was a postdoctoral researcher with the Institut de Recherche en Communications et Cybernétiques de Nantes. Since 2010, he has been a full professor at the University of Technology of Troyes, France. His research interests include signal processing, computer vision, and machine learning.
Yang Wu received a BS degree and a PhD degree from Xi’an Jiaotong University, China in 2004 and 2010, respectively. He is currently a program-specific senior lecturer with the Department of Intelligence Science and Technology, Graduate School of Informatics, Kyoto University, Japan. He is also a guest associate professor of Nara Institute of Science and Technology (NAIST), Japan, where he was an assistant professor of the NAIST International Collaborative Laboratory for Robotics Vision, from Dec. 2014 to Jun. 2019. From 2011 to 2014, he was a program-specific researcher with the Academic Center for Computing and Media Studies, Kyoto University, Japan. His research is in the fields of computer vision, pattern recognition, and image/video search and retrieval.
Electronic Supplementary Material
Rights and permissions
About this article

Cite this article
Wang, T., Li, J., Wu, HN. et al. ResLNet: deep residual LSTM network with longer input for action recognition. Front. Comput. Sci. 16, 166334 (2022). https://doi.org/10.1007/s11704-021-0236-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11704-021-0236-9