
Abstract
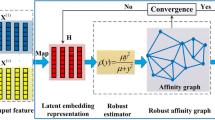
Multi-view clustering (MVC) can integrate the complementary information between different views to remarkably improve clustering performance. However, the existing methods suffer from the following drawbacks: (1) multi-view data are often lying on high-dimensional space and inevitably corrupted by noise and even outliers, which poses challenges for fully exploiting the intrinsic structure of views; (2) the non-convex objective functions prone to becoming stuck into bad local minima; and (3) the high-order structure information has been largely ignored, resulting in suboptimal solution. To alleviate these problems, this paper proposes a novel method, namely Self-paced Latent Embedding Space Learning (SLESL). Specifically, the views are projected into a latent embedding space to dimensional-reduce and clean the data, from simplicity to complexity in a self-paced manner. Meanwhile, multiple candidate graphs are learned in the latent space by using embedded self-expressiveness learning. After that, these graphs are stacked into a tensor to exploit the high-order structure information of views, such that a refined consensus affinity graph can be obtained for spectral clustering. The experimental results demonstrate the effectiveness of our proposed method.




Similar content being viewed by others


References
Mei Y, Ren Z, Wu B, Shao Y, Yang T (2022) Robust graph-based multi-view clustering in latent embedding space. Int J Mach Learn Cybernet 13(2):497–508
Li H, Ren Z, Mukherjee M, Huang Y, Sun Q, Li X and Chen L (2020) Robust energy preserving embedding for multi-view subspace clustering. Knowl-Based Syst 210:106489
Zhang C, Cui Y, Han Z, Tianyi Zhou J, Fu H and Hu Q (2022) Deep partial multi-view learning. IEEE Trans Pattern Anal Mach Intell 44(05):2402–2415
Liu X, Zhu X, Li M, Tang C, Zhu E, Yin J, Gao W (2019) Efficient and effective incomplete multi-view clustering. Proc AAAI Conf Artif Intell 33:4392–4399
Peng X, Huang Z, Lv J, Zhu H and Zhou JT (2019) Comic: multi-view clustering without parameter selection. Int Conf Mach Learn (97):5092–5101
Jiang Z, Bian Z, Wang S (2020) Multi-view local linear knn classification: theoretical and experimental studies on image classification. Int J Mach Learn Cybern 11(3):525–543
Yueyue H, Sun S, Xin X, Zhao J (2020) Attentive multi-view reinforcement learning. Int J Mach Learn Cybern 11(11):2461–2474
Zhan S, Sun W, Du C and Zhong W (2022) Diversity-promoting multi-view graph learning for semi-supervised classification. Int J Mach Learn Cybernet 12(10):2843–2857
Tang C, Zheng X, Liu X, Zhang W, Zhang J, Xiong J and Wang L (2021) Cross-view locality preserved diversity and consensus learning for multi-view unsupervised feature selection. IEEE Trans Knowl Data Eng
Ren Z, Sun Q, Bin W, Zhang X, Yan W (2019) Learning latent low-rank and sparse embedding for robust image feature extraction. IEEE Trans Image Process 29(1):2094–2107
He X, Niyogi P (2003) Locality preserving projections. Adv Neural Inf Process Syst 16:153–160
Yuwu L, Lai Z, Yong X, Li X, Zhang D, Yuan C (2015) Low-rank preserving projections. IEEE Trans Cybernet 46(8):1900–1913
Zhang C, Huazhu F, Qinghua H, Cao X, Xie Y, Tao D, Dong X (2018) Generalized latent multi-view subspace clustering. IEEE Trans Pattern Anal Mach Intell 42(1):86–99
Chen M, Huang L, Wang C-D and Huang D (2020) Multi-view clustering in latent embedding space. In AAAI, pp 3513–3520
Jing P, Yuting S, Li Z, Liu J, Nie L (2019) Low-rank regularized tensor discriminant representation for image set classification. Signal Process 156:62–70
Xie Y, Tao D, Zhang W, Liu Y, Zhang L, Yanyun Q (2018) On unifying multi-view self-representations for clustering by tensor multi-rank minimization. Int J Comput Vis 126(11):1157–1179
Jianlong W, Lin Z, Zha H (2019) Essential tensor learning for multi-view spectral clustering. IEEE Trans Image Process 28(12):5910–5922
Gao Q, Xia W, Wan Z, Xie D, Zhang P (2020) Tensor-svd based graph learning for multi-view subspace clustering. Proc AAAI Conf Artif Intell 34:3930–3937
Zhang C, Huazhu F, Wang J, Li W, Cao X, Qinghua H (2020) Tensorized multi-view subspace representation learning. Int J Comput Vis 128(8):2344–2361
Kilmer ME, Braman K, Hao N, Hoover RC (2013) Third-order tensors as operators on matrices: a theoretical and computational framework with applications in imaging. SIAM J Matrix Anal Appl 34(1):148–172
Ren Z, Sun Q and Wei D (2021) Multiple kernel clustering with kernel k-means coupled graph tensor. In: Thirty-Fifth AAAI Conference on Artificial Intelligence
Jiang L, Meng D, Zhao Q, Shan S, Hauptmann AG (2015) Self-paced curriculum learning. AAAI 2:6
Jiang L, Meng D, Shoou-I Yu, Lan Z, Shan S, Hauptmann A (2014) Self-paced learning with diversity. Adv Neural Inf Process Syst 27:2078–2086
Meng D, Zhao Q and Jiang L (2015) What objective does self-paced learning indeed optimize? arXiv preprint arXiv:1511.06049
Khan F, Mutlu B and Zhu J (2011) How do humans teach: on curriculum learning and teaching dimension. In: Advances in neural information processing systems, pp 1449–1457
Li J, Kang Z, Peng C and Chen W (2021) Self-paced two-dimensional pca. In: Thirty-Fifth AAAI Conference on Artificial Intelligence, pp 8392–8400
Huang Z, Ren Y, Liu W, Xiaorong P (2019) Self-paced multi-view clustering via a novel soft weighted regularizer. IEEE Access 7:168629–168636
Jianlong W, Xie X, Nie L, Lin Z, Zha H (2020) Unified graph and low-rank tensor learning for multi-view clustering. Proc AAAI Conf Artif Intell 34:6388–6395
Ren Z, Mukherjee M, Bennis M and Lloret J (2020) Multi-kernel clustering via non-negative matrix factorization tailored graph tensor over distributed networks. In: IEEE Journal on Selected Areas in Communications, pp 1946–1956
Canyi L, Feng J, Lin Z, Mei T, Yan S (2018) Subspace clustering by block diagonal representation. IEEE Trans Pattern Anal Mach Intell 41(2):487–501
Yin H, Wenjun H, Li F, Lou J (2021) One-step multi-view spectral clustering by learning common and specific nonnegative embeddings. Int J Mach Learn Cybern 12(7):2121–2134
Bengio Y, Louradour J, Collobert R and Weston J (2009) Curriculum learning. In: Proceedings of the 26th annual international conference on machine learning, pp 41–48
Zhou P, Du L, Liu X, Shen Y-D, Fan M and Li X (2020) Self-paced clustering ensemble. IEEE Trans Neural Netw Learn Syst 32(4):1497–1511
Li C, Wei F, Yan J, Zhang X, Liu Q, Zha H (2017) A self-paced regularization framework for multilabel learning. IEEE Trans Neural Netw Learn Syst 29(6):2660–2666
Boyd S, Parikh N, Chu E (2011) Distributed optimization and statistical learning via the alternating direction method of multipliers. Now Publishers Inc
Xiao S, Tan M, Xu D, Dong ZY (2015) Robust kernel low-rank representation. IEEE Trans Neural Netw Learn Syst 27(11):2268–2281
Burden RL (1993) Jd faires numerical analysis. PWS, Boston, pp 174–184
Zhou P, Lu C, Feng J, Lin Z and Yan S (2019) Tensor low-rank representation for data recovery and clustering. IEEE Trans Pattern Anal Mach Intell 43(5):1718–1732
Li X, Ren Z, Lei H, Huang Y, Sun Q (2021) Multiple kernel clustering with pure graph learning scheme. Neurocomputing 424:215–225
Ren Z, Sun Q and Wei D (2021) Multiple kernel clustering with kernel k-means coupled graph tensor learning. Proc AAAI Conf Artif Intell 35(11):9411–9418
Yan D, Huang L and Jordan MI (2009) Fast approximate spectral clustering. In: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pp 907–916
Liu G, Lin Z, Shuicheng Yan J, Sun YY, Ma Y (2012) Robust recovery of subspace structures by low-rank representation. IEEE Trans Pattern Anal Mach Intell 35(1):171–184
Gao H, Nie F, Li X and Huang H (2015) Multi-view subspace clustering. In: Proceedings of the IEEE international conference on computer vision, pp 4238–4246
Tang C, Liu X, Zhu X, Zhu E, Luo Z, Wang L, Gao W (2020) Cgd: multi-view clustering via cross-view graph diffusion. Proc AAAI Conf Artif Intell 34:5924–5931
Yang J, Yin W, Zhang Y, Wang Y (2009) A fast algorithm for edge-preserving variational multichannel image restoration. SIAM J Imag Sci 2(2):569–592
Burden R, Faires J, Burden A (2015) Numerical analysis[M]. Cengage Learn
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. 62106209), the Sichuan Science and Technology Program (Grant No. 2021YJ0083), the State Key Lab. Foundation for Novel Software Technology of Nanjing University (Grant No. KFKT2021B23), the Guangxi Natural Science Foundation (Grant No. 2020GXNSFAA297186), the Guangxi Science and Technology Major Project (Grant No. 2018AA32001), and the National Statistical Science Research Project (Grant No. 2020491).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Proof of Lemma 1
Proof
For convenience, we denote the objective of (18) as
where \(f({\mathbf {p}})=\left( {\mathbf {p}}^{\intercal } {\mathbf {S}}^{2} {\mathbf {p}}\right) ^{1 / 2}\) and \(\psi ({\mathbf {p}})=\tau / 2\Vert {\mathbf {p}}-{\mathbf {h}}\Vert ^{2}\).
Note that \(F({\mathbf {p}})\) is convex, and an optimum of (18) corresponds to a stationary point of \(F({\mathbf {p}})\). Therefore, to find the optimal solution of the problem in (18), we first derive the subgradient of \(F({\mathbf {p}})\), and then seek its stationary point [36].
Since \(F({\mathbf {p}})\) can be expressed as the sum of \(f({\mathbf {p}})\) and \(\psi ({\mathbf {p}})\), let us derive the subgradients of \(f({\mathbf {p}})\) and \(\psi ({\mathbf {p}})\), respectively. The subgradient of \(\psi ({\mathbf {p}})\) with respect to \({\mathbf {p}}\) is as follows:
For \(f({\mathbf {p}})\), note that it can be rewritten as \(f({\mathbf {p}})=\Vert \mathbf {S p}\Vert\). Based on [45], the subgradient of \(f({\mathbf {p}})\) with respect to \({\mathbf {p}}\) is as follows:
Recall that the diagonal matrix \({\mathbf {S}}\), in which all the diagonal elements are positive, is a positive definite matrix. As a result, \(\mathbf {S p}={\mathbf {0}}_{q}\) is equivalent to \({\mathbf {p}}={\mathbf {0}}_{q}\).
In summary, the subgradient of \(F({\mathbf {p}})\) can be expressed as
Based on the above two cases, let us discuss the stationary point of \(F({\mathbf {p}})\) accordingly in two cases as follows.
-
1.
When \({\mathbf {p}}={\mathbf {0}}_{q}\), we have
$$\begin{aligned} \partial F({\mathbf {p}})=\left\{ {\mathbf {S}}^{\intercal } {\mathbf {r}}+\tau ({\mathbf {p}}-{\mathbf {h}}) \mid \Vert {\mathbf {r}}\Vert \le 1\right\} \end{aligned}$$(37)Note that \({\mathbf {p}}^{*}={\mathbf {0}}_{q}\) is a stationary point, if and only if
$$\begin{aligned} {\mathbf {0}}_{q} \in \left\{ {\mathbf {S}}^{\intercal } {\mathbf {r}}+\tau \left( {\mathbf {p}}^{*}-{\mathbf {h}}\right) \mid \Vert {\mathbf {r}}\Vert \le 1\right\} \end{aligned}$$(38)In other words, \({\mathbf {p}}^{*}={\mathbf {0}}_{q}\) is a stationary point, if and only if there is a vector \({\mathbf {r}}\) that satisfies the following two conditions:
$$\begin{aligned} \begin{aligned}&{\mathbf {S}}^{\intercal } {\mathbf {r}}+\tau \left( {\mathbf {p}}^{*}-{\mathbf {h}}\right) ={\mathbf {0}}_{q} \\&\Vert {\mathbf {r}}\Vert \le 1 \end{aligned} \end{aligned}$$(39)Recalling that \({\mathbf {p}}^{*}={\mathbf {0}}_{q}\) and \({\mathbf {S}}\) is positive definite, (39) is equivalent to \({\mathbf {r}}=\tau {\mathbf {S}}^{-1} {\mathbf {h}}\). Combining this with inequality (39), we arrive at
$$\begin{aligned} \left\| {\mathbf {S}}^{-1} {\mathbf {h}}\right\| \le \frac{1}{\tau } \end{aligned}$$(40)Therefore, \({\mathbf {p}}^{*}={\mathbf {0}}_{q}\) is a stationary point of \(F({\mathbf {p}})\), if and only if \(\left\| {\mathbf {S}}^{-1} {\mathbf {h}}\right\| \le (1 / \tau )\). In particular, when \(\left\| {\mathbf {S}}^{-1} {\mathbf {h}}\right\| \le (1 / \tau )\), we have \({\mathbf {r}}=\tau {\mathbf {S}}^{-1} {\mathbf {h}}\) that satisfies (38).
-
2.
When \({\mathbf {p}} \ne {\mathbf {0}}_{q}\), we have
$$\begin{aligned} \partial F({\mathbf {p}})=\frac{{\mathbf {S}}^{2} {\mathbf {p}}}{\Vert \mathbf {S p}\Vert }+\tau ({\mathbf {p}}-{\mathbf {h}}) \end{aligned}$$(41)As a result, \({\mathbf {p}}^{*} \ne {\mathbf {0}}_{q}\) is a stationary point, if and only if \({\mathbf {S}}^{2} {\mathbf {p}}^{*} /\left\| \mathbf {S p}^{*}\right\| +\tau \left( {\mathbf {p}}^{*}-{\mathbf {h}}\right) ={\mathbf {0}}_{q}\). This condition can be rewritten as
$$\begin{aligned} \left( \frac{{\mathbf {S}}^{2}}{\left\| {\mathbf {S}} {\mathbf {p}}^{*}\right\| }+\tau {\mathbf {I}}\right) {\mathbf {p}}^{*}=\tau {\mathbf {h}} \end{aligned}$$(42)By defining a scalar \(\alpha \triangleq \left\| \mathbf {S p}^{*}\right\|\), we rewrite \({\mathbf {p}}^{*}\) as
$$\begin{aligned} {\mathbf {p}}^{*}=\left( \frac{{\mathbf {S}}^{2}}{\tau \alpha }+{\mathbf {I}}\right) ^{-1} {\mathbf {h}} \end{aligned}$$(43)Since \({\mathbf {p}}^{*} \ne {\mathbf {0}}_{q}\), we have \(\mathbf {S p}^{*} \ne {\mathbf {0}}_{q}\). Accordingly, we have \(\alpha =\left\| \mathbf {S p}^{*}\right\| >0\). Moreover, given \(\alpha =\left\| \mathbf {S p}^{*}\right\|\) and \(\alpha >0\), we conclude that \(\alpha\) is the positive root of
$$\begin{aligned} \alpha ^{2}=\left( {\mathbf {p}}^{*}\right) ^{\intercal } {\mathbf {S}}^{2} {\mathbf {p}}^{*} \end{aligned}$$(44)By substituting (43) into (44), we obtain
$$\begin{aligned} \alpha ^{2}=\tau ^{2} \alpha ^{2} {\mathbf {h}}^{\intercal } {\text {diag}}\left( \left\{ \frac{s_{i}^{2}}{\left( s_{i}^{2}+\tau \alpha \right) ^{2}}\right\} _{1 \le i \le q}\right) {\mathbf {h}} \end{aligned}$$(45)Dividing both the sides of (45) by \(\tau ^{2} \alpha ^{2}\), we arrive at (20).
Now, if the positive root of the equation in (20) exists, we can first obtain \(\alpha\), and then obtain \({\mathbf {p}}^{*}\) by substituting \(\alpha\) into (43). In the following, we show the existence condition of the positive root of (20).
For convenience, we define the following function with respect to \(\alpha\):
With this definition, (20) can be rewritten as \(\ell (\alpha )=0\). We can verify the following properties of \(\ell (\alpha )\).
Based on (46) and the intermediate value theorem [46], it is easy to verify that there exists a positive scalar \(\alpha\) which satisfies \(\ell (\alpha )=0\) if and only if \(\Vert {\mathbf {S}}^{-1} {\mathbf {h}}\Vert ^{2}-(1 / \tau ^{2})>0\), namely
In particular, when \(\Vert {\mathbf {S}}^{-1} {\mathbf {h}}\Vert >1 / \tau\), the positive root of the equation \(\ell (\alpha )=0\) exists, and such positive root is unique due to the strictly decreasing property of \(\ell (\alpha )\). Furthermore, let \(\alpha ^{*}\) be the unique positive root of \(\ell (\alpha )=0\), then we can prove the following inequality that determines the range of \(\alpha ^{*}\):
in which \(\alpha _{u}=({\mathbf {h}}^{\intercal } {\text {diag}}(\{s_{i}^{2}\}_{1 \le i \le q}) {\mathbf {h}})^{1 / 2}-s_{q}^{2} / \tau\) is the positive root of an equation \(f_{u}(\alpha )=0; \alpha _{l}=({\mathbf {h}}^{\intercal } {\text {diag}}(\{s_{i}^{2}\}_{1 \le i \le q}) {\mathbf {h}})^{1 / 2}-\) \(s_{1}^{2} / \tau\) is the larger root of another equation \(f_{l}(\alpha )=0\), where the two functions \(f_{u}(\alpha )\) and \(f_{l}(\alpha )\) are defined as
In particular, \(f_{u}(\alpha )\) is obtained by the amplification of \(\ell (\alpha )\) by replacing \((\tau \alpha +s_{i}^{2})\) with \((\tau \alpha +s_{q}^{2})\), while \(f_{l}(\alpha )\) is obtained by the minification of \(\ell (\alpha )\) by replacing \((\tau \alpha +s_{i}^{2})\) with \((\tau \alpha +s_{l}^{2})\).
Therefore, \(f_{u}(\alpha )=0\) has a unique positive root, namely \(\alpha _{u}\), which is no less than \(\alpha ^{*}\). Moreover, \(\alpha _{l}\) [i.e., the larger root of \(f_{l}(\alpha )=0\) ] is no greater than \(\alpha ^{*}\), but not necessarily positive. As a result, the inequalities in (48) are verified. Accordingly, we can obtain \(\alpha ^{*}\) by the bisection search method [41] within the searching range \([\max (0, \alpha _{l}), \alpha _{u}]\).
In summary, if and only if \(\Vert {\mathbf {S}}^{-1} {\mathbf {h}}\Vert >(1 / \tau )\) is satisfied, there exists \({\mathbf {p}}^{*} \ne {\mathbf {0}}_{q}\), which is optimal to the problem in (20). In particular, when \(\Vert {\mathbf {S}}^{-1} {\mathbf {h}}\Vert >(1 / \tau ), {\mathbf {p}}^{*}\) can be calculated as in (43), where \(\alpha\) is the unique positive root of the equation in (20) and can be obtained by the bisection search method [41].
This completes the proof of Lemma 1. \(\square\)
Rights and permissions
About this article

Cite this article
Li, H., Ren, Z., Zhao, C. et al. Self-paced latent embedding space learning for multi-view clustering. Int. J. Mach. Learn. & Cyber. 13, 3373–3386 (2022). https://doi.org/10.1007/s13042-022-01600-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-022-01600-z