
Abstract
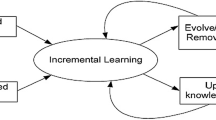
Learning strategies under covariate shift have recently been widely discussed. The density of learning inputs under covariate shift is different from that of test inputs. Learning machines in such environments need to employ special learning strategies to acquire greater capabilities of generalizing through learning. However, incremental learning methods are also used for learning in non-stationary learning environments, which represent a kind of covariate shift. However, the relation between covariate-shift environments and incremental-learning environments has not been adequately discussed. This paper focuses on the covariate shift in incremental-learning environments and our re-construction of a suitable incremental-learning method. Then, the model-selection criterion is also derived, which is to be an essential object function for memetic algorithms to solve these kinds of learning problems.
Similar content being viewed by others


References
Aitchison J, Dunsmore IR (1980) Statistical prediction analysis. Cambridge University Press, London
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control AC-19(6): 716–723
Ans B, Roussert S (2000) Neural networks with a self-refreshing memory: knowledge transfer in sequential learning tasks without catastrophic forgetting. Connect Sci 12(1): 1–19
Bezdek J (1980) A convergence theorem for the fuzzy isodata clustering algorithms. IEEE Trans Pattern Anal Mach Intell 2: 1–8
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the em algorithm. J Roy Stat Soc B 39(1): 1–38
French RM (1997) Pseudo-recurrent connectionist networks: an approach to the “sensitivity stability” dilemma. Connect Sci 9(4): 353–379
Hidetoshi S (2000) Improving predictive inference under covariate shift by weighting the log-likelihood function. J Stat Plan Infer 90(2): 227–244
Kasabov N (2001) Evolving fuzzy neural networks for supervised/unsupervised online knowledge-based learning. IEEE Trans Syst Man Cybern 31(6): 902–918
Meuth R, Lim MH, Ong YS, II DCW (2009) A proposition on memes and meta-memes in computing for higher-order learning. Memetic Comput 1: 85–100
Moody J, Darken CJ (1989) Fast learning in neural networks of locally-tuned processing units. Neural Comput 1: 281–294
Ozawa S, Toh SL, Abe S, Pang S, Kasabov N (2005) Incremental learning of feature space and classifier for face recognition. Neural Netw 18: 575–584
Platt J (1991) A resource allocating network for function interpolation. Neural Comput 3(2): 213–225
Schaal S, Atkeson CG (1998) Constructive incremental learning from only local information. Neural Comput 10(8): 2047–2084
Specht DF (1991) A general regression neural network. IEEE Trans Neural Networks 2(6): 568–576
Su MC, Lee J, Hsieh KL (2006) A new artmap-based neural network for incremental learning. Neurocomputing 69: 2284–2300
Sugiyama M, Nakajima S, Kashima H, von Bunau P, Kawanabe M (2007) Direct importance estimation with model selection and its application to covariate shift adaptation. In: Twenty-first annual conference on neural information processing systems (NIPS2007)
Yamakawa H, Masumoto D, Kimoto T, Nagata S (1994) Active data selection and subsequent revision for sequential learning with neural networks. World Congr Neural Netw (WCNN’ 94) 3: 661–666
Yamauchi K (2008) Covariate shift and incremental learning. In: Advances in neuro-information processing 15th international conference, ICONIP 2008, Auckland, New Zealand, November 25–28, 2008, Revised Selected Papers, Part I, pp 1154–1162
Yamauchi K, Hayami J (2007) Incremental learning and model selection for radial basis function network through sleep. IEICE Trans Inform Syst E90-D(4): 722–735
Yamauchi K, Yamaguchi N, Ishii N (1999) Incremental learning methods with retrieving interfered patterns. IEEE Trans Neural Netw 10(6): 1351–1365
Yoneda T, Yamanaka M, Kakazu Y (1992) Study on optimization of grinding conditions using neural networks – a method of additional learning. J Japan Soc Prec Eng/Seimitsu kogakukaishi 58(10): 1707–1712
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Yamauchi, K. Optimal incremental learning under covariate shift. Memetic Comp. 1, 271–279 (2009). https://doi.org/10.1007/s12293-009-0018-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12293-009-0018-7