
Abstract
Many real-world datasets nowadays are of regression type, while only a few dimensionality reduction methods have been developed for regression problems. On the other hand, most existing regression methods are based on the computation of the covariance matrix, rendering them inefficient in the reduction process. Therefore, a BMA-based multi-objective feature selection method, GBMA, is introduced by incorporating the Nash equilibrium approach. GBMA is intended to maximize model accuracy and minimize the number of features through a less complex procedure. The proposed method is composed of four steps. The first step involves defining three players, each of which is trying to improve its objective function (i.e., model error, number of features, and precision adjustment). The second step includes clustering features based on the correlation therebetween and detecting the most appropriate ordering of features to enhance cluster efficiency. The third step comprises extracting a new feature from each cluster based on various weighting methods (i.e., moderate, strict, and hybrid). Finally, the fourth step encompasses updating players based on stochastic search operators. The proposed GBMA strategy explores the search space and finds optimal solutions in an acceptable amount of time without examining every possible solution. The experimental results and statistical tests based on ten well-known datasets from the UCI repository proved the high performance of GBMA in selecting features for solving regression problems.
























Similar content being viewed by others


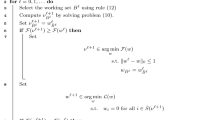
References
Sen P, Namata G, Bilgic M, Getoor L, Gallagher B, Eliassi Rad T (2008) Collective classification in network data. AI Mag 29(3):93–106
Bhagat S, Cormode G, Muthukrishnan S (2011) Node classification in social networks. In: Aggarwal C (ed) Social network data analytics. Springer, Boston, pp 115–148
Liben-Nowell D, Kleinberg J (2007) The link-prediction problem for social networks. J Assoc Inf Sci Technol 58(7):1019–1031
Ou M, Cui P, Pei J, Zhang Z, Zhu W (2016) Asymmetric transitivity preserving graph embedding. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 1105–1114
Grover A, Leskovec J (2016) node2vec: Scalable feature learning for networks. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 855–864
Gong M, Yao C, Xie Y, Xu M (2020) Semi-supervised network embedding with text information. Pattern Recognit 104:107347
Shi M, Tang Y, Zhu X (2019) MLNE: Multi-label network embedding. IEEE Trans Neural Netw Learn Syst 1–14
Shi M, Tang Y, Zhu X, Liu J, He H (2020) Topical network embedding. Data Min Knowl Disc 34(1):75–100
Liu Y, Nie F, Gao Q, Gao X, Han J, Shao L (2019) Flexible unsupervised feature extraction for image classification. Neural Netw 115:65–71
Wang K-J, Chen K-H, Angelia M-A (2014) An improved artificial immune recognition system with the opposite sign test for feature selection. Knowl Based Syst 71:126–145
Marill T, Green D (1963) On the effectiveness of receptors in recognition systems. IEEE Trans Inf Theory 9:11–17
Hancer E, Xue B, Zhang M, Karaboga D, Akay B (2018) Pareto front feature selection based on artificial bee colony optimization. Inf Sci 422:462–479
Ma B, Xia Y (2017) A tribe competition-based genetic algorithm for feature selection in pattern classification. Appl Soft Comput 58:328–338
Mansouri N, Mohammad Hasani Zade B, Javidi MM (2019) Hybrid task scheduling strategy for cloud computing by modified particle swarm optimization and fuzzy theory. Comput Ind Eng 130:597–633
Mahdavi Jafari M, Khayati GR (2018) Prediction of hydroxyapatite crystallite size prepared by sol–gel route: gene expression programming approach. J Sol Gel Sci Technol 86(1):112–125
Xu RF, Lee SJ (2015) Dimensionality reduction by feature clustering for regression problems. Inf Sci 299:42–57. https://doi.org/10.1016/j.ins.2014.12.003
Zhang Q, Wang R, Yang J, Lewis A, Chiclana F, Yang S (2019) Biology migration algorithm: a new nature-inspired heuristic methodology for global optimization. Soft Comput 23(16):7333–7358. https://doi.org/10.1007/s00500-018-3381-9
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Yang X-S (2010) A new metaheuristic bat-inspired algorithm. In Nature inspired cooperative strategies for optimization (NISCO 2010), studies in computational intelligence. Springer, Berlin, pp 65–74
Li XT, Zhang J, Yin MH (2014) Animal migration optimization: an optimization algorithm inspired by animal migration behavior. Neural Comput Appl 24(7–8):1867–1877
Yang X-S, Deb S (2010) Engineering optimization by cuckoo search. Int J Math Model Numer Optim 1(4):330–343
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) GSA: a gravitational search algorithm. Inf Sci 179(13):2232–2248
Simon D (2008) Biogeograph-based optimization. IEEE Trans Evol Comput 12(6):702–713
Eberhart RC, Kennedy J (1995) A new optimizer using particle swarm theory. In: Proceedings of the sixth international symposium on micro machine and human science, pp 39–43
Yasini S, Sitani M B N, Kirampor A (2016) Reinforcement learning and neural networks for multi-agent nonzero-sum games of nonlinear constrained-input systems. Int J Mach Learn Cybern 7:967–980
Yang J, Jiang B, Lv Z, Raymond Choo KK (2020) A task scheduling algorithm considering game theory designed for energy management in cloud computing. Future Gen Comput Syst 105:985–992
Peng X, Xu D (2013) A local information-based feature-selection algorithm for data regression. Pattern Recogn 46:2519–2530
Wang L, Zhu J, Zou H (2006) The doubly regularized support vector machine. Stat Sin 16(2):589–615
Berrendero JR, Cuevas A, Torrecilla JL (2016) The mRMR variable selection method: a comparative study for functional data. J Stat Comput Simul 86(5):891–907
Kira K, Rendell LA (1992) The feature selection problem: traditional methods and a new algorithm. In: Proceedings of ninth national conference on AI, pp 129–134
Fukunaga K (1990) Introduction to statistical pattern recognition, 2nd edn. Academic Press, New York
Kwak N, Lee JW (2010) Feature extraction based on subspace methods for regression problems. Neurocomputing 73(10–12):1740–1751
Kwak N, Kim C (2006) Dimensionality reduction based on ICA for regression problems. In: Proceedings of the international conference on artificial neural networks, pp 1–10
Robnik Sikonja M, Kononenko I (1997) An adaptation of relief for attribute estimation in regression. In: Proceedings of the fourteenth ICML, pp 296–304
Arauzo-Azofra A, Manuel Benitez J, Castro JL (2004) A feature set measure based on relief. In: Proceedings of the fifth international conference on recent advances in soft computing, pp 104–109
Radovic M, Ghalwash M, Filipovic N, Obradovic Z (2017) Minimum redundancy maximum relevance feature selection approach for temporal gene expression data. BMC Bioinform 18:1
Rao H, Shi X, Rodrigue AK, Feng J, Yuan X, Elhoseny M, Yuan X, Gu L (2019) Feature selection based on artificial bee colony and gradient boosting decision tree. Appl Soft Comput 74:634–642
Zhang L, Mistry K, Peng Lim C, Neoh SC (2018) Feature selection using firefly optimization for classification and regression models. Decis Support Syst 106:64–85
Ghimatgar H, Kazemi K, Helfroush MS, Aarabi A (2018) An improved feature selection algorithm based on graph clustering and ant colony optimization. Knowl Based Syst 159:270–285
Ding W, Lin CT, Prasad M (2018) Hierarchical co-evolutionary clustering tree-based rough feature game equilibrium selection and its application in neonatal cerebral cortex MRI. Expert Syst Appl 101:243–257
Liu G, Xiao Z, Hua Tan G, Li K, Chronopoulos AT (2020) Game theory-based optimization of distributed idle computing resources in cloud environments. Theor Comput Sci 806:468–488
Cheng FY (1999) Multiobjective optimum design of structures with genetic algorithm and game theory: application to life-cycle cost design. Computational mechanics in structural engineering. Elsevier, Amsterdam, pp 1–6
Périaux J, Chen HQ, Mantel B, Sefrioui M, Sui HT (2001) Combining game theory and genetic algorithms with application to DDM-nozzle optimization problems. Finite Elem Anal Des 37(5):417–429
Kwak SK, Kim JH (2017) Statistical data preparation: management of missing values and outliers. Korean J Anesthesiol 70(4):407–411
Gibert K, Marrè MS, Izquierdo J (2016) A survey on pre-processing techniques: relevant issues in the context of environmental data mining. AI Commun 29:627–663
Leavline EJ, Singh D (2016) Model-based outlier detection system with statistical preprocessing. J Mod Appl Stat Methods 15(1):789–801
Kang H (2013) The prevention and handling of the missing data. Korean J Anesthesiol 64(5):402–406
Moradi P, Gholampour M (2016) A hybrid particle swarm optimization for feature subset selection by integrating a novel local search strategy. Appl Soft Comput 43:117–130
Li D (2014) Cooperative quantum-behaved particle swarm optimization with dynamic varying search areas and Lévy flight disturbance. Sci World J
UCI Dataset (2019) https://archive.ics.uci.edu/ml
Tian D, Zhao X, Shi Z (2019) Chaotic particle swarm optimization with sigmoid-based acceleration coefficients for numerical function optimization. Swarm and evolutionary computation, 51. Elsevier, Amsterdam
Mittal N, Singh U, Sohi BS (2016) Modified grey wolf optimizer for global engineering optimization. Applied computational intelligence and soft computing. Springer, New York
Mateos-García D, García-Gutiérrez J, Riquelme-Santos JC (2016) An evolutionary voting for k-nearest neighbours. Expert Syst Appl 43:9–14
Weston J, Mukherjee S, Chapelle O, Pontil M, Poggio T, Vapnik V (2001) Feature selection for SVMs. In: Advances in neural information processing systems, pp 668–674
Yu X, Zhou Y, Liu XF (2019) A novel hybrid genetic algorithm for the location routing problem with tight capacity constraints. Appl Soft Comput J 85:105760
Mistry K, Zhang L, Neoh SC, Lim CP, Fielding B (2017) A micro-GA embedded PSO feature selection approach to intelligent facial emotion recognition. IEEE Trans Cybern 47(6):1496–1509
Wilcoxon F (1945) Individual comparisons by ranking methods. Biometr Bull 1(6):80–83
Gore S, Govindaraju V (2016) Feature selection using cooperative game theory and relief algorithm. In: 8th International conference on knowledge, information, and creativity support systems, pp 401–412
Duda RO, Hart PE, Stork DG (2012) Pattern classification. Wiley, New York
Hall MA, Smith LA (1999) Feature selection for machine learning: comparing a correlation-based filter approach to the wrapper. In: Proceedings of the twelfth international FLAIRS conference
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendices
Appendix 1: The performance of swarm-based methods on classification datasets
To evaluate the performance of GBMA for classification problems, ten classification datasets are assumed that are described in Table 8.
GBMA is compared with three swarm-based feature selection strategies for classification datasets as follows:
-
Hybrid genetic algorithm (HGA) [56]: It integrates the exploration capability of a genetic algorithm into the exploitation capability of neighborhood local search.
-
Graph clustering-based ant colony optimization (GCACO) [39]: It represents the feature space by dividing the features into some clusters based on a community detection strategy. It then determines the appropriate subset of features using the ant colony-based search approach.
-
Modified firefly algorithm (MFA) [38]): It improves the firefly algorithm by Simulated Annealing (SA) and chaotic diversified search approach to select optimal feature subsets.
They are compared in terms of classification accuracy (CA), the number of selected features (NSF), F-measure, and area under curve (AUC) by ten classification datasets. In this evaluation, the fitness function includes two objectives: (1) the accuracy that is selected by the support vector machine (SVM) and the number of selected features. The fitness function is determined using Eq. (22):
where w1 and w2 denote the weights of classification accuracy and w1 + w2 = 1. Likewise, NSF represents the number of selected features. Since the classification accuracy is more important than the NSF, we assign w1 = 0.9 and w2 = 0.1 as recommended in related studies [57].
We must modify players and the fitness function of GBMA to use it for classification problems. Since the original proposed algorithm (i.e., GBMA) is introduced for regression datasets, the number of players is reduced to two. Equation (22) is used as a fitness function. Figure


Plots of the number of the selected features and the corresponding accuracy
23 indicates the comparison of the classification performance between GBMA with three feature selection algorithms based on accuracy and the number of features. The horizontal axis and vertical axis show the number of features in rectangular coordinates and accuracy, respectively. The top-left points are the best results since they have higher accuracy and a smaller number of features. The comparison of GBMA with three methods is categorized into three parts. The first part is excellent results obtained for Ionosphere, SpectEW, Madelon, and KrvskpEW datasets as GBMA obtains higher accuracy and a smaller number of features. On these datasets, several solutions of GBMA are located at the upper and upper-left of optimal solutions of other algorithms. For the KrvskpEW dataset, the optimal solution is the point with 0.925 accuracy and six features created by GBMA. We can see several black points at the upper, meaning the better results of GBMA in comparison with other feature selection algorithms. Put differently, GBMA has better convergence ability for the first objective and better diversity searching process for the second objective. There is one red point belonging to MFA locating under the left part of the figure with an accuracy of 0.85 and 5 number of features.
The second part of competitive results represents that GBMA only achieves higher accuracy value with the same number of features. Zoo, Satellite, and Musk datasets yield these results. For the Musk dataset, GBMA finds the optimal solution (i.e., black point) with a 0.96 accuracy and 62 generated features. It can be seen that three black points located at the upper part of blue and red points in the left part of the rectangle, where they are not on the upper left. It proves that GBMA has three solutions better than GCACO and MFA. Although GBMA cannot indicate the solutions with lower dimensions and higher accuracy, it still can search higher accuracy solutions with the same dimensions by the powerful diversity capability.
The third part of the analysis describes the failure results of GBMA. For the SonarEW and WaveformEW datasets, GBMA has lower accuracy and a larger number of features. This can be mainly ascribed to its inability to conduct a comprehensive evaluation in limited iteration times due to its computation. In short, GBMA presents better results than other feature selection algorithms through an analysis of this section.
In the next experiment, we depict the areas under ROC curves (AUCs) and F-measure of four methods for ten datasets by the boxes in Fig.




AUC and F-measure for classification datasets
24. AUC is one of the main evaluation metrics for classification problems that shows AUCs. Moreover, F-measure is a commonly used performance metric obtained by the weighted harmonic mean (WHM) of the precision (i.e., positive predictive value or PPV) and recall (i.e., sensitivity). F-measure with value 1 and 0 indicate the best and worst results, respectively. Box plots are used to provide a stability analysis of the proposed feature selection method (i.e., GBMA) and other compared methods. The empirical distribution, variation information, median, symmetry, and skewness on the dataset can be easily represented by box plots.
From Fig. 24, we can observe that the proposed algorithm gives superior and consistent results for all the evaluated datasets except SonarEW and WaveformEW, where GCACO has better performance. GCACO improves AUC and F-measure by 7% and 8%, respectively, compared to GBMA. This is because the migration phase after two random neighbors is used for updating the solution. Then, the positions of solutions (sequencing and weighting parts) are close to each other, and a new solution has not been practically produced. Hence, the probability of being trapped in local optimum has been increased.
The proposed algorithm (i.e., GBMA) outperforms HGA on all datasets and improves AUC and F-measure by 34% and 38%, respectively. The main reason is that HGA cannot determine near-optimal solutions and cannot perform exploitation very well, and it may get stuck in local optima. The results obtained from Fig. 24 are listed as follows:
-
The median of F-measure and AUC for GBMA is often higher than the other feature selection algorithms.
-
The AUC and F-measure of GBMA are higher than 85% for all evaluated datasets.
-
The difference between the minimum and maximum AUC and F-measure for GBMA is very insignificant (less than 10%) in most datasets.
-
These results prove the superiority of GBMA in selecting the prominent feature set.
Table 9 presents the average computation times of four algorithms (i.e., GBMA, GCACO, MFA, and HGA) over 30 independent runs to indicate how fast an algorithm implements the search process. As indicated, GBMA has the lowest average computation time (bold numbers) compared to the other methods for seven datasets. On two of the ten datasets, HGA requires less computation time than the other methods, and MFA requires less time for one dataset.
Additionally, Table 9 ranks the performance of the methods based on their average computation times. We can observe that GBMA exhibits the lowest average computation time overall, followed by MFA, HGA, and GCACO. Table 9 represents the results of three groups of Wilcoxon rank-sum tests to compare two related methods. Frank Wilcoxon [58] introduced the Wilcoxon rank-sum test that assigns ranks to all the scores of one set and then sums the ranks in each set. This test is defined as the nonparametric version of the t test for two independent sets, and any difference in the two rank sums appears due to sampling error.
According to Table 9, GBMA outperforms GCACO, MFA, and HGA. The proposed method has superiority over all other methods on all datasets except for MFA on KrvskEW and HGA on SpectEW at a significance level of 0.05 and similar results for HGA on the Zoo dataset. Moreover, the results of Table 9 are obtained over 30 runs for each evaluated strategy. While the number of runs in which GBMA outperforms GCACO, MFA, and HGA in terms of CA is 12, 14, and 19, respectively, these results are represented in the last row of the Wilcoxon rank-sum table.
Appendix 2: The performance of filter methods on classification datasets
The proposed method is compared with three filter methods for classification datasets as follows:
-
Cooperative game theory with relief approach (CGTR) [59]: It combines the game theory with a relief method to evaluate the contribution of features.
-
Fisher-score (F-score) [60]: It selects a feature subset such that the between-class scatter is maximized while the within-class scatter is minimized.
-
Correlation-based feature selection (CFC) [61]: It applies a correlation-based strategy with less computation to evaluate the importance of features.
The proposed algorithm is evaluated in terms of classification accuracy (CA), the number of selected features (NSF), F-measure, and area under curve (AUC). The performance of the compared methods on different classification datasets can be seen from Fig.


Spider web diagrams for different classification datasets
25. For most datasets, the proposed method (i.e., GBMA) achieves better results. For example, on KrvspEW, GBMA obtains 0.98, 13.2, 0.976, and 0.982 for CA, NSF, F-measure, and AUC, respectively. While CGTR obtains 0.91, 18.2, 0.92, and 0.915. Thus, GBMA improves CA and NSF by 8% and 30%, respectively, compared to CGTR. The main weakness of the CGTR algorithm is that it uses the information gain as an evaluation parameter of the correlation between features. Hence, the relevant features cannot be specified correctly on datasets that have features with a large number of distinct values such as Musk and KrvskpEW. Besides, GBMA improves AUC and F-measure by 22% and 25%, respectively, in comparison with F-score. The disadvantage of the F-score is that it does not reveal the mutual information among features. In other words, it considers the discriminative power of each feature independently rather than together, rendering it unable to select appropriate features.
Appendix 3: Statistical tests for swarm-based and filter methods
The Friedman and Holm tests are performed for swarm-based classification methods (i.e., GBMA, HGA, GCACO, and MFA) and filter methods (i.e., GBMA, CGTR, and F-score) in terms of classification accuracy (CA) and the number of selected features (NSF). Each compared method is run 30 times, and the average classification accuracy for each method is calculated.
Figure

Friedman ranks based on CA
26 depicts Friedman’s ranks (i.e., the vertical axis) of seven methods to analyze the outcomes of experiments. There are significant differences between the classification accuracies of the methods since the obtained P value is 8.70E−8, which is lower than the desired significance level (i.e., α = 0.05). The GBMA strategy achieves the highest rank with a difference of 0.95 from the subsequent strategy. Figure

Holm test based on CA
27 displays Holm's sequential Bonferroni posthoc test, revealing that the method with the best performance (i.e., GBMA) performs as a control method. Notably, GBMA has yielded significantly better results than CGTR, HGO, GCACO, MFO, F-score, and CFC.
Furthermore, Friedman and Holm's sequential Bonferroni posthoc tests are applied for the NSF in Fig. 25. Figure

Friedman ranks based on NSF
28 exhibits Friedman ranks of the seven methods. The results show that GBMA has a minimum number of features, whereas CFC has a maximum NSF. The proposed method selects a lower number of features by 36% compared to CFC. This significant difference in selected features could play a vital role in the running time of these methods. The P value obtained for the test is 4.13E−08, which is less than the presumed significance level, i.e., α = 0.05. Thus, the NSF by all methods is significantly different. Obtaining the best rank, GBMA generally acts as a control method in Holm's sequential Bonferroni posthoc test. The results in Fig.

Holm test based on NSF
29 suggest that the proposed method is significantly better than all methods save for CGTR.
Rights and permissions
About this article

Cite this article
Javidi, M.M. Feature selection schema based on game theory and biology migration algorithm for regression problems. Int. J. Mach. Learn. & Cyber. 12, 303–342 (2021). https://doi.org/10.1007/s13042-020-01174-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-020-01174-8