
Abstract
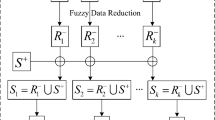
Aiming at effectively classifying imbalanced large data sets with two classes, this paper proposed a novel algorithm, which consists of four stages: (1) alternately over-sample p times between positive class instances and negative class instances; (2) construct l balanced data subsets based on the generated positive class instances; (3) train l component classifiers with extreme learning machine (ELM) algorithm on the constructed l balanced data subsets; (4) integrate the l ELM classifiers with simple voting approach. Specifically, in first stage, we firstly calculate the center of positive class instances, and then sample instance points along the line between the center and each positive class instance. Next, for each instance point in the new positive class, we firstly find its k nearest neighbors in negative class instances with MapRedcue, and then sample instance points along the line between the instance and its k nearest negative neighbors. The process of over-sampling is repeated p times. In the second stage, we sample instances l times from the negative class with the same size as the generated positive class instances. Each round of sampling, we put positive class and negative class instances together thus obtain l balanced data subsets. The experimental results show that the proposed algorithm can obtain promising speed-up and scalability, and also outperforms three other ensemble algorithms in G-mean.








Similar content being viewed by others


References
Garcá V, Mollineda RA, Sánchez JS (2014) A bias correction function for classification performance assessment in two-class imbalanced problems. Knowl Based Syst 59:66–74
He HB, Garcia EA (2009) Learning from imbalanced data. IEEE Trans Knowl Data Eng 21(9):1263–1284
Sun YM, Wong AKC, Kamel MS (2009) Classification of imbalanced data: a review. Int J Pattern Recognit Artif Intell 23(4):687–719
Díez-Pastor JF, Rodríguez JJ, García-Osorio C, Kuncheva LI (2015) Random balance: ensembles of variable priors classifiers for imbalanced data. Knowl Based Syst 85:96–111
Estabrooks A, Jo T, Japkowicz N (2004) A multiple resampling method for learning from imbalanced data sets. Comput Intell 20(1):18–36
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357
Kubat M, Matwin S (1997) Addressing the curse of imbalanced training sets: one-sided selection. In: Proceedings of international conference on machine learning, pp 179–186
Han H, Wang WY, Mao BH (2005) Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: Proceeding of international conference on intelligent computing, pp 878–887
He H, Bai Y, Garcia EA, Li S (2008) ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: Proceeding of international conference on neural networks, pp 1322–1328
Cieslak DA, Chawla NV (2008) Learning decision trees for unbalanced data. In: Proceedings of the 2008 European conference on machine learning and knowledge discovery in databases-part I, ECML PKDD’08, Springer, Berlin, Heidelberg, 2008, pp 241–256
Liu W, Chawla S, Cieslak DA, Chawla NV (2010) A robust decision tree algorithm for imbalanced data sets. Proc SIAM Int Conf Data Mining SDM 2010:766–777
Veropoulos K, Campbell C, Cristianini N (1999) Controlling the sensitivity of support vector machines. In: Proceedings of the international joint conference on AI, pp 55–60
Elkan C (2001) The foundations of cost-sensitive learning. In: Proceeding of international joint conference on artificial intelligence, pp 973–978
Ting KM (2002) An instance-weighting method to induce cost-sensitive trees. IEEE Trans Knowl Data Eng 14(3):659–665
Fan W, Stolfo SJ, Zhang J, Chan PK (1999) Adacost: misclassification cost-sensitive boosting. In: Presented at the 6th international conference on machine learning, San Francisco, CA, pp 97–105
Sun Y, Kamel MS, Wong AK, Wang Y (2007) Cost-sensitive boosting for classification of imbalanced data. Pattern Recogn 40(12):3358–3378
Seiffert C, Khoshgoftaar T, Hulse JV et al (2010) Rusboost: a hybrid approach to alleviating class imbalance. IEEE Trans Syst Man Cybern A Syst Hum 40(1):185–197
Liu XY, Wu J, Zhou ZH (2009) Exploratory undersampling for classimbalance learning. IEEE Trans Syst Man Cybern B Cybern 39(2):539–550
Sun Y, Kamel MS, Wong AK et al (2007) Cost-sensitive boosting for classification of imbalanced data. Pattern Recogn 40(12):3358–3378
Galar M, Fernández A, Barrenechea E et al (2012) A review on ensembles for the class imbalance problem-bagging boosting and hybrid-based approaches. IEEE Trans Syst Man Cybern C Appl Rev 42(4):463–484
Sun Z, Song Q, Zhu X et al (2015) A novel ensemble method for classifying imbalanced data. Pattern Recogn 48(5):1623–1637
Krawczyk B, Woźniak M, Schaefer G (2014) Cost-sensitive decision tree ensembles for effective imbalanced classification. Appl Soft Comput 14(Part C):554–562
Joshi M, Kumar V, Agarwal R (2001) Evaluating boosting algorithms to classify rare classes: comparison and improvements. In: Proceeding of IEEE international conference on data mining, pp 257–264
Río S, López V, Benítez JM (2014) Francisco Herrera. On the use of MapReduce for imbalanced big data using Random Forest. Information Sciences, Volume 285, 20 November 2014, pp 112–137
Ghazikhani A, Monsefi R, Yazdi HS (2014) Online neural network model for non-stationary and imbalanced data stream classification. Int J Mach Learn Cybern 5(1):51–62
Bhardwaj M, Bhatnagar V (2015) Towards an optimally pruned classifier ensemble. Int J Mach Learn Cybern 6(5):699–718
Chawla NV, Lazarevic A, Hall LO et al (2003) SMOTEBoost: improving prediction of the minority class in boosting. In: Proceeding of knowledge discovery in databases, pp 107–119
Hu S, Liang Y, Ma L et al (2009) MSMOTE: improving classification performance when training data is imbalanced. In: Proceeding of 2nd international workshop computing science engineering, vol 2, pp 13–17
Guo H, Viktor HL (2004) Learning from imbalanced data sets with boosting and data generation: the DataBoost-IM approach. ACM SIGKDD Explor Newsl 6(1):30–39
Galar M, Fernández A, Barrenechea E et al (2013) EUSBoost: enhancing ensembles for highly imbalanced data-sets by evolutionary undersampling. Pattern Recogn 46(12):3460–3471
Díez-Pastor JF, Rodríguez JJ, Garcá-Osorio CI et al (2015) Diversity techniques improve the performance of the best imbalance learning ensembles. Inf Sci 325:98–117
Wang XZ, Xing HJ, Li Y et al (2015) A study on relationship between aeneralization abilities and fuzziness of base classifiers in ensemble learning. IEEE Trans Fuzzy Syst 23(5):1638–1654
Dean J, Ghemawat S (2008) MapReduce: simplified data processing on large clusters. Commun ACM 51(1):107–113
Wang XZ (2015) Uncertainty in learning from big data-editorial. J Intell Fuzzy Syst 28(5):2329–2330
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70:489–501
Huang GB, Wang DH, Lan Y (2011) Extreme learning machines: a survey. Int J Mach Learn Cybern 2(2):107–122
Huang GB, Zhou HM, Ding XJ, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern B 42(2):513–529
Chacko BP, Vimal Krishnan VR, Raju G et al (2012) Handwritten character recognition using wavelet energy and extreme learning machine. Int J Mach Learn Cybern 3(2):149–161
Wang R, He YL, Chow CY, Ou FF, Zhang J (2015) Learning ELM-tree from big data based on uncertainty reduction. Fuzzy Sets Syst 258:79–100
Zhao SY, Chen H, Li CP et al (2015) A novel approach to building a robust fuzzy rough classifier. IEEE Trans Fuzzy Syst 23(4):769–786
Zhao SY, Chen H, Li CP et al (2014) RFRR: robust fuzzy rough reduction. IEEE Trans Fuzzy Syst 21(5):825–841
Wang XZ, Aamir R, Fu AM (2015) Fuzziness based sample categorization for classifier performance improvement. J Intell Fuzzy Syst 29(3):1185–1196
Wang R, Kwon S, Wang XZ et al (2015) Segment based decision tree induction with continuous valued attributes. IEEE Trans Cybern 45(7):1262–1275
Wang XZ, Dong CR, Fan TG (2007) Training T-S norm neural networks to refine weights for fuzzy if–then rules. Neurocomputing 70(13–15):2581–2587
Wang XZ, He Q, Chen DG et al (2005) A genetic algorithm for solving the inverse problem of support vector machines. Neurocomputing 68:225–238
Wang XZ, Hong JR (1998) On the handling of fuzziness for continuous-valued attributes in decision tree generation. Fuzzy Sets Syst 99(3):283–290
Huang G, Huang GB, Song S, You K (2015) Trends in extreme learning machines: a review. Neural Netw 61:32–48
Huang GB, Chen L, Siew CK (2006) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw 17(4):879–892
Lu SX, Wang XZ, Zhanga GQ et al (2015) Effective algorithms of the Moore–Penrose inverse matrices for extreme learning machine. Intell Data Anal 19(4):743–760
Frank A, Asuncion A (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
He Q, Shang T (2013) Parallel extreme learning machine for regression based on MapReduce. Neurocomputing 102:52–58
Hastie T, Tibshirani R, Friedman J (2009) The elements of statistical learning: data mining, inference, and prediction, 2nd edn. Springer, New York
Acknowledgments
This research is supported by the national natural science foundation of China (61170040, 71371063), by the natural science foundation of Hebei Province (F2013201110, F2013201220), by the Key Scientific Research Foundation of Education Department of Hebei Province (ZD20131028), and by the Opening Fund of Zhejiang Provincial Top Key Discipline of Computer Science and Technology at Zhejiang Normal University, China.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhai, J., Zhang, S. & Wang, C. The classification of imbalanced large data sets based on MapReduce and ensemble of ELM classifiers. Int. J. Mach. Learn. & Cyber. 8, 1009–1017 (2017). https://doi.org/10.1007/s13042-015-0478-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-015-0478-7