
Abstract
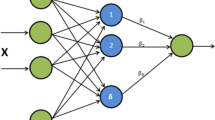
A seemingly unrelated regression (SUR) refers to several individual equations among which there is not an explicit connection such as one equation’s observation is another equation’s response, but there exists an implicit relation represented by correlated disturbances of response variables. In this paper, SUR is applied to extreme learning machine (ELM) which is a single hidden layer feed-forward neural network where input weights and hidden layer biases are randomly assigned but the weight parameters between hidden and output layers are least-square solutions of a regression equation. A correlation-based extreme learning machine is built using the auxiliary sample which is related to the main sample which we focus on. Considering the weights between hidden and output layers in ELM as a random vector, we derive an explicit representation for the vector’s covariance matrix. The proof of theorems and simulation process indicate that the stronger correlation between main sample and auxiliary sample is, the higher generalization ability is.

Similar content being viewed by others

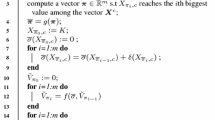
References
Zellner A (1962) An efficient method of estimating seemingly unrelated regressions and tests for aggregation bias. J Am Stat Assoc 57(298):348–368
Hubert M, Verdonck T, Yorulmaz z (2016) Fast robust sur with economical and actuarial applications. Stat Anal Data Min ASA Data Sci J 10(2):77–88
Wang H (2010) Sparse seemingly unrelated regression modelling: applications in finance and econometrics. Comput Stat Data Anal 54(11):2866–2877
Foschi P, Kontoghiorghes EJ (2004) A computationally efficient method for solving sur models with orthogonal regressors. Linear Algebra Appl 388(1):193–200
Fraser D, Rekkas M, Wong A (2005) Highly accurate likelihood analysis for the seemingly unrelated regression problem. J Econom 127(1):17–33
Dufour J-M, Khalaf L (2002) Exact tests for contemporaneous correlation of disturbances in seemingly unrelated regressions. J Econom 106(1):143–170
Zellner A, Ando T (2010) A direct monte carlo approach for bayesian analysis of the seemingly unrelated regression model. J Econom 159(1):33–45
Zellner A, Huang DS (1962) Further properties of efficient estimators for seemingly unrelated regression equations. Int Econ Rev 3(3):300–313
Magnus JR (1978) Maximum likelihood estimation of the gls model with unknown parameters in the disturbance covariance matrix. J Econom 7(3):281–312
Kakwani NC (1967) The unbiasedness of Zellner’s seemingly unrelated regression equations estimators. Publ Am Stat Assoc 62(317):141–142
Zellner A (1963) Estimators for seemingly unrelated regression equations: some exact finite sample results. J Am Stat Assoc 58(304):977–992
Revankar NS (1974) Some finite sample results in the context of two seemingly unrelated regression equations. J Am Stat Assoc 69(345):187–190
Revankar NS (1976) Use of restricted residuals in sur systems: some finite sample results. J Am Stat Assoc 71(353):183–188
Liu A (2002) Efficient estimation of two seemingly unrelated regression equations. J Multivar Anal 82(2):445–456
Ma T, Ye R (2010) Efficient improved estimation of the parameters in two seemingly unrelated regression models. J Stat Plan Inference 140(9):2749–2754
Wang L, Lian H, Singh RS (2011) On efficient estimators of two seemingly unrelated regressions. Stat Probab Lett 81(5):563–570
Zhao L, Xu X (2017) Generalized canonical correlation variables improved estimation in high dimensional seemingly unrelated regression models. Stat Probab Lett 126:119–126
Kurata H, Kariya T (1996) Least upper bound for the covariance matrix of a generalized least squares estimator in regression with applications to a seemingly unrelated regression model and a heteroscedastic model. Ann Stat 24(4):1547–1559
Chauvin Y, Rumelhart DE (1995) Back-propagation: theory, architecture, and applications. Lawrence Erlbaum Associates Inc., Hillsdale
Huang G-B, Zhu Q-Y, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501
Huang G-B, Zhou HM, Ding XJ, Zhang R (2012) Extreme learning machine for regression and multi-class classification. IEEE Trans Syst Man Cybern Part B Cybern 42(2):513–529
Huang Z, Yu Y, Gu J (2015) A novel method for traffic sign recognition based on extreme learning machine. In: Intelligent control and automation, pp 1451–1456
Zhang L, Wang X, Huang GB, Liu T, Tan X (2018) Taste recognition in e-tongue using local discriminant preservation projection. IEEE Trans Cybern PP(99):1–14
Wang J, Zhang L, Cao J-J, Han D (2018) Nbwelm: naive bayesian based weighted extreme learning machine. Int J Mach Learn Cybern 9(1):21–35
Wang R, Chen D, Kwong S (2014) Fuzzy rough set based active learning. IEEE Trans Fuzzy Syst 22(6):1699–1704
Wang R, Wang X-Z, Kwong S, Chen X (2017) Incorporating diversity and informativeness in multiple-instance active learning. IEEE Trans Fuzzy Syst 25(6):1460–1475
Srivastava DG (1987) Seemingly unrelated regression models. Dekker, New York
Wang X-Z, Wang R, Chen X (2018) Discovering the relationship between generalization and uncertainty by incorporating complexity of classification. IEEE Trans Cybern 48(2):703–715
Cao J, Zhang K, Luo M, Yin C, Lai X (2016) Extreme learning machine and adaptive sparse representation for image classification. Neural Netw 81(C):91–102
Zhao H, Guo X, Wang M, Li T, Pang C, Georgakopoulos D (2018) Analyze EEG signals with extreme learning machine based on PMIS feature selection. Int J Mach Learn Cybern 9(2):243–249
Wang R, Chow C-Y, Kwong S (2016) Ambiguity based multiclass active learning. IEEE Trans Fuzzy Syst 24(1):242–248
Luo X, Yang X, Jiang C, Ban X (2018) Timeliness online regularized extreme learning machine. Int J Mach Learn Cybern 9(3):465–476
Zhao X, Cao W, Zhu H, Ming Z, Ashfaq RAR (2018) An initial study on the rank of input matrix for extreme learning machine. Int J Mach Learn Cybern 9(5):867–879
Zhao L, Yan L, Xu X (2018) High correlated residuals improved estimation in the high dimensional SUR model. Commun Stat Simul Comput 47(7):1583–1605. https://doi.org/10.1080/03610918.2017.1309429
Acknowledgements
We would like to express our gratitude to all those who helped me during the writing of this paper. We gratefully acknowledge the help of our supervisor, Prof. XiZhao Wang, who has offered us valuable suggestions to revise and improve this paper. This work was supported in part by the National Natural Science Foundation of China (Grant 61772344, Grant 61732011, and Grant 61811530324), in part by the Natural Science Foundation of SZU (Grant 827-000140, Grant 827-000230, and Grant 2017060), in part by Basic Research Project of Knowledge Innovation Program in ShenZhen (JCYJ20180305125850156).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Proof of Theorem 3
A Proof of Theorem 3
Proof
For the sake of brevity we Let
Then
and
From Theorem 1 we know that \(var(\hat{\varvec{\beta}}_{ ols}^*) =\sigma _{11}(\mathbf{H}{^*}'\mathbf{H}^*)^{-1}\).
Obviously \(\mathbf{A}_i\) and \(\mathbf{I}-\mathbf{A}_i\) are both symmetric idempotent matrices with order M and orthogonal to each other, \(i=1,2\). Let \(k_1=rank(\mathbf{H}{^*})\), and \(k_2=rank(\mathbf{H})\). There exists and \(M\times (M-k_i)\) full column rank matrix \(\mathbf{B}_i\) such that \(\mathbf{A}_i=\mathbf{B}_i\mathbf{B}_i'\), \(i=1,2\) and \(M\times (M-k_1)\) matrix \(\mathbf{P}\) such that \(\mathbf{I}-\mathbf{A}_1=\mathbf{P}\mathbf{P}'\). We know that \(\mathbf{P}'\mathbf{P}=\mathbf{I}_{k_1}, \mathbf{P}'\mathbf{B}_1=\mathbf{O}_{(k_1)\times (M-k_1)}\) and \(\mathbf{B}_i'\mathbf{B}_i=\mathbf{I}_{M-k_i},\)\(i=1,2\). Let
Then
and
According to (13) we have that
and
From (15) we know that
Since the distribution of \(\varvec{\eta}\) is is symmetric about the origin, we have that
From (17) we know that
Since
Combining with (15) we know that
It is easy to check that \(\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2\) and \(\mathbf{I}_{M-k_2}-\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2\) are both symmetric idempotent matrice. Since \(\text {rank}(\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2)=tr(\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2)=tr(\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2)=tr(\mathbf{A}_2\mathbf{A}_1)=M-k_1-k_2,\) we can find an \((M-k_2)\times (M-k_1-k_2)\)-matrix \(\mathbf{Q}_2^c\) and an \((M-k_2)\times k_1\)-matrix \(\mathbf{Q}_2\) such that \(\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2=\mathbf{Q}_2^c \mathbf{Q}_2^{c'}\), \(I_{M-k_2}-\mathbf{B}_2'\mathbf{A}_1\mathbf{B}_2=\mathbf{Q}_2\mathbf{Q}_2'\) and \((\mathbf{Q}_2,\mathbf{Q}_2^{c})\) is an orthogonal matrix.
Let
Then
Furthermore,
Let
and write \(\varvec{\zeta}=(w_1,w_2,\ldots ,w_{k_1})^T\). Then the (i, j)th element of \(\Delta\) is denoted by \(\Delta (i,j)\) where \(\Delta (i,j)=E\Bigg [\frac{(\varvec{\zeta}^{c'} \varvec{\zeta}^c)^2}{(\varvec{\zeta}' \varvec{\zeta}+\varvec{\zeta}^{c'} \varvec{\zeta}^c)^2}w_iw_j\Bigg ], (1\le i,j \le k_1)\). Since \(w_1,w_2,\ldots ,w_{k_1}\) are independent and identically distributed random variables, when \(i\ne j,\)
When \(i=j<k_1\)
Since \(\varvec{\zeta}^{c^T} \varvec{\zeta}^c\sim \chi ^2(M-k_2-k_1),\,\,\varvec{\zeta}^T\varvec{\zeta}\sim \chi ^2(k_1)\) and \(\varvec{\zeta}^{c^T} \varvec{\zeta}^c\) is independent of \(\varvec{\zeta}^T\varvec{\zeta}\). we have that
meanwhile \(\varvec{\zeta}^{c^T} \varvec{\zeta}^c/(\varvec{\zeta}^T\varvec{\zeta}+\varvec{\zeta}^{c^T}\varvec{\zeta}^c)\) is independent of \(\varvec{\zeta}^T\varvec{\zeta}+\varvec{\zeta}^{c^T} \varvec{\zeta}^c\). Hence
Combining with \(\mathbf{A}_1\mathbf{A}_2=\mathbf{A}_2\mathbf{A}_1\) and \(\mathbf{A}_2\mathbf{P}=\mathbf{P}\), we have that
Similarly
Substituting (20) and (21) into (19) , we have that
Then we calculate the last term in (14). From (15) and the symmetry of distribution we have that
Combining with (17) and (16) we know that
Here, the third equation is hold for \(\mathbf{P}\mathbf{P}'=\mathbf{I}-\mathbf{A}_1,\, (\mathbf{I}-\mathbf{A}_1)\mathbf{A}_2=(\mathbf{I}-\mathbf{A}_1),\) and \((\mathbf{I}-\mathbf{A}_1)\mathbf{A}_1=\mathbf{0}.\) The last equation is hold for (15) and (18). Note that \((\mathbf{I}-\mathbf{A}_1) \mathbf{B}_1\mathbf{B}_1'=(\mathbf{I}-\mathbf{A}_1) \mathbf{A}_1=\mathbf{0},\) therefore
Follows the same method as in Eq. (20), we get that
Substituting (22), (23) and into (14), we finally have the variance of \({\hat{\beta}}_{1FG}\) is
Let
and
Then
\(\square\)
Rights and permissions
About this article

Cite this article
Zhao, L., Zhu, J. Learning from correlation with extreme learning machine. Int. J. Mach. Learn. & Cyber. 10, 3635–3645 (2019). https://doi.org/10.1007/s13042-019-00949-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-019-00949-y