
Abstract
Deep convolution neural network has become the primary framework for semantic image segmentation in recent years, and most existing methods using deep learning have achieved a great improvement on the performance compared with traditional methods. Although most methods using fully convolutional networks are concerned about the segmentation of small objects or small/fine parts of objects, the small object segmentation is still a challenging problem. To the best of our knowledge, the main reason is that several pooling or convolution operations with two or more stride size cause the features of small objects to vanish in later layers, even if taking different kinds of multi-scale measures. In the paper, we design a novel differential network which addresses the small object segmentation. Specifically, our networks include two pipelines: the first pipeline is served as the primary segmentation network using existing methods, and the second one is a refine network that we propose. The score maps of two networks are merged by calculating the sum of corresponding channels in their last layers. We first learn the primary segmentation network to get a coarse segmentation model, and then train the two networks jointly in an end-to-end fashion. Experiments show that our method can deal with small objects effectively. The segmentation performance of our method on PASCAL VOC 2012 dataset is superior to the state-of-the-art methods using only the primary segmentation model without applying a differential network.









Similar content being viewed by others

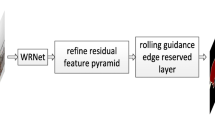

Change history
08 January 2019
The original article can be found online.
References
Álvarez JM, Salzmann M, Barnes N (2016) Exploiting large image sets for road scene parsing. IEEE Trans Intell Transp Syst 17:2456–2465
Arnab A, Jayasumana S, Zheng S, Torr PH (2016) Higher order conditional random fields in deep neural networks. In: European conference on computer vision. Springer, pp 524–540
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2014) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv preprint arXiv:14127062
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2018) Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFS. IEEE Trans Pattern Anal Mach Intell 40:834–848
Chen L-C, Yang Y, Wang J, Xu W, Yuille AL (2016) Attention to scale: scale-aware semantic image segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3640–3649
Chen X, Mottaghi R, Liu X, Fidler S, Urtasun R, Yuille A (2014) Detect what you can: detecting and representing objects using holistic models and body parts. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1971–1978
Cordts M et al (2016) The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3213–3223
Eigen D, Fergus R (2015) Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of the IEEE international conference on computer vision, pp 2650–2658
Everingham M, Eslami SA, Van Gool L, Williams CK, Winn J, Zisserman A (2015) The pascal visual object classes challenge: a retrospective. Int J Comput Vis 111:98–136
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 580–587
Girshick R, Donahue J, Darrell T, Malik J (2016) Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans Pattern Anal Mach Intell 38:142–158
Hariharan B, Arbeláez P, Girshick R, Malik J (2014) Simultaneous detection and segmentation. In: European conference on computer vision. Springer, pp 297–312
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Huang G, Liu Z, Weinberger KQ, van der Maaten L (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, vol 2, p 3
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning, pp 448–456
Jégou S, Drozdzal M, Vazquez D, Romero A, Bengio Y (2017) The one hundred layers tiramisu: fully convolutional densenets for semantic segmentation. In: Computer vision and pattern recognition workshops (CVPRW). IEEE conference on, 2017. IEEE, pp 1175–1183
Jia Y et al (2014) Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM international conference on Multimedia, ACM, pp 675–678
Kohli P, Torr PH (2009) Robust higher order potentials for enforcing label consistency. Int J Comput Vis 82:302–324
Krähenbühl P, Koltun V (2011) Efficient inference in fully connected CRFs with Gaussian edge potentials. Adv Neural Inf Process Syst 24:109–117
Lin G, Milan A, Shen C, Reid I (2017) Refinenet: multi-path refinement networks for high-resolution semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5168–5177
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3431–3440
Peng C, Zhang X, Yu G, Luo G, Sun J (2017) Large kernel matters—improve semantic segmentation by global convolutional network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1743–1751
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems. pp 91–99
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: International conference on learning representations
Yu F, Koltun V (2016) Multi-scale context aggregation by dilated convolutions. In: International conference on learning representations
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. In: IEEE conference on computer vision and pattern recognition (CVPR). pp 2881–2890
Zheng S et al (2015) Conditional random fields as recurrent neural networks. In: Proceedings of the IEEE international conference on computer vision, pp 1529–1537
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2014) Object detectors emerge in deep scene cnns arXiv preprint arXiv:14126856
Acknowledgements
This work is supported by National Natural Science Foundation of China (61876087, 61432008, 61272222, 61603193), Natural Science Foundation of Jiangsu Province (BK20171479, BK20161020, BK20161560), and Program of Natural Science Research of Jiangsu Higher Education Institutions (15KJB520023).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original version of this article was revised: Unfortunately, the Fig. 8 and the acknowledgment section was published incorrectly. Now, the article has been revised with the corrected figure and the acknowledgment.
Rights and permissions
About this article

Cite this article
Hu, T., Yang, M., Yang, W. et al. An end-to-end differential network learning method for semantic segmentation. Int. J. Mach. Learn. & Cyber. 10, 1909–1924 (2019). https://doi.org/10.1007/s13042-018-0889-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-018-0889-3