
Abstract
Educators need actionable information about student progress during the school year. This paper explores an approach to this problem in the writing domain that combines three measurement approaches intended for use in interim-assessment fashion: scenario-based assessments (SBAs), to simulate authentic classroom tasks, automated writing evaluation (AWE) features to track changes in performance and writing process traits derived from a keystroke log. Our primary goal is to determine if SBAs designed to measure English Language Arts skills, supplemented by richer measurement of the writing task, function well as interim assessments that are sensitive to differences in performance related to differences in quality of instruction. We calibrated these measures psychometrically using data from a prior study and then applied them to evaluate changes in performance in one suburban and two urban middle schools that taught argument writing. Of the three schools, only School A (the suburban school, with the strongest overall performance) showed significant score increases on an essay task, accompanied by distinctive patterns of improvement. A general, unconditioned growth pattern was also evident. These results demonstrate an approach that can provide richer, more actionable information about student status and changes in student performance over the course of the school year.
Similar content being viewed by others


Introduction
Effective instruction incorporates assessment. Teachers need to know what their students know, their status with respect to current teaching goals, and what they need to learn. Students use feedback from assessment to consolidate and clarify what they have learned and set learning goals. Immediate feedback closely integrated with classroom practice is more likely to have beneficial effects on learning (Black and Wiliam 1998). Conversely, when high-stakes assessments are disconnected from classroom practice, there is a risk of negative washback (Au 2007), that is, a tendency for teachers to “teach to the test” rather than focusing on providing the best possible subject matter instruction.
An alternative to traditional summative assessment is provided by scenario-based assessments (SBAs)—standardized assessments designed to simulate classroom tasks, embedded in a project-like scenario (Deane et al. 2011a; Deane and Song 2014; Sabatini et al. 2014; Sheehan et al. 2014). Much of this work was done as part of the research initiative, “Cognitively-Based Assessment of, for, and as Learning” (or CBAL), which focused upon designing an integrated assessment system to have positive effects on teaching and learning (Bennett 2010; Bennett and Gitomer 2009). In particular, we have developed SBAs designed to assess the ability to read, analyze, and produce written arguments (Deane et al. 2011b; Deane and Song 2014; Bennett et al. 2016). These SBAs require students to complete tasks modeled on classroom exercises. All tasks address the same topic and build toward a culminating writing task. Previous studies indicate that these assessments can assess performance level on an argumentation learning progression (van Rijn et al. 2014), and that item difficulty closely aligns with learning progression levels (Deane et al. 2018b).
The design structure of SBAs may provide useful task level information. For example, if a school taught summary-writing effectively, group means on summary tasks might increase relative to other test sections. Similarly, if a school taught argument analysis or essay writing effectively, those task means might increase instead. Since the component tasks model activities critical for success in argument writing, SBA task performance patterns may help to evaluate instructional effectiveness and plan interventions.
Automated writing trait features may provide other formative indicators. Scores on complex performance tasks, such as essays, reflect multiple skills, and for interim and formative purposes, schools and teachers need more information than is provided by holistic scores alone. Two indicator types may be useful. Automated writing evaluation (AWE) systems identify such writing traits as organization and development, expressive vocabulary, and adherence to conventions (Attali and Powers 2009). In addition, keystroke log analysis captures key details of the writing process (Deane and Quinlan 2010; Deane et al. 2011c; Quinlan et al. 2009; Van Waes et al. 2012). Measurable constructs include overall effort, the extent of planning or editing, and transcription fluency (Deane and Zhang 2015; Zhang and Deane 2015; Zhang et al. 2019a; Zhang et al. 2016). These constructs are directly relevant to educators’ decisions about curriculum design, lesson planning, instruction, and feedback.
This paper specifically addresses the usefulness of CBAL SBAs for interim and diagnostic purposes, particularly when supplemented by automated writing trait indicators. To achieve this goal, several logical requirements must be satisfied. First, we must determine whether the assessment measures the intended construct precisely enough to identify student performance changes. Second, we must examine whether the assessment can detect differences in learning outcomes. Third, we must demonstrate whether the assessment provides meaningful, potentially actionable descriptions of group differences associated with these outcomes. We will address these research questions:
-
RQ1. What is the technical quality of CBAL SBAs of written argumentation when they are used as interim assessments?
-
RQ2. How do the study schools differ, both quantitatively, in terms of their performance on end-of-year state ELA tests, and qualitatively, in terms of curriculum and formative assessment practices?
-
RQ3. Are the CBAL SBAs used in interim fashion sensitive enough to detect changes in performance induced by instruction partway through the school year? What patterns of growth do schools show on total scores and task scores on CBAL SBAs, and how do these patterns relate to changes in external measures such as grades and end-of-year assessments?
-
RQ4. Can we use AWE and writing process trait indicators to identify which aspects of student essay writing performance may have been significantly affected by instruction?
Method
Participants
During the 2017–2018 school year, 844 students participated in the study. These were 7th-grade students attending one suburban and two urban middle schools in a mid-Atlantic U.S. state. There were 224 students in 9 class sections at School A, 362 students in 14 class sections at School B, and 258 students in 11 class section at School C. Individual socioeconomic status was not available, but 41% of students at School A, 63% at School B, and 71% at School C qualified for free or reduced-price lunch. All three schools were majority-minority (more than 60% African American or Hispanic). In the 7th-grade population recruited for this study, School A had a lower proportion of White students and a higher proportion of English language learners (ELLs) and special education students. School B had the lowest proportion of African-American students, while School C was majority African-American. Specifically, students at School A were 46% African American, 28% Hispanic, 19% White, 4% Hawaiian/Pacific Islander, 1% Asian, and 5% mixed ethnicity. 6% were ELLs, and 18% in special education. Students at School B were 32% African American, 30% White, 22% Hispanic, 2% Asian, and 3% mixed ethnicity. 1% were ELLs, and 6% were special education students. Students at School C were 53% African American, 29% White, 9% Hispanic, 5% Asian, 1% Native American, and 3% mixed race. 2% were ELLs, and 4% in special education.
Instruments
The primary study instruments were two scenario-based assessments of written argumentation, parallel item-by-item in structure, addressing different topics. The first, referred to hereafter as “Ban Ads,” required students to address the topic, “Should the U.S. ban advertising to children under 12?”. The second, hereafter “Cash for Grades,” required students to address the topic, “Should schools pay students cash for getting good grades?” Both assessments consisted of 20 items (16 selected-response items, 3 short answer items, and an essay task), designed to measure students’ ability to read, summarize, analyze, and critique other people’s arguments, then formulate arguments of their own. This design is presented elsewhere (Deane et al. 2011a; Deane and Song 2014; Deane et al. 2018a; Zhang et al. 2019b), so is only briefly summarized here. The assessment contains four tasks:
-
Task 1: Evaluate the quality of written summaries. In this task, they must read an article that presents arguments for and against a policy proposal. Next, they read summaries of this article that vary in quality and are asked to evaluate each summary by answering nine multiple-choice questions that require them to apply specific standards for summary quality
-
Task 2: Complete source-based short-answer writing tasks. Students are required to summarize two articles about the targeted issue, using the summary evaluation standards to guide their writing, and then to critique someone else’s argument. In the critique task, they are presented with a letter to the editor that contains several flawed arguments and are required to identify and explain at least two such flaws
-
Task 3: Analyze arguments drawn from the source texts. First, they are asked to classify ten sentence-length arguments by arranging them in a pro/con T-chart. To perform well on this item, students must infer whether arguments are being offered to support or oppose a specific policy proposal. Second, they are asked to analyze arguments. Six multiple-choice questions are administered. Each question presents an argument and a piece of evidence and asks students to determine whether the evidence strengthens the argument, weakens the argument, or does neither
-
Task 4: Write an argument essay. Students are expected to take a position on the issue and support it with appropriate arguments and evidence. They are free to use the articles and information presented in earlier tasks
Previous studies have shown that the progression of item difficulties is consistent with the intended design (Deane et al. 2018b; van Rijn et al. 2014). Total scores on these assessments correlate at about .75 when they are administered less than a month apart (van Rijn et al. 2014). Reasonable relations to state reading and writing test scores have been observed, ranging between .58 and .60 for state reading tests, .56 and .60 for state writing tests (Bennett 2011; Fu and Wise 2012), and .53 for teacher ratings of writing ability (Zhang et al. 2017).
Several closely aligned formative assessment tasks on the issue, “Should junk food be sold in school?” were also made available to participating schools (Deane et al. 2018b). This formative task set included formative versions of the task designs also deployed in Ban Ads and Cash for Grades. The Junk Food task set was not designed to function as an independent curriculum but was included to enable teachers to supplement their existing curriculum to align it more closely with the construct focus of the tests.
Other criterion measures included prior-year course grades and the Smarter Balanced Assessment Consortium’s English Language Arts (ELA) Assessment. This Common-Core-aligned assessment includes items designed to assess reading, writing, research, and speaking/listening skills. It has demonstrated strong evidence of validity, with an overall reliability of .92 for the 7th grade form (Smarter Balanced Assessment Consortium 2018b).
Design
A pre/post design was used. The goal was to determine whether the SBAs used in this study were sensitive to naturally-occurring school differences in the quality and effects of instruction. The following information was collected:
End-of-Year State ELA Test Scores
Scale scores were obtained for the 2017 and 2018 Smarter Balanced ELA assessments (Smarter Balanced Assessment Consortium 2017). For comparison purposes, 6th- and 7th-grade Smarter Balanced scale scores were also obtained for students who attended the same schools in successive administrations between 2015 and 2018.
Demographic Information
Demographic data collected included gender, race/ethnicity, ELL status, and special education status.
Scores on the Ban Ads (Pretest) and Cash for Grades (Posttest) Assessments
Selected-response items were machine scored. Constructed-response (CR) items were scored by professional raters using previously validated rubrics. 40% of responses were double-scored. For the summary constructed-response (CR) tasks, a three-point rubric was used, focusing on whether students had included only the most important points, explained source material accurately without plagiarism, and avoided inserting personal opinions. For the critique CR tasks, a four-point rubric was used, focusing on whether students identified at least two flawed arguments and clearly explained each flaw without task-irrelevant content. For the essay CR task, two five-point rubrics were applied by different groups of raters. One focused on general writing skill, including organization and development, coherence, word choice, and conventions. The other focused on the rhetorical quality of arguments (command of argument structure, argument quality and development, and audience awareness). These rubrics were published in previous reports (Zhang et al. 2019a; Deane et al. 2013; Song et al. 2017; Deane 2014b). Since the teachers planned to use assessment results in their instruction, all students received the Ban Ads assessment in the pretest administration, and the Cash for Grades assessment in the posttest administration. Since different forms were administered at pre- and posttest, scores were equated using data from a study documented by Fu et al. (2013) and van Rijn et al. (2014), in which a large group of students took both forms.
AWE Features Extracted from Student Essays
Two natural language processing (NLP) engines were deployed: e-rater (Attali and Burstein 2006; Burstein et al. 2013), an automated scoring engine, and Text Evaluator (Sheehan 2016; Sheehan et al. 2014), a system designed to assess text complexity and genre traits. The e-rater engine captures several dimensions relevant to essay quality (Deane 2011, 2013), including organization, development, discourse coherence, syntactic variety, vocabulary difficulty, grammaticality and idiomaticity of language, and the presence of errors in conventions (Quinlan et al. 2009). The Text Evaluator engine provides measurement of dimensions of text variation, including vocabulary difficulty, academic language, concreteness, syntactic complexity, and markers of oral, narrative, and argumentative style. Other NLP text analysis systems capture similar dimensions, including Coh-Metrix (Graesser et al. 2011; McNamara and Graesser 2012).
Writing Process Features Based on Keystroke Log Data
Keystroke logs record when and where a text changed during the writing process. From keystroke logs, summary features can be calculated, including typing speed (length of bursts of fast text production in characters and duration of pauses between and within words), effort (number of keystrokes produced and total writing time), pauses for sentence-level planning (length of pauses before and after periods and other punctuation marks), and editing behaviors (how often a writer jumps to make changes at a different location in the text, how long they pause before jumps, and how far they move with each jump). These features were drawn from a larger collection of features developed in prior research (Almond et al. 2012; Deane and Zhang 2015).
Procedure
Planning
The project began with a summer orientation meeting attended by district teachers and administrators. Teachers (n = 10) were familiarized with the assessment design and associated formative tasks and were given the opportunity to plan how to integrate these tasks with their existing curriculum. All schools committed to an overall procedure, which included a pretest administration, a review of pretest results prior to instruction in written argument, and a posttest administration.
During the orientation meeting, possible use cases were presented for CBAL formative tasks (before instruction, as activities to launch instruction, as models or scaffolds during instruction, or as checks on understanding during instruction). Teachers worked in grade-level teams by school to plan which CBAL formative assessment tasks they would use and how they would use them. Each school made independent decisions on these issues, though we recommended the tasks be used formatively to help teachers identify which summary and argument skills needed additional instructional support.
Afterward, a research team member met with school teams to schedule classroom observations and discuss instructional plans. School A indicated they already had well-developed summary and argument writing units. They decided to use selected CBAL formative tasks primarily as checks for understanding. That is, they planned to administer CBAL formative tasks after lessons addressing concepts they assessed to determine needs for additional instruction. School B indicated that, since they lacked a well-developed summary and argument writing curriculum, they would build writing units around CBAL formative tasks. They decided to launch instruction by administering selected CBAL formative tasks, after which they would answer student questions and probe for understanding. School C indicated they intended to modify their existing argument writing unit to include selected CBAL formative tasks. They intended to use some tasks to launch instruction and others to check for understanding.
Pretest and Review of Pretest Results
In October 2017, all three schools administered Ban Ads online using school computer labs. Two months later, the research team met jointly with the three school teams, provided detailed data about pretest performance, and led discussions to help them understand the results so that they could take them into account during instruction.
Instruction and Classroom Observations
Between December 2017 and February 2018, each school implemented its planned argument writing unit. As part of this instruction, School B had students complete several CBAL Junk Food formative tasks online in the school computer lab, including the Junk Food essay task. The other two schools integrated Junk Food tasks into classroom lessons, either in printed form, or by presenting them on a laptop or smartboard. Instead of using the Junk Food essay task, they assigned topics from their existing writing curriculum, using a classroom digital writing tool, PEG Writing (now called MI Write), which provides automated scoring and feedback (Page 2003; Shermis et al. 2001; Wilson and Roscoe 2020).
During instruction, we conducted classroom observations. Data from these observations were collected using field notes. To ensure that field notes were reliably and accurately recorded, a research assistant was trained using the following procedure. First, the assistant watched a video of literacy instruction and recorded field notes using a two-column field-note protocol. The first column, titled “Observations,” was devoted to recording, as objectively as possible, teachers’ and students’ actions (behavioral or verbal) during the lesson. The second column, titled “Impressions,” was devoted to recording the research assistant’s impressions of the lesson, which included non-objective observations such as the degree to which teachers seemed to be conducting lessons effectively or whether students seemed to be learning or struggling. After recording field notes from the video, the research assistant received feedback to ensure that key pedagogical actions, student actions, and behaviors were correctly observed and recorded, and that impressions and reactions to those actions were also appropriately recorded. The research assistant engaged in two rounds of practice and feedback with a senior research team member before training was complete and the assistant deemed qualified to conduct in-school observations. After completing training, the research assistant observed 27 lessons across participating teachers’ classrooms. The research assistant was instructed to record notes related to (a) the way CBAL activities were utilized during the lesson both by the teacher and the students, (b) pedagogical actions by the teacher (e.g., providing instruction, asking and responding to questions, etc.), and (c) actions and reactions of students to CBAL materials and teacher instruction. This yielded 27 sets of field notes that were subjected to qualitative data analysis.
Posttest and End of Study Debriefing
In late February and early March 2018, each school administered Cash for Grades online using school computer labs. In May 2018, the research team met with the school teams and district administrators to review posttest results and obtain feedback.
Data Analysis
Research Question 1: Evidence of Technical Quality
We assessed technical quality by examining: (1) Inter-rater reliabilities for human-scored items (quadratic weighted kappasFootnote 1 and Pearson correlations); (2) model fit for a single-dimension IRT model trained using software described by Haberman (2013), providing equated scale scores and task subscores; (3) test/retest reliability (Pearson correlations between pretest and posttest scale scores), and (4) association with external measures (Pearson correlation of pretest and posttest scores with prior year course grades and scale scores on the 2017 and 2018 Smarter Balanced ELA assessments).
Research Question 2: Evidence of Differences among the Study Schools
To evaluate school differences, the following analyses were conducted:
Quantitative Analysis
Much of the longitudinal data examined in this paper does not meet the statistical requirements for a standard repeated-measures analysis of variance, so we applied a more general, nonparametric method here and elsewhere in the paper. Specifically, we used Generalized Estimating Equations (GEE), an appropriate general method for modeling growth effects at a group level (Lipsitz and Fitzmaurice 2008). Generalized estimating equations are a semiparametric regression method that uses a generalized linear model to provide reliable estimates of means and mean differences between groups. Instead of modeling within-subject covariance structure, a GEE model assumes that individuals fall into meaningful clusters and focuses on estimating parameters for the categories specified by the model. Because GEEs maximize normality-based loglikelihood without assuming normally distributed responses or homogeneity of variance, they provide robust estimation of group means and are appropriate for data with skewed distributions such as often occurs with response time data (Hardin and Hilbe 2003). For this analysis, we obtained 6th and 7th grade Smarter Balanced ELA scale scores for all three schools between 2015 and 2018. We then analyzed school growth patterns. Specifically, we used GEE to examine effects on score of school, time of administration, and the interactions between school and time of administration for students attending the same school in successive years.
Qualitative Analysis
The field note analysis deployed open and axial coding (Corbin and Strauss 2008) conducted by a senior research team member (Dr. Wilson) and two research assistants. In that coding, the field notes were randomly separated into a training set (1/3 sample) and test set (2/3 sample). The training set (n = 9) was reviewed by this team and codes generated to characterize the different observations and impressions (i.e., open coding). The team then met to analyze, condense, and organize the codes into categories and subcategories (i.e., axial coding). The code book included a total of six parent categories and 34 sub-categories (see Appendix 1).
The parent categories were (1) Level of curricular integration of CBAL formative assessment tasks – this category referred to whether CBAL materials were used as the main or supplemental instructional material or unused during that lesson; (2) Form of CBAL/lesson integration – whether CBAL materials were presented using computers, print materials, or both media; (3) Level of interaction/scaffolding – the form of instruction teachers utilized, encompassing different aspects of teacher-led and student-led pedagogy; (4) Student factors – student-centered factors that may have affected their ability to learn from the materials (e.g., engagement, attitude toward task, familiarity with computers and content, and students’ ability levels); (5) Classroom factors – the degree to which classroom management affected teaching and learning with CBAL materials, and (6) Technical issues – the degree to which technical issues with CBAL materials (e.g., login issues) or school computing and internet resources affected the lesson.
After the codebook was fully developed the field notes in the training set were recoded to assess codebook feasibility and assess inter-rater reliability. The unit of analysis was a single line of notes within a set of field notes; multiple codes could be applied to that unit of analysis. Training continued until both research assistants reached a minimum inter-rater agreement level of 80%. Once that criterion was met, the research assistants used the finalized codebook to independently code the field notes in the test set (n = 18). The final agreement percentage between the two coders was 80.32%. All disagreements were resolved by consensus between the two raters.
Research Question 3: School Differences as Measured by CBAL Scale Scores and Task Subscores
To evaluate the sensitivity of CBAL SBAs to short-term growth, we analyzed pre−/post- differences between scale scores on Ban Ads and Cash for Grades. Scale scores were calculated using an IRT model calibrated using data from a 2013 study in which both assessments were given to the same students (Deane et al. 2018b; van Rijn et al. 2014). This resulted in equated scores that could be interpreted longitudinally. Specifically,
-
we applied GEE to detect longitudinal differences between schools on the CBAL assessments, controlling for demographic variables like gender, race, language proficiency, and special education status.
-
we calculated Pearson correlations between Smarter Balanced gain scores (Spring 2018 scale score - Spring 2017 scale score) and interim CBAL gain scores (Cash for Grades scale score – Ban Ads scale score).
We reasoned that if CBAL SBA scale scores were sensitive to short-term growth, they would reflect school differences (possibly related to differences observed on the Smarter Balanced assessment) and would directly account for at least some of the year-to-year growth in Smarter Balanced scores.
To evaluate whether student growth patterns differed across CBAL SBA component tasks, several analyses were conducted. First, task-level scores were calculated using the previously calibrated IRT model. Essentially, item parameters from individual tasks were used to induce task-level ability estimates on pretest and posttest. A summary evaluation task score was calculated for the 9 selected-response summary items, an argument analysis task score for the 7 selected-response argument analysis items, and a short answer task score for the two summary writing items and a critique writing item. Finally, we calculated an essay task score. Growth analysis was conducted using GEE to determine effects of school, time, school by time and demographic variables on task score. We also examined the extent to which task-level gain scores correlated with Smarter Balanced gain scores.
Research Question 4: Sensitivity to School Differences in AWE and Writing Process Traits
To address research question 4, we designed automated metrics to capture specific writing traits, building upon previous factor analyses for product and process data (Attali and Powers 2009; Deane et al. 2019; Deane and Zhang 2015; Zhang and Deane 2015). The way each of these features was implemented is outlined below, first for AWE features, then for writing process features.
AWE Features
The e-rater engine supports three major traits: elaboration, expressive vocabulary, and adherence to conventions (Attali and Powers 2009). Some Text Evaluator factor scores load on the same traits. When these features were included, the following trait definitions resulted:
Elaboration
The following AWE features focus on the difference between texts with richly articulated internal structure and texts that are less structured (or undeveloped):
The organization feature is automatically calculated as follows (Burstein et al. 2003). First, a rhetorical structure theory (RST) parser (Marcu 2000) is used to analyze the student essay. The RST parser divides the text into minimal clause-like units and identifies discourse markers that mark specific rhetorical relationships, such as “which” as a mark of elaboration, “although” as a mark of concession, or “if” as a mark of conditional relationships. The parser uses its database of discourse markers to assign rhetorical relationships to clause pairs. These may be either coordinate (in which case the two units are treated as equally important) or subordinating (in which case one part is treated as more important than the other). When multiple assignments are possible, the parser chooses the most likely relationship, based upon data from a corpus of manually labeled texts, with a preference for right-branching structures. The end result of the RST parse is a hierarchical structure that organizes the information in terms of the discourse relations the parser has identified. This information is supplemented by additional features identifying (1) where information is in the essay, (2) lexical and syntactic properties of the text, such as argument language (“I”, “might”, “should”, “agree”, “opinion”, and (3) the presence of specific syntactic structures, such as relative clauses and infinitives.
This information is used to identify whether students have produced and elaborated upon all the expected elements of an essay (introduction, thesis, multiple body paragraphs with topic sentences and content developing each topic, and a conclusion). Three different algorithms are applied, and their outputs are combined using a voting algorithm to determine the role each sentence plays in the essay. The baseline model is a simple algorithm based on sentence position within paragraphs, which assumes that an essay introduction begins at the start of the first paragraph, that the thesis is at the end of the first paragraph, that topic sentences appear at the beginnings of body paragraphs, and the conclusion appears in the final paragraph. The other two models apply a classifier trained on human-annotated data. One model applies a decision tree algorithm (C5.0), and the other uses a probabilistic finite state transducer. The resulting classification of the sentences in the essay is summarized by taking the log of the number of essay elements identified.
The syntactic variety feature is automatically calculated as follows. First, more than fifty specific grammatical and lexical categories are identified and labeled using features derived from the TextEvaluator engine (Deane et al. 2006; Sheehan et al. 2014; Sheehan and O'Reilly 2011). The list of elements identified includes base parts of speech (nouns, verbs, attributive and predicate adjectives, adverbs, and prepositions), morphological forms (present and past tense; perfects, infinitives, and passives), major punctuation marks (question marks, exclamation marks, and quotes), types of pronouns (1st, 2nd, 3rd person, possessives, reflexives, and wh-words), types of articles (definite or indefinite), types of conjunctions, conjunctive adverbs, and subordinators (marking such functions as coordination, contrast, causation, emphasis, conditionality, concession, or emphasis), types of nouns (such as abstract nouns, nominalizations, and cognitive process nouns), types of verbs (such as mental state verb and verbs of speaking), and types of adjectives and adverbs (relational adjectives, topical adjectives, and temporal and spatial adverbs). The relative frequencies of categories are then calculated and placed on a log scale. Finally, a linear regression model is trained using human essay scores across several dozen essay prompts as the criterion variable to produce a weight for each component feature. The sum of these weights applied to the log occurrence rate of each category reflects the extent to which the writer has used a variety of syntactic elements in ways that reflect the behavior of stronger writers (Deane 2011).
The discourse coherence feature is automatically calculated as follows (Somasundaran et al. 2014). First, lexical chains are identified in the student essay, where lexical chains are defined in terms of the following relationships: repetitions of the same word (extra-strong relations), repetitions involving the use of a synonym (strong relations) and repetitions involving weaker (“medium-strong”) semantic relations, as measured by setting thresholds for similarity as measured by an existing corpus-based thesaurus of word similarity relationships (Lin 1998). Words are linked into chains by searching the text for strong and extra-strong relations within 6 sentences, or for medium-strong relationships within two sentences. The underlying idea is that coherent text tends to organize its content into coherent sets, so that related words tend to appear closely together. The lexical chains that have been identified in an essay are used to create a series of summary features, including the total number of chains in the essay, the average chain length, and the number (and percentage) of long chains (i.e., chains of four or more words). This information is supplemented by searching the student essay for discourse function words belonging to various categories (markers of argument structure or summarization, contrast, concession, conditional relationships, and so forth). Each lexical chain is classified by the type of discourse function marker(s) associated with it, and a second set of features are generated, measuring the number of chains that (1) start after a particular type of discourse marker, (2) end before a particular type of discourse marker, of (3) continue past a particular type of discourse marker. The resulting set of features provides a description of the essay in terms of the extent to which the content is grouped into chains of related content words that are, in turn, organized rhetorically. A gradient boosting regressor was trained to use these features to predict human essay quality ratings for a corpus of student essays. These essays were designed to sample several genres (persuasive and expository essays, written critiques, summaries, and narratives) for a population that included undergraduate students, graduate students, and candidates for professional licensure.
The lexical tightness feature is automatically calculated using a database of word associations (Pointwise mutual information, or PMI) derived from a large text corpus. Pointwise mutual information is calculated as a function of the probability of two words cooccurring together (P(a,b) or separately (P(a), P(b), using the formula \( PMI\left(a,b\right)=\log \left(\frac{P\left(a,b\right)}{P(a)P(b)}\right) \). It provides an estimate of the degree of association between two words, which is likely to reflect topical connections. That is, words used to describe the same topics are far more likely to be used together than random pairs of words. The PMI estimates were generated from a corpus of about 2-billion word tokens drawn from the Gigaword corpus of newspaper texts (Graff and Cieri 2003), with an additional 500-million word tokens drawn from an in-house corpus containing texts from the genres of fiction and popular science. Given this concept of word association, lexical tightness can be defined as the mean PMI value for all pairs of content words in a text. Generally, lexical tightness is greater in simple texts with highly cohesive vocabulary (i.e., where most words are interrelated). When texts become more complex (by genre, topic, grade level), the average value of LT per text decreases (Flor et al. 2013; Flor and Beigman Klebanov 2014). The relation to essay quality is more complex. The direction of the correlation between PMI and essay score shifts for word pairs at different levels of association (Beigman Klebanov and Flor 2013). However, in middle school data from an earlier study, lexical tightness loaded positively on the elaboration factor presented here and has moderate and significant positive correlations with essay score (Deane et al. 2019), possibly due to the acquisition of rarer, topic-specific vocabulary by middle school students.
Expressive Vocabulary
The following AWE features are associated with expressive vocabulary difficulty. First, we used two simple word difficulty metrics commonly used in AWE engines (cf. Attali and Burstein 2006): word length (the mean square root of number of characters in the words in an essay, and word (in)frequency (the mean negative square root of word frequency in a large text corpus (the Google Books corpus, cf. Michel et al. 2011). For both features, the square root transformation makes the feature more appropriate for use in linear regression models, typically used in AWE applications. Two other features require more extensive discussion: the vocabulary richness and academic language features.
The vocabulary richness feature is automatically calculated by a linear regression model trained on human-scored student essay data. Several component features were used to build this model, including: (a) the frequency of words in the Google books corpus; (b) the frequency of words in a set of grade-level-classified essays written by students who used ETS’ digital online writing tool, Criterion™; (c) a measure of academic status, operationalized as the likelihood that words would appear more frequently in high school Criterion essays than in Criterion essays written by students in earlier grades; (d) the proportion of the words in student essays that were real English words, as measured by their presence in an in-house spelling lexicon; (e) the strength of association between the component words in a phrase, measured using the Rank Ratio statistic originated by Deane (2005). The rank ratio statistic is, like Pointwise Mutual Information, an association metric, designed to exploit Zipf’s law (Zipf 1935), who found a power law relationship between word frequency and rank in word frequency distributions, such that words tend to have frequencies inversely proportional to their rank. The mutual rank ratio statistic is calculated by comparing the rank of the word in a general word frequency dictionary with its rank in the frequency list of words that appear in a specific phrasal context. For example, words like grabbed, took, or held have much higher ranks in the frequency distribution for the context “__ him by” than they do in a general word frequency distribution, resulting in a high rank ratio for these words in that context. If we take the rank ratio for each word in a phrase, using the rest of the phrase as context, and take the log of the geometric mean of the resulting values, the result is a mutual rank ratio statistic that measures the extent to which phrases function as fixed, predictable units.
The predictive model underlying the vocabulary richness feature is based upon the hypothesis that not all combinations of word frequency, word length, and association with local context are equally valuable if they appear frequently in a writer’s prose (Deane 2014a). To take a fairly simple example, it may be a good thing generally to use rarer, more specific words; but an overabundance of rare words that do not fit well with the surrounding context is likely to be very difficult to understand. To capture this insight, several component models were built, trained on human-scored essay data. In one model, the two- and three-word phrases in a student essay were assigned to bins (high/mid/low) based upon the Google Books frequency of the phrase and the strength of the mutual rank ratio association between the words in the phrase, and a linear regression model was trained to predict essay score based upon the relative frequency of different bins. In a second model, the two- and three-word phrases in a student essay were assigned to bins (high/mid/low) based upon the Google Books frequency of the rarest word in the phrase and the strength of the mutual rank ratio association between the phrase’s component words, and once again, used to train a linear regression model against human essay scores. In a third model, words were classified into bins (top/high/mid/low) based upon Google Books frequency and length in characters, and a linear regression model trained to predict human scores on a corpus of student essays. In a fourth model, words were classified into bins (high/mid/low) depending on frequency in the Criterion high school essay corpus and academic status as determined by their preferential use in higher-grade-level student essays. Finally, the resulting predictions were treated as predictors, and combined with the base features to predict essay score on a different training set. The predicted scores outputted by this model, when used as a predictive feature in an e-rater scoring model, captured a significantly larger proportion of variance than the baseline vocabulary features, frequency and length.
The academic language feature is a factor score reported by the TextEvaluator engine (Sheehan et al. 2014). It is derived from several features with strong positive loadings on this factor, such as presence of words on the Academic Word List (Coxhead 2000), the frequency of nominalizations, and the frequency of words on lists developed by Biber and his colleagues (e.g., academic verbs, abstract nouns, topical adjectives, and cognitive process nouns), see Biber 1986, 1988, and Biber et al. 2004. The TextEvaluator engine was trained on a large corpus of high-quality, edited texts that had been assigned to specific grade levels by testing agencies for assessment purposes. Factor analysis on these texts yielded several dimensions, with important differences between genres on these factors that were found to affect estimates of text readability. For our purposes, this feature is valuable because it emerged as a separate factor in the TextEvaluator engine, even though that analysis produced another factor that included frequency and length measures that provided a general estimate of vocabulary difficulty. It can thus be assumed to provide additional information about patterns of vocabulary use in student essays.
Conventions
The following AWE features address the normality and conventionality of language. The grammar, usage, and mechanics features are automatically calculated using outputs from the ALEK engine (Leacock and Chodorow 2001; Attali and Burstein 2006) which is designed to detect word sequences likely to represent errors in grammar, usage, mechanics, and style. At the core of the ALEK system is an unsupervised method for identifying likely errors, based upon recognizing combinations of words (and sequences of word categories) that do not normally appear in English, by calculating mutual information and log likelihood statistics that compare the likelihood of a pattern appear in general, versus with a specific word, based on frequency patterns in a large corpus of student essays. The output of this process is further processed using manually created filters to deal with exceptional cases and a rulebase that maps error patterns onto labels for specific error types, such as subject-verb agreement errors, run-on sentences, or missing commas. The output of this process is a set of error type counts, and a mapping from error types to the position in the essay where each error appears. Some of these errors are best described as errors in grammar, in word usage, in mechanics (spelling and punctuation), or in style. The system calculates the total number of grammar, usage, mechanics, and style errors for each essay. To produce summary features that are appropriate for use in a linear regression model, these totals are transformed by taking the negative square root of the proportion of each error type observed.
The grammaticality feature is designed to automatically produce estimates of grammaticality on an ordinal scale, where the specific scale values are 4 (perfect), 3 (comprehensible), 2 (somewhat comprehensible), (1) incomprehensible. Specifically, ridge regression with five-fold cross-validation was deployed to predict sentence grammaticality from a range of linguistic features (Heilman et al. 2014). These features included the number and proportion of misspelled words, the minimum, maximum, and normalized log frequency of the word n-grams in the essay, and the average log probability of sentences calculated by language models, trained respectively on native and non-native texts. The training set was a collection of 3129 English sentences written by language learners as part of a test of English proficiency, annotated by expert raters. The resulting system achieved an accuracy of 80.7% on a binary classification task, when it was only asked to distinguish between grammatical and ungrammatical sentences, and an r of .644 on the ordinal classification task. Unlike the grammar, mechanics, and usage features, which depend on the identification of specific, enumerated errors, the grammaticality feature provides an estimate of how natural and comprehensible a text sounds.
The collocation and preposition usage feature combines information from two feature detectors: a classifier which uses an association measure threshold to detect correct collocations in specific grammatical contexts (Futagi et al. 2008), and a preposition error detection system that builds a maximimum-entropy classifier to predict preposition errors based on contextual features sensitive to lexical and part of speech patterns (Chodorow et al. 2007; Chodorow et al. 2010). The collocation detection system focuses on seven part of speech patterns in which idiomatic relations typically occur (for instance: between an attributive adjective and a noun, or between a verb and its direct object). It then applies the pointwise mutual information ratio statistic to identify whether phrases that appear in these patterns are likely to be idioms. Higher PMI values indicate that the text is more likely to follow idiomatic English usage.
Writing Process Features
Features derived from the keystroke log support several additional dimensions, including effort, transcription fluency, sentence-level planning, and editing behaviors (Deane and Zhang 2015; Zhang and Deane 2015; Zhang et al. 2016). The writing process traits were defined as follows:
Effort
Stronger writers work harder, spending more time to produce more text. The following features address this dimension: the square root of the number of keystrokes produced and the log of total writing time elapsed. As before, the square root and log transformations are intended to make these features more tractable for use in linear models.
Transcription Fluency
Stronger writers type more quickly and fluently. The following features to address this dimension: (1) the mean log length in characters of “bursts” of text production where the writer never paused for longer than 2/3 of a second (corresponding to an ability to produce larger chunks of text without need to deliberate, a likely consequence of increases in typing fluency); (2) the negative mean log duration of pauses between keystrokes within a word (corresponding to more fluent spelling and keyboarding), and (3) the negative mean log duration of pauses between keystrokes while between words (corresponding to little need to pause between words). Here, we take the log to make the data tractable for linear analysis and to deal with the highly skewed nature of latency distributions. The negative sign on the pause duration features makes positive values consistently denote higher degrees of fluency.
Sentence-Level (Interstitial) Planning
Stronger writers are more likely to pause at major text breaks for sentence-level planning (Medimorec and Risko 2017). The following features address this dimension: (1) The proportion of time spent pausing at the end of a sentence, before the punctuation mark, (2) the proportion of time spent pausing at the end of a sentence, after the punctuation mark, and (3) the proportion of time spent pausing before commas and other in-sentence punctuation marks.
Copyediting
Stronger writers monitor their output and edit the resulting text as needed. The following features address this dimension: (1) The relative likelihood of jumping elsewhere in the text before an edit (expressed on a logit scaleFootnote 2), (2) the relative likelihood of pausing before jump edits (expressed on a logit scale), and (3) the relative length of jump edits as a percentage of text length in characters, times negative one (yielding a preference for short jumps, as might occur while scanning a text to find and correct errors).
Trait Summarization and Analysis Procedures
Both pretest forms and posttest forms were administered in a 2013 study (Deane et al. 2018a; Fu et al. 2013; van Rijn et al. 2014; Deane et al. 2019). This dataset is important for our purposes, as it provides a way to equate our pretest and posttest data. However, that study used incomplete data by design, with each student completing two of three forms. Deane et al. (2019) found that the best-fitting factor model is a bifactor model with a general factor and separate specific factors for each form and for each trait, which makes direct use of factor loadings problematic. Therefore, rather than extracting formal factor scores for each trait, we equated feature scores on pretest and posttest, using data from the students in the 2013 study who took both forms. Specifically, we placed each feature on a z-score scale, using means and standard deviations (stds) for within-student data from the 2013 study. Where features had negative factor loadings, we multiplied the z-score by negative one to align positive values with positive loadings, and negative values to negative loadings. Finally, we averaged the normalized feature scores to produce trait indicators. The resulting indicators approximate a combination of the general and trait-specific loadings, without form effects.
We then conducted the following analyses:
-
Associations with human essay scores and test performance. We calculated Pearson correlations of pretest and posttest trait scores with human essay scores and CBAL SBA scale scores.
-
Associations with external measures. We calculated Pearson correlations of pretest and posttest trait scores with prior year course grades and with 2017 and 2018 Smarter Balanced ELA scores. Finally, we conducted regression analyses predicting Smarter Balanced ELA scores from these traits.
-
Analysis of trait score growth patterns. We used GEE to examine the effect of time, school, interaction between school and time, and demographic variables on each trait score.
-
Analysis of correlations between growth measures. We calculated Pearson correlations between Smarter Balanced gain scores (Spring 2017 scale score - Spring 2016 scale score) and trait gain scores (Cash for Grades trait score – Ban Ads trait score). We also conducted regressions to determine which trait scores were significant predictors of 2017 and 2018 Smarter Balanced ELA scores.
We expected that if these traits were useful, they would show significant associations with external metrics, capture meaningful differences in school performance patterns, and have significant associations with growth on external measures.
Results and Discussion
Research Question 1. Evidence of Technical Quality
Inter-rater agreement ranged from acceptable to strong. Agreement between raters on short CR tasks was acceptable, with quadratic weighted kappas between .743 and .836. Pearson correlations also ranged between .745 and .839. The essay was scored on two rubrics, focusing on content and general writing quality. Quadratic weighted kappas ranged from .711 to .833 (with mean/std. equal .77/.05), corresponding to Pearson correlations between .712 and .834 (with mean/std. equal .79/.04).
A single-dimension IRT model for the combined dataset, including responses for all forms on this and the prior, norming study, returned a log-likelihood of −64,616.5 for 175 parameters, for a penalty of 0.734, an Akaike fit statistic of 0.736, and a Gilula-Haberman fit statistic of 0.736. The reliability of the conditional means of the ability parameters in the IRT model was 0.864. Item difficulties ranged between −2.55 and 3.06, with a mean difficulty of 0.46 (std = 1.12). Adjusted residuals for marginal item score frequencies showed significant results for about 1/3 of items. However, inspection of adjusted residuals for item response functions indicated that absolute goodness of fit appears to be acceptable.
Test-retest reliability for raw total scores for Ban Ads (pretest) and Cash for Grades (posttest) was .765. The pretest/posttest scale score correlation was .723. Reasonable relations were also observed with external measures. Ban Ads scale scores correlated .577 with prior year course grades, .768 with 2017 Smarter Balanced ELA scores, and .751 with 2018 Smarter Balanced ELA scores. Cash for Grades scale scores correlated .515 with prior year course grades, .743 with 2017 Smarter Balanced ELA scores, and .758 with 2018 Smarter Balanced ELA scores.
These results indicate that the CBAL SBAs used in this study functioned well. They returned reliable results, were strongly mutually correlated, and had strong correlations with Smarter Balanced ELA scores and moderate correlations with prior year course grades. CBAL/Smarter Balanced correlations (between .74 and .77) were only slightly smaller than the observed Smarter Balanced test-retest reliability (about .80), even though CBAL SBAs were 90-min rather than 3-h assessments. Of course, test-retest reliability could be affected by the time lag between administrations, and the two CBAL assessments were only given four months apart, while the Smarter Balanced assessments were separated by a one-year gap. But for practical purposes, the CBAL SBAs and the Smarter Balanced tests ordered study participants by ability in very similar ways. The relation between CBAL SBA pretest scores and prior-year ELA course grades (.58) is also relatively high, confirming that CBAL SBAs are valid measures of ELA performance. It is therefore reasonable to interpret differences in CBAL SBA scores as reflecting differences in student ELA ability.
Research Question 2. Evidence of Differences among the Study Schools
Quantitative Analysis of State Test Scores
If we examine year-to-year longitudinal differences in Smarter Balanced scores, the following patterns of performance hold. Between 2015 and 2018, all three schools displayed small but significant performance increments between 6th and 7th grade, ranging between 10 and 35 points (about 1/10th to 1/3 of a standard deviation on the Smarter Balanced scale).Footnote 3 School performance patterns also varied by year. There were no statistically significant school differences in the 2015–2016 school year. On the other hand, in the 2016–2017 school year, School C had statistically significantly stronger overall performance compared to the other two schools, but School A demonstrated statistically significantly greater growth.
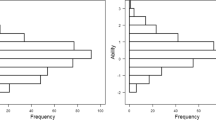
Figure 1 shows the pattern obtaining between 2017 and 2018, when this study took place.

Relative Performance of participating students at the three study schools on the SBAC scale, 2017–2018
We fitted a GEE model that predicted Smarter Balanced ELA scale scores using an identity link (since we judged that a linear model was appropriate for these features) and an unstructured correlation matrix (thereby constructing a linear model that made no prior assumptions about covariance among predictors), entering year of administration, school ID, and interaction between school and year of administration as predictors, along with demographic variables for gender, race, language proficiency, and general education status. All three primary predictors were statistically significant (p < .01). The model parameters indicated the following effect pattern (for details, see Table 3 in Appendix 2):
First, we found a statistically significant main effect of school, in which students at School A were on average about one quarter of a standard deviation higher than students at School C. Students at Schools B and C were not significantly different. Pairwise comparison of estimated marginal means with Bonferroni correction indicated that School A had significantly higher, and that School C had significantly lower means than the overall population mean. Second, we found a statistically significant main effect of time of administration, in which students scored on average about one-eighth of a standard deviation higher on their end-of-year state test compared to the previous year. Third, there was a statistically significant interaction between school and time of administration, in which students at School A increased mean state test scores by about one tenth of a standard deviation compared to students at School C. School B showed a trend toward slower growth that fell short of significance (p = .058). This trend seems more pronounced before controlling for demographic variables (see Fig. 1). Pairwise comparison of estimated means with Bonferroni correction indicated that at pretest, the three schools were not significantly different, but that at posttest, School A had significantly higher estimated means than School C, while Schools B and C were not significantly different. Finally, the demographic features were all statistically significant and followed typical patterns for U.S. schools (e.g., slightly lower performance for males and African-American students, and much lower performance for ELLs and special education students).
Overall, the results are consistent with what we would expect in general for U.S. middle schools. The direction and size of the demographic effects are comparable to those reported elsewhere in the literature (Hanushak et al. 2019; Paschall et al. 2018; Reilly et al. 2019). School A, the suburban school, had the highest mean performance on the Smarter Balanced assessment. However, the prior year results indicated that the school rankings were not consistent over time, suggesting that demographic differences between the schools were not so large as to swamp all other sources of variance. In fact, while School A is a suburban school, it is ethnically diverse, with large minority and special needs populations and a large minority of low-SES students, which means that this school’s stronger state test performance in the 2017–2018 school year might be related to differences in curriculum and instruction, not merely to differences in the underlying population.
Qualitative Analysis of Classroom Observations
Table 1 summarizes the qualitative results obtained from classroom observation. Each teacher was observed instructing multiple class sections. Code frequencies were aggregated across teachers and class sections to arrive at aggregate, school-level frequencies. After tabulating total observed frequencies, we applied numerical thresholds based on the range of observed frequencies across all 34 individual codes (range = 0–21%) and set appropriate numerical thresholds to align with the descriptors used in Table 1 (i.e., “frequently”, “occasionally”, and “rarely”). Overall, School A and School B had very different instructional approaches, with School C falling in the middle, though overall its instructional patterns were closer to School A than to School B.
School A
Based on code frequencies for classroom observations at School A, it was apparent from the field notes that teachers at this school relied on their own, preexisting curriculum to provide summary and argumentative writing instruction. They used CBAL materials on several occasions to check student understanding after instruction. This usage was consistent with what these teachers indicated during the planning meeting. In fact, the most frequent code pertained to teachers presenting information related to argumentative writing and use of CBAL formative tasks. The next most frequent codes indicated that students were doing independent practice, and that teachers were soliciting student responses via questioning or probing for understanding. School A most often relied on print-based CBAL materials distributed at lesson end, though they also utilized computer-based CBAL materials. School A also incorporated collaborative practice but less frequently than independent practice. Thus, School A’s instructional approach built upon a well-developed core curriculum that included frequent teacher-led instruction and explanation, teacher questioning, and independent practice. The CBAL formative tasks were primarily administered during the independent practice phases of the lessons. It is important to note that School A had a general strategy of using formative assessment results to plan additional, focused instruction where appropriate. In our final debriefing, we learned that School A had applied this strategy to students’ argument writing skills, thereby extending the instruction it provided on this topic. Schools B and C immediately moved on to other units after the argument writing unit was complete.
School B
Based on code frequencies for classroom observations at School B, it was apparent from the field notes that teachers in School B built their curriculum around the CBAL formative assessment tasks, as they had indicated during the planning meeting. They systematically implemented CBAL formative assessment tasks as opportunities for independent practice, by administering CBAL tasks in the School Computer lab, then reviewing the task in whole-class discussions. The most frequent codes found in the field notes pertained to teachers soliciting student responses by asking questions and probing for understanding. There were some instances of teachers building and activating students’ background knowledge by connecting lessons to prior learning experiences, but infrequent instances of teachers using CBAL formative assessment tasks to support teacher modeling or to provide explicit instruction. Thus, School B primarily used CBAL formative assessment tasks to launch instruction without prior modeling or guided practice, though there was subsequent teacher questioning and probing for understanding.
School C
Based on code frequencies for classroom observations at School C, it was apparent that teachers at this school used CBAL formative assessment tasks as indicated during the planning meeting. The most frequent code in the field notes pertained to teachers soliciting student responses using questioning or probing for understanding followed less frequently by teachers presenting information related to argumentative writing and the CBAL formative assessment tasks. Lessons were split approximately evenly between preexisting curriculum and lessons built around CBAL formative assessment tasks, presented sometimes in print form, and sometimes by computer. Students did independent practice more frequently than collaborative practice. Thus, School C’s instructional approach can be characterized as relying upon direct instruction and independent practice, with CBAL formative assessment tasks sometimes being used as a launch for instruction, and sometimes as a check for understanding.
These results suggest that School A, and to a lesser extent, School C were well-prepared to teach the argument writing unit and were able to integrate the CBAL formative assessment materials into a framework they had developed in previous years, and that School A, in particular, regularly followed best practices for both formative and interim assessment. On the other hand, School B’s strategy was more like test preparation, since it prioritized giving students practice on the CBAL formative assessment tasks and provided relatively less direct instruction and feedback. These differences parallel the quantitative differences in overall school performance that we observed: stronger overall growth for School A during the school year, and a trend for slower growth for School B. It is impossible, given our study design, to draw causal conclusions, but the observed pattern is at least consistent with the hypothesis that differences in school instructional strategies had an impact on student performance.
Research Question 3. School Differences as Measured by CBAL Scale Scores and Task Subscores
Overall Performance
Figure 2 shows performance patterns for the CBAL SBAs.

Relative performance of participating students at the three study schools on the CBAL SBA, Oct. 2017 – Feb. 2018
We fitted a GEE model using an identity link (since we judged the variables were appropriate for a linear model) and an unstructured correlation matrix (thereby constructing a linear model that made no prior assumptions about covariance among predictors), entering time of administration, school ID, and interaction between school and time of administration, plus demographic variables. The following pattern of effects obtained (for details, see Table 4 in the Appendix 2):
First, there was a statistically significant main effect of school, in which mean scores at School A were three-tenths of a standard deviation higher than mean scores at School C. Mean scores at Schools B and C were not significantly different. Pairwise comparison with Bonferroni correction indicated that estimated means at School A were significantly higher than estimated means at Schools B and C, which were not significantly different. Second, there was a statistically significant main effect of time of administration, in which mean pretest scores were on average one-seventh of a standard deviation higher than mean posttest scores. Third, there was a statistically significant interaction between school and time of administration, in which mean pretest/posttest score differences at School B were about one-sixth of a standard deviation smaller than at School C. Mean score differences for School A were not significantly different from those for School C. Pairwise comparison with Bonferroni correction indicated that at pretest, School A had significantly higher means than School C, but that School B fell in the middle, without being significantly different from either School A or C. At posttest, on the other hand, School A had significantly higher means than either School B or C, but Schools B and C were not significantly different. Once again, the usual demographic patterns for disadvantaged students were statistically significant. Finally, when we examined the relation between growth on CBAL and growth on Smarter Balanced scale scores, we found a small but statistically significant correlation (correlation = .087, p = .037).
These results are generally consistent with the patterns that obtained with the Smarter Balanced end-of-year assessment. Both the Smarter Balanced assessment and the CBAL SBAs indicated that School A had the strongest, and School C, the weakest overall results. Both the Smarter Balanced assessment and the CBAL SBAs showed trends toward stronger growth toward School A, and weaker growth for School B, though they differed about which of the two trends was significant: The Smarter Balanced assessment found significantly greater growth for School A over the course of the school year, whereas the CBAL SBAs showed significantly slower growth for School B during the 4-month period between pretest and posttest. Since there is a significant gain score correlation, it also seems clear that the overall performance increase observed on the CBAL SBAs accounted for part of the increase observed on the Smarter Balanced assessment.
Of course, similar results are likely, given the strong association between the two assessments. However, the CBAL SBAs only assess part of the construct assessed by the Smarter Balanced Assessment and were administered in a shorter time-frame. It is therefore notable that where results from the two assessments differ, they are consistent with the qualitative differences observed among the three schools. Specifically, the significantly slower growth observed for School B is consistent with the fact that School B implemented teaching practices during its unit on argument writing that were less likely to be effective.
Task Level Performance Patterns
When we estimated task-level longitudinal effects using GEE, using the same settings as before, different performance patterns obtained by school (for details, see Table 5 in Appendix 2).
On the summary evaluation task, the following effects obtained: First, there were no statistically significant main effect of school. However, individual test results indicated that School A (but not Schools B or C) had a mean that was significantly higher than the population mean. Second, there was a statistically significant main effect of time of administration (an increase of one quarter of a standard deviation between pretest and posttest). Third, there was a statistically significant interaction between school and time of administration. Pretest/posttest score differences at School B were about one-fifth of a standard deviation less than those at School C. Pretest/posttest differences at School A were not significantly different from those at School C. Pairwise comparison with Bonferroni correction indicated that School A had significantly higher estimated means than School C at pretest but not at posttest. Otherwise, there were no significant school growth differences. Finally, the usual demographic differences obtained. I.e., there were statistically significant differences indicating lower performance for students classified as male, as African-American students, as ELLs, or who were in special education.
On the argument analysis task, the following effects obtained: First, there was a statistically significant main effect of school. School A had higher mean scores than School C (by about three-tenths of a standard deviation). Mean scores for School B were not statistically significantly different than those for School C. Individual test results also indicated that School A (but not Schools B or C) had a mean that was significantly higher than the population mean. Second, there was no statistically significant change in mean score between pretest and posttest. Third, there was no significant interaction between school and time of administration. However, pairwise comparisons with Bonferroni correction indicated that at pretest, the estimated mean for School A was not significantly different from that for Schools B and C, but that on posttest, the estimated mean for School A was significantly greater than the other schools (with p = .024 for School B and p = .031 for School C). There was also no significant effect of gender, though other characteristic demographic effects obtained.
On the short answer questions, the following effects obtained: First, there was a statistically significant main effect of school. The mean score for School A was significantly higher than for School C (by about three tenths of a standard deviation), but students at Schools B and C were not significantly different. However, individual test results indicated that the estimated means for School A was significantly higher, and the estimated mean for School C significantly lower than the population mean. Second, there was a statistically significantly main effect of time of administration. Posttest scores were generally higher than pretest scores, by slightly less than one sixth of a standard deviation. Third, there was a statistically significant interaction between school and time of administration. School B showed smaller mean pretest/posttest score increases than School C. Post-hoc comparisons with Bonferroni corrections further indicated that there were no significant school differences at pretest, but that School A had higher estimated means than either Schools B or School C at posttest.
On the essay question, the following effects obtained: First, there was a statistically significant main effect of school. School A had significantly higher mean scores than School C, by about one-third of a standard deviation, but Schools B and C were not significantly different. Individual test results indicated that the estimated means for Schools A was significantly above the population mean, but that estimated means for Schools B and C were not significantly different from the population mean. Second, there was no statistically significant mean effect of time of administration. Third, there was a statistically significant interaction between school and time of administration, where School A had larger pretest/posttest score increases than School C by about one-fourth of a standard deviation. Pairwise comparisons with Bonferroni correction indicated that none of the schools had significantly different estimated means at pretest, but that at posttest, the estimated mean for School A was significantly stronger than for Schools B and C, which were not significantly different (See Fig. 3). Once again, characteristic demographic patterns applied.

Relative performance of participating students at the three study schools on the culminating CBAL essay task, Oct. 2017 – Feb. 2018
We also calculated associations between task scores, prior year course grades, and Smarter Balanced ELA scores. Each task had small-to-moderate correlations with course grades and moderate correlations with Smarter Balanced scores. Specifically, pretest and posttest summary evaluation tasks correlated .468 and .423 with prior year course grades, .626 and .603 with 2017 Smarter Balanced scores and .617 and .600 with 2018 Smarter Balanced scores. The pretest and posttest argument analysis tasks correlated .375 and .366 with prior year course grades, .529 and .591 with 2017 Smarter Balanced scale scores, and .577 and .615 with 2018 Smarter Balanced scores. The mean score on pretest and posttest short answer tasks correlated .535 and .478 with prior year course grades, .697 and .647 with 2017 Smarter Balanced scores, and .656 and .667 with 2018 Smarter Balanced scores.
We then calculated gain scores (normalized posttest task score – normalized pretest task score) for each task and examined correlations with Smarter Balanced gain scores. There was no significant correlation between the summary evaluation and argument Analysis gain scores and Smarter Balanced gain scores. However, there were significant correlations between CBAL short answer gain scores and Smarter Balanced gain scores (r = .098, p = .020), and between CBAL essay gain scores and Smarter Balanced gain scores (r = .137, p = .00).
These results confirm and elucidate the connection between performance on the CBAL SBAs and performance on the Smarter Balanced end-of-year assessment. Not only did task scores show moderate to strong correlations with Smarter Balanced scores; growth on CBAL constructed-response tasks had small but significant associations with year-to-year growth in Smarter Balanced scores. But perhaps equally importantly, task subscores yielded significantly different growth patterns across the three schools. Specifically, School A showed faster growth on the essay task, while School B showed slower growth on the summary evaluation and short answer tasks. Note that both the summary evaluation and the short answer tasks required students to read and analyze source texts. In fact, two of the three short answer tasks were summary writing tasks. Thus, we can characterize School A as having demonstrated stronger growth in argument essay writing skills than the other two schools, and School B as having demonstrated weaker growth in students’ ability to summarize and analyze arguments in source texts than the other two schools. It is thus possible that the slower growth associated with School B might be a consequence of how that school taught summarization, or that it might reflect slower progress in reading comprehension or other critical supporting skills.
Research Question 4. Sensitivity to School Differences in AWE and Writing Process Traits
Associations with Human Essay Scores and Overall Test Performance
Each writing trait indicator had statistically significant correlations with essay score and overall CBAL SBA score. We observed the following correlations:
The AWE traits mostly had moderate to strong correlations with CBAL scale scores and weak to moderate associations with CBAL essay scores. Specifically, the pretest and posttest elaboration trait scores correlated .624 and .557 with corresponding CBAL scale scores, and .508 and .513 with the CBAL scale score on the other form. They also correlated .715 and .687 with corresponding CBAL essay scores, and .419 and .477 with the CBAL essay scores on the other form. The pretest and posttest vocabulary trait scores correlated .371 and .536 with corresponding CBAL scale scores, and .498 and .368 with the CBAL scale score on the other form. They also correlated .234 and .454 with corresponding CBAL essay scores, and .355 and .311 with the CBAL essay scores on the other form. The pretest and posttest conventions trait scores correlated .380 and .412 with corresponding CBAL scale scores, and .419 and .360 with the CBAL scale score on the other form. They also correlated .416 and .374 with corresponding CBAL essay scores, and .340 and .260 with the CBAL essay scores on the other form.
Depending on the trait, the writing process traits strong, moderate, or weak correlations with CBAL scale scores and CBAL essay scores. Specifically, the pretest and posttest effort trait scores correlated .547 and .548 with corresponding CBAL scale scores, and .405 and .470 with the CBAL scale score on the other form. They also correlated .665 and .717 with corresponding CBAL essay scores, and .371 and .458 with the CBAL essay scores on the other form. The pretest and posttest transcription fluency trait scores correlated .362 and .198 with corresponding CBAL scale scores, and .221 and .244 with the CBAL scale score on the other form. They also correlated .475 and .265 with corresponding CBAL essay scores, and .295 and .321 with the CBAL essay scores on the other form. The pretest and posttest sentence planning trait scores correlated .280 and .234 with corresponding CBAL scale scores, and .165 and .274 with the CBAL scale score on the other form. They also correlated .309 and .243 with corresponding CBAL essay scores, and .218 and .243 with the CBAL essay scores on the other form. Finally, the pretest copyediting trait score was not correlated with posttest essay or CBAL scale scores, but correlated .099 with CBAL pretest ELA scale scores, and .186 with CBAL pretest essay scores. The posttest copyediting score correlated .221 with pretest CBAL pretest scale scores, .287 with posttest CBAL scale scores, .146 with pretest essay scores, and .339 with posttest essay scores.
These results suggest that performance on the writing trait indicators was meaningfully related both to performance on the essay and to overall performance on the SBA. For the most part, they fall in a range that suggests that they capture related but not identical constructs. However, the copyediting trait appears to function differently at pretest and at posttest. Since students in a 7th grade class are typically only just beginning to learn how to write argument essays and may have little prior experience with writing on a computer, it is entirely possible that students were only just beginning to learn how to edit texts digitally.
Associations with External Measures
Each writing trait measure, except for copyediting on pretest, had significant correlations with external measures. However, the size of the correlations differed by trait. Overall, the AWE trait scores had stronger correlations with external measures than the writing process trait scores.
Specifically, the AWE trait scores had moderate to small correlations with external measures. The pretest and posttest elaboration trait scores correlated .473 and .418 with prior year course grades, .560 and .517 with 2017 Smarter Balanced scale scores, and .541 and .537 with 2018 Smarter Balanced scale scores. The pretest and posttest vocabulary trait scores correlated .309 and .389 with prior year course grades, .429 and .515 with 2017 Smarter Balanced scale scores, and .398 and .503 with 2018 Smarter Balanced scale scores. The pretest and posttest convention trait scores correlated .282 and .308 with prior year course grades, .381 and .488 with 2017 Smarter Balanced scale scores, and .365 and.477 with 2018 Smarter Balanced scale scores.
The writing process trait scores had mostly small correlations with external measures, except for the effort trait, which showed moderate correlations. Specifically, the pretest and posttest effort trait scores correlated .410 and .298 with prior year course grades, .449 and .392 with 2017 Smarter Balanced scale scores, and .413 and .407 with 2018 Smarter Balanced scale scores. The pretest and posttest transcription fluency trait scores correlated .216 and .243 with prior year course grades, .305 and .200 with 2017 Smarter Balanced scale scores, and .304 and .225 with 2018 Smarter Balanced scale scores. The pretest and posttest sentence planning trait scores correlated .145 and .104 with prior year course grades, .220 and .208 with 2017 Smarter Balanced scale scores, and .226 and .213 with 2018 Smarter Balanced scale scores. Finally, the pretest copyediting trait scores were not significantly correlated with external measures, but the posttest copyediting scores correlated .237 with prior year course grades, .281 with 2017 Smarter Balanced scale scores, and .232 with 2018 Smarter Balanced scale scores.
When 2017 Smarter Balanced scores were regressed on pretest writing traits, the resulting model accounted for 39.2% of variance. 5 of 7 traits were significant predictors: elaboration (standardized weight = .230, p < .001), vocabulary (standardized weight = .287, p < .001), conventions (standardized weight = .200, p < .001), effort (standardized weight = .122, p = .024), and transcription fluency (standardized weight = .114, p = .006). When Smarter Balanced scores were regressed on posttest writing traits, the resulting model accounted for 44.5% of variance. Once again, 5 of 7 traits were significant predictors, though the copyediting trait came near to significance: elaboration (standardized weight = .193, p < .001), vocabulary (standardized weight = .158, p = .002), conventions (standardized weight = .307, p < .001), effort (standardized weight = .117, p = .038), and transcription fluency (standardized weight = .146, p = .001).
These results confirm that the writing trait indicators provided useful information about student writing performance, although two of the writing process indicators (sentence planning and copyediting) had weak correlations with external measures and did not contribute to the prediction of overall performance. It is worth noting that both of these measures were based on relatively limited data. If students wrote very short essays, as many lower-performing students did, the sentence planning feature might be based only a few observations. Similarly, the 7th-grade students in our data did very little copyediting. Only about 2% of the keystrokes in our data represented editing actions. Most students appear to have followed a knowledge-telling strategy in which they started writing, kept adding new information to the end of the text, and stopped without attempting revisions or additions. The change that we observed in the status of the copyediting trait may therefore reflect real changes in student writing strategies. When a rare behavior becomes significantly associated with external measures, it is reasonable to hypothesize that this change reflects learning.
Correlations with External Growth Measures
We also examined correlations between Smarter Balanced gain scores and essay writing trait gain scores. Gain scores for two traits had statistically significant correlations with Smarter Balanced gain scores: elaboration (.150, p = .007), and effort (.165, p = .002). These are, of course, the traits that have the strongest overall association with writing performance, and they have intrinsic connections to motivation and knowledge about writing. Students who spend more time writing and produce longer, more richly articulated texts are likely to be more fluent, confident, and knowledgeable writers. If students increase their writing ability in this way, it should not be particularly surprising to find a concomitant increase in their overall English Language Arts performance.
Patterns of Growth in Product Traits
We calculated GEE models estimating the effects of school and time of administration, their interaction, and demographic variables on the product trait indicators. We built these models using an identity link (since we judged a linear model appropriate for these features) and an unstructured correlation matrix (thereby constructing a linear model that made no prior assumptions about covariance among predictors). All measures were calculated using trait indicator scores produced by averaging normalized component feature values, using the means and standard deviations observed within-student in the 2013 dataset to put pre- and post-test scores on the same scale. For details, see Table 6 in Appendix 2.
On the elaboration trait, the following effects were observed. We found a statistically significant main effect of school, in which School A had significantly higher mean scores than School C (by about one-quarter of a standard deviation), but Schools B and C were not significantly different. Individual test results indicated that School A did not have significantly higher estimated means than School B. We also found a statistically significant main effect of time of administration (an increase of about two-tenths of a standard deviation between pretest and posttest). However, there was no significant interaction between school and time of administration. All characteristic demographic patterns applied.
On the expressive vocabulary trait, the following effects were observed. We found a statistically significant main effect of school, in which mean trait scores for School A were about half a standard deviation higher than for School C, and mean trait scores for School B were also about three-tenths of a standard deviation higher. Individual test results indicated that School C had significantly lower estimated means than Schools A and B, but that Schools A and B were not significantly different. We also found a statistically significant interaction between school and time of administration, in which School A showed greater mean trait score increases than School C, by about a third of a standard deviation. Students at Schools B and C were not significantly different. Pairwise comparison with Bonferroni correction indicated that at pretest, there were no statistically significant difference in estimated means among the three schools, but that at posttest, School A had significantly higher estimated means than Schools B and C, which were not significantly different from one another. However, there was no statistically significant main effect of time of administration. We did not find a statistically significant mean difference between African-American and other students, but otherwise, all characteristic demographic patterns obtained.
On the conventions trait, the following effects were observed. We found a statistically significant main effect of school, in which students at School A had performances that were on average a quarter of a standard deviation higher than students at School C. Students from School B were not significantly different from students at School C. Individual test results indicated that School A, but not Schools B or C, had an estimated mean significantly higher than the population mean. There was no significant main effect of time of administration, and no significant interaction between school and time of administration. We did not find a significant overall difference between African-American and other students, but otherwise, all characteristic demographic patterns applied.
Patterns of Growth in Process Traits
We also calculated GEE models for the four process trait indicators. Again, all measures were calculated using trait indicator scores produced by averaging the normalized values of their component features. For details of these models, see Table 7 in Appendix 2.
On the effort trait, the following effects were observed. There was a statistically significant main effect of school, in which School A had mean scores about four-tenths of a standard deviation higher than School C. Means scores at Schools B and C were not significantly different. Individual test results indicated that estimated means for School A were significantly higher, and estimated means for School C, significantly lower than the population mean. There was also a statistically significant main effect of time of administration, in which mean posttest scores were on average about one third of a standard deviation higher than mean pretest scores. In addition, there was a statistically significant interaction between school and time of administration: Mean scores at School A were on average about three-tenths of a standard deviation higher on posttest than pretest. Schools B and C were not significantly different. Pairwise comparison with Bonferroni correction indicated that estimated means for the three schools were not significantly different at pretest, but that at posttest, School A had statistically stronger estimated means than School C. At posttest, the pairwise contrast between Schools B and C approached significance (p = .053). There was no statistically significant difference in overall performance between African-American and other students (or between ELLs and other students), but otherwise, all characteristic demographic patterns applied.
On the transcription fluency trait, the following effects were observed. There was no significant main effect of school. However, there was a statistically significant main effect of time of administration. Mean posttest scores were almost three-tenths of a standard of deviation higher than pretest scores. Our results also indicated a statistically significant interaction between school and time of administration. Mean score increases for School A were significantly lower than for School C, by about one-sixth of a standard deviation. Mean score increases for Schools B and C were not significantly different. However, pairwise comparison with Bonferroni correction found no significant school differences at either pretest or posttest. Our results did not indicate a significant difference in transcription fluency between ELLs and other students, but otherwise, characteristic demographic patterns applied.
On the sentence planning trait, the following effects obtained. There was a statistically significant main effect of school. School A displayed significantly more sentence planning pause time than School C (by more than one-half standard deviation). Schools B and C were not significantly different. Individual test results indicated that School A had an estimated mean significantly higher than, and School C an estimated mean significantly lower than the population mean. There was also a statistically significant interaction between school and time of administration. The mean score change for School A was half a standard deviation higher than for School C. Mean score changes for Schools B and C were not significantly different. Pairwise comparison with Bonferroni correction indicated no significant differences at pretest. At posttest, pairwise comparison indicated that School A had significantly higher estimated means than Schools B and C, which were not significantly different from one another. However, there was no significant main effect of time of administration, nor were there any significant demographic effects, except for ELLs, who demonstrated significantly less sentence planning pause time than other students.
On the copyediting trait, the following results obtained. There was a statistically significant main effect of time of administration. Mean posttest performance was about six-tenths of a standard deviation higher than mean pretest performance. However, there was no statistically significant main effect of school, nor any statistically significant interactions between school and time of administration. Special education students showed less copyediting behavior, by slightly more than a quarter of a standard deviation, but otherwise, there were no significant demographic effects.
Overall, we observe the following patterns (see Table 2): (a) a pattern of performance in which School A is significantly stronger than School C on most traits, with School B falling in the middle; (b) overall growth in elaboration, effort, transcription fluency, and copyediting; (c) differentially stronger growth for School A in expressive vocabulary, effort, and sentence planning.
Overall, the AWE and writing process data indicate significant changes in how all the students wrote regardless of which school they attended. Students elaborated their essays more at posttest (an effect equal to about two-tenths of a standard deviation), showed greater effort (an effect equal to about three-tenths of a standard deviation), increased their transcription fluency (also by about three-tenths of a standard deviation), and began to display more copyediting behavior (an increase of about six-tenths of a standard deviation). The change in copyediting behavior was particularly large and coincided with a change in the relationship between copyediting and Smarter Balanced scores: nonsignificant at pretest, significant at posttest. These changes suggest that students’ instructional experience, which included targeted instruction and multiple experiences with digital writing, may have caused students to write more fluently and to make a more focused effort to correct their writing as needed, even if it did not directly increase essay quality.
As we have seen, only School A improved essay posttest scores (by about a quarter of a standard deviation). But this improvement coincided with an increase in effort and vocabulary sophistication (each by more than three-tenths of a standard deviation) and with half of a standard deviation increase in time spent on sentence planning. Half a standard deviation is a sizable effect, particularly considering that students at School A started out half a standard deviation ahead of students at the other schools. This pattern suggests that the approach School A took to argument writing instruction may have had a differential impact on the time and effort students put into developing their writing. This is certainly a plausible result, since our qualitative results indicated that School A may have had the strongest instructional practices.
General Discussion and Conclusion
This study was intended to test a specific strategy for providing interim assessment of writing and related ELA skills during the school year. We combined three sources of information: scenario-based assessment, automated writing evaluation using natural language processing methods, and automated analysis of student writing processes using features derived from keystroke logs. Our hypothesis was that we could combine these methods to profile changes in student performance. Specifically, we devised a battery of indicators that included four task scores (summary evaluation, short-answer writing, argument analysis, and essay writing), three AWE essay traits (elaboration, vocabulary, and conventions), and four writing process traits (effort, transcription fluency, sentence planning, and copyediting). We evaluated the validity and reliability of these indicators and examined their sensitivity to changes in student performance. Since we applied this method to three schools, each of which designed and implemented its own curriculum, this paper should be interpreted as a case study in the use of automated indicators to detect changes in ELA (and specifically, writing) performance during the school year.
Study schools demonstrated preexisting differences in instructional practices and educational philosophy. Since we did not implement a controlled experimental design, we cannot evaluate causal inferences about the observed school differences. Also, since this study drew its data from a specific population (7th-grade students at majority-minority middle schools in a mid-Atlantic state), further studies are needed to demonstrate how our results generalize. In addition, since we were unable to obtain individual-level socioeconomic data, we could not control for socioeconomic differences among schools. However, even with these limitations, our results suggest that it may be feasible to extract reliable information about student writing progress from classroom reading and writing tasks.
In this particular case, the battery of indicators that we applied enabled us to characterize how the three schools differed and to describe in detail how student performance changed after instruction. None of the schools demonstrated significant changes in performance on the argument analysis tasks. All three schools achieved significantly higher summary evaluation and short answer scores on the posttest, but School B, which appeared to have less effective formative assessment practices, showed significantly weaker growth. On the essay writing task, only School A, which appeared to have the most effective formative assessment practices, had significantly higher scores at posttest. This increase in essay writing scores coincided with significant increases in the richness of expressive vocabulary, significantly more time spent on sentence planning, and a greater increase in overall effort compared to the other two schools. However, all three schools demonstrated significant increases in elaboration, effort, transcription fluency, and copyediting behavior, which indicates that the other two schools did improve aspects of students’ essay writing performance, even if overall essay quality did not increase.
The differences in school profiles highlight issues that would be of great interest to teachers and school administrators. It is impossible to tell, from the assessment results alone, why the schools showed different patterns of performance. But the assessment results suggest formative hypotheses that could be explored in greater depth by school staff, and which could be used to inform changes in instructional strategy (Bennett 2010). We must ask, for instance, why School B showed slower improvement on summary-related tasks. All three schools reported teaching a summary writing unit early in Fall 2017, before pretest administration. However, our qualitative analysis suggests that School B might have afforded fewer opportunities to practice writing outside of class and fewer occasions for focused formative feedback. This may have resulted in students at School B retaining ineffective source use strategies longer than students at other schools. Of course, other explanations are possible. School B’s slower growth on the summary evaluation and short answer is also consistent with slower growth in reading comprehension skills, since both tasks require students to read and analyze source texts. Similarly, we must ask why only school A demonstrated improvements in essay scores. Our results suggest that motivation might be part of the answer, since students at School A put in significantly more effort than students at other schools. However, the increase in sentence planning times, combined with an improvement specifically in expressive vocabulary scores, suggests more effective idea generation strategies. If this hypothesis is correct, the other schools might have been able to replicate aspects of School A’s success by adopting School A’s curricular framework and/or its approach to formative assessment, since effective formative assessment practices are known to increase motivation and effort (Cauley and McMillan 2010). Overall, these results demonstrate the potential for SBAs to support instructional and curricular decisions. Changes in AWE and writing process traits, combined with changes in SBA subscores, may enable a more precise characterization of the impact of instruction on performance. This is the kind of information educators need to make targeted shifts in instruction.
While we collected AWE and writing process indicators from the SBA essay writing task, these features could in principle be collected for any digital writing task. If they were collected in the background, and reported to teachers for formative purposes, they might support an even more flexible form of background assessment. That is, the writing traits deployed in this study could, in principle, be calculated for formative writing tasks, as an automated form of curriculum-based measurement. Our results therefore also suggest that such trait measures might also be used more broadly as classroom measures, though further studies would be needed to assess this possibility. In either case, the use of AWE and writing process measures, in addition to the use of SBAs, would provide much richer information about patterns of student performance and enable teachers and school administrators to assess how student performance changes over the course of the school year.
Data Availability
The data for the accompanying study may be obtained from the corresponding author’s institution by submitting a request form found at https://www.ets.org/s/research/pdf/ets_research_data_policy.pdf. Upon completion, this should be sent electronically to ExternalDataRequests@ets.org for review. If approval is granted, a representative from the corresponding author’s institution will provide the data to the requestor. The authors request that researchers wishing to work with this data also communicate directly with the corresponding author, who may be able to help facilitate any requests.
Notes
These items are rated on four- to six-point scales. We use quadratic weighted kappas since this metric assigns higher agreement scores when raters assign less-divergent scores, rather than penalizing all disagreements equally.
A logit scale is a method for transforming proportional data so that it will work well in linear models. It takes the form \( logit(x)=\log \left(\frac{p(x)}{1-p(x)}\right) \) where p is the probability of x.
References
Almond, R., Deane, P., Quinlan, T., Wagner, M., & Sydorenko, T. (2012). A preliminary analysis of keystroke log data from a timed writing task (ETS RR-12-23). ETS Research Report Series, 2012(2): I-61. https://doi.org/10.1002/j.2333-8504.2012.tb02305.x.
Attali, Y., & Burstein, J. (2006). Automated essay scoring with e-rater® V. 2. Journal of Technology, Learning and Assessment, 4(3). Retrieved from https://eric.ed.gov/?q=e-rater+version+2.0&id=EJ1110978
Attali, Y., & Powers, D. (2009). Validity of scores for a developmental writing scale based on automated scoring. Educational and Psychological Measurement, 69(6), 978–993. https://doi.org/10.1177/0013164409332217.
Au, W. (2007). High-stakes testing and curricular control: A qualitative metasynthesis. Educational Researcher, 36(5), 258–267. https://doi.org/10.3102/0013189X07306523.
Beigman Klebanov, B., & Flor, M. (2013). Associative texture is lost in translation. Proceedings of the workshop on discourse in machine translation (DiscoMT), pp. 27–32, Sofia, Bulgaria, august 9, 2013.
Bennett, R. E. (2010). Cognitively based assessment of, for, and as learning (CBAL): A preliminary theory of action for summative and formative assessment. Measurement: Interdisciplinary Research and Perspectives, 8(2–3), 70–91. https://doi.org/10.1080/15366367.2010.508686.
Bennett, R. E. (2011). CBAL: Results from piloting innovative K–12 assessments (ETS RR-11-23). ETS Research Report Series, 2011(1), i-39 https://doi.org/10.1002/j.2333-8504.2011.tb02259.x.
Bennett, R. E., Deane, P., & van Rijn, P. W. (2016). From cognitive-domain theory to assessment practice. Educational Psychologist, 51(1), 1–26. https://doi.org/10.1080/00461520.2016.1141683.
Bennett, R. E., & Gitomer, D. H. (2009). Transforming K-12 assessment: Integrating accountability testing, formative assessment, and professional support. In C. Wyatt-Smith & J. Cumming (Eds.), Educational assessment in the 21st century (pp. 43–61). New York: Springer.
Biber, D. (1986). Spoken and written textual dimension in English: Resolving the contradictory findings. Language, 62, 394–414.
Biber, D. (1988). Variation across speech and writing. Cambridge: Cambridge University Press.
Biber, D., Conrad, S., Reppen, R., Byrd, P., Helt, M., Clark, V., . . . Urzua, A. (2004). Representing language use in the university: Analysis of the TOEFL 2000 Spoken and Written Academic Language Corpus. TOEFL Monograph Series, MS-25, January 2004. Princeton, NJ: Educational Testing Service.
Black, P., & Wiliam, D. (1998). Assessment and classroom learning. Assessment in Education: Principles, Policy & Practice, 5(1), 7–74. https://doi.org/10.1080/0969595980050102.
Burstein, J., Marcu, D., & Knight, K. (2003). Finding the WRITE stuff: Automatic identification of discourse structure in student essays. IEEE Intelligent Systems, 18(1), 32–39.
Burstein, J., Tetreault, J., & Madnani, N. (2013). The e-rater automated essay scoring system. In M. Shermis & J. Burstein (Eds.), Handbook of automated essay evaluation: Current applications and new directions (2nd ed., pp. 55–67). New York: Taylor & Francis.
Cauley, K. M., & McMillan, J. H. (2010). Formative assessment techniques to support student motivation and achievement. The clearing house: A journal of educational strategies, issues and ideas, 83(1), 1–6.
Chodorow, M., Gamon, M., & Tetreault, J. (2010). The utility of article and preposition error correction systems for English language learners: Feedback and assessment. Language Testing, 27(3), 419–436.
Chodorow, M., Tetreault, J., & Han, N.-R. (2007). Detection of grammatical errors involving prepositions. Paper presented at the Proceedings of the fourth ACL-SIGSEM workshop on prepositions.
Corbin, J., & Strauss, A. (2008). Strategies for qualitative data analysis. In Basics of Qualitative Research. Techniques and Procedures for Developing Grounded Theory. Thousand oaks, CA: Sage.
Coxhead, A. (2000). A new academic word list. TESOL quarterly, 34, 213–238Deane, P. (2005). A nonparametric method for extraction of candidate phrasal terms. Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), pp. 605-613.
Deane, P. (2005). A nonparametric method for extraction of candidate phrasal terms. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05) pp. 605–613.
Deane, P., Sheehan, K. M., Sabatini, J., Futagi, Y., & Kostin, I. (2006). Differences in text structure and its implications for assessment of struggling readers. Scientific Studies of Reading, 10(3), 257–275.
Deane, P. (2011). Writing assessment and cognition (ETS RR-11-14). ETS Research Report Series, 2011(1), i-60. https://doi.org/10.1002/j.2333-8504.2011.tb02250.x.
Deane, P. (2013). Covering the construct: An approach to automated essay scoring motivated by a socio-cognitive framework for defining literacy skills. In M. Shermis & J. Burstein (Eds.), Handbook of automated essay evaluation: Current applications and new directions (2nd ed., pp. 298–312). New York: Routledge.
Deane, P. (2014a). Vocabulary features for E-rater. Princeton: Internal project report, Educational Testing Service.
Deane, P. (2014b). Using writing process and product features to assess writing quality and explore how those features relate to other literacy tasks (ETS RR-14-03). ETS Research Report Series, 2014(1), 1–23. https://doi.org/10.1002/ets2.12002.
Deane, P., Andreyev, S., & Wong, V. (2011a). Recommendation for adding a sentence variety/ sentence style feature to e-rater. Princeton: Internal project report, Eu.
Deane, P., Fowles, M., Baldwin, D., & Persky, H. (2011b). The CBAL summative writing assessment: A draft eighth-grade design (ETS RM-11-01). Retrieved from Princeton, New Jersey: https://www.ets.org/research/policy_research_reports/publications/report/2011/imvl
Deane, P., & Quinlan, T. (2010). What automated analyses of corpora can tell us about students' writing skills. Journal of Writing Research, 2(2), 152-177. https://doi.org/10.17239/jowr-2010.02.02.4.
Deane, P., Quinlan, T., & Kostin, I. (2011c). Automated scoring within a developmental, cognitive model of writing proficiency (RR-11-16). ETS Research Report Series, 2011(1), i-93. https://doi.org/10.1002/j.2333-8504.2011.tb02252.x.
Deane, P., Roth, A., Litz, A., Goswami, V., Steck, F., Lewis, M., & Richter, T. (2018a). Behavioral differences between retyping, drafting, and editing: A writing process analysis (ETS RM-18-06). Retrieved from Princeton, NJ: https://www.ets.org/research/policy_research_reports/publications/report/2018/jzfj
Deane, P., & Song, Y. (2014). A case study in principled assessment design: Designing assessments to measure and support the development of argumentative reading and writing skills. Educativa Psicologia, 20(2), 99–108. https://doi.org/10.1016/j.pse.2014.10.001.
Deane, P., Song, Y., van Rijn, P. W., O’Reilly, T., Fowles, M., Bennett, R., et al. (2018b). The case for scenario-based assessment of written argumentation. Reading and Writing, 32, 1575–1606. https://doi.org/10.1007/s11145-018-9852-7.
Deane, P., Williams, F., Weng, V., & Trapani, C. S. (2013). Automated essay scoring in innovative assessments of writing from sources. The Journal of Writing Assessment, 6(1), 40–56. Retrieved from http://www.journalofwritingassessment.org/article.php?article=65
Deane, P., & Zhang, M. (2015). Exploring the feasibility of using writing process features to assess text production skills (ETS RR-15-26). ETS Research Report Series, 2015(2), 1–16. https://doi.org/10.1002/ets2.12071.
Deane, P., Bennett, R.E., van Rijn, P., Guo, H., Zhang, M., & Li, C. (2019). Defining a multidimensional model for characterizing performance on a scenario-based assessment of argument Reading and writing. Princeton, NJ: Internal project report, Educational Testing Service.
Flor, M., & Beigman Klebanov, B. (2014). Associative lexical cohesion as a factor in text complexity. International Journal of Applied Linguistics, 165(2), 2014.
Flor, M., Beigman Klebanov, B., Sheehan, K. (2013). Lexical tightness and text complexity; Proceedings of the 2nd Work shop of Natural Language Processing for Improving Textual Accessibility (NLP4ITA); pp. 29-38; Jun. 2013.
Fu, J., Chung, S., & Wise, M. (2013). Dimensionality analyses of CBAL writing tests. (ETS RR-13-10). ETS Research Report Series, 2013(1), i-33. https://doi.org/10.1002/j.2333-8504.2013.tb02317.x.
Fu, J., & Wise, M. (2012). Statistical report of 2011 CBAL multistate administration of reading and writing tests (ETS RR-12-24). ETS Research Report Series, 2012(2), i-59. https://doi.org/10.1002/j.2333-8504.2012.tb02306.x.
Futagi, Y., Deane, P., Chodorow, M., & Tetreault, J. (2008). A computational approach to detecting collocation errors in the writing of non-native speakers of English. Computer Assisted Language Learning, 21(4), 353–367.
Graesser, A. C., McNamara, D. S., & Kulikowich, J. M. (2011). Coh-Metrix: Providing multilevel analyses of text characteristics. Educational Researcher, 40(5), 223–234. https://doi.org/10.3102/0013189X11413260.
Graff, D., & Cieri, C. (2003). English Gigaword. LDC2003T05. Philadelphia: Linguistic Data Consortium.
Haberman, S. J. (2013). A general program for item-response analysis that employs the stabilized Newton-Raphson algorithm (ETS RR-13-32). ETS Research Report Series, 2013(2), i-98. https://doi.org/10.1002/j.2333-8504.2013.tb02339.x.
Hanushak, E.A., Peterson, P.E., Talpey, L.M., & Woessman, L. (2019). The unwavering SES achievement gap: Trends in US student performance. (EdWorkingPaper no.19-33). Retrieved from Annenberg Institute at Brown University: http://edworkingpapers.com/ai19-33
Hardin, J. W., & Hilbe, J. M. (2003). Generalized estimating equations. Boca Raton: Chapman and Hall.
Heilman, M., Cahill, A., Madnani, N., Lopez, M., & Mulholland, M. (2014). Predicting grammaticality on an ordinal scale. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), pp. 174–180, Baltimore, Maryland, USA, June 23-25, 2014.
Leacock, C., & Chodorow, M. (2001). Automatic assessment of vocabulary usage without negative evidence. ETS Research Report Series, 2001(2), i-19.
Lin, D. 1998. Automatic retrieval and clustering of similar words. In Proceedings of the 17th International Conference on Computational linguistics - Volume 2, pp. 768-774. Association for Computational Linguistics.
Lipsitz, S., & Fitzmaurice, G. (2008). Generalized estimation equations for longitudinal data analysis (pp. 43–78). Chapman & Hall/CRC: Longitudinal data analysis. New York.
Marcu, D. (2000). The theory and practice of discourse parsing and summarization. Cambridge: MIT Press.
McNamara, D. S., & Graesser, A. C. (2012). Coh-Metrix: An automated tool for theoretical and applied natural language processing. In P. M. McCarthy & C. Boonthum-Denecke (Eds.), Applied natural language processing: Identification, investigation and resolution (pp. 188–205). Hershey: IGI Global.
Michel, J. B., Shen, Y. K., Aiden, A. P., Veres, A., Gray, M. K., The Google Books Team, Pickett, J. P., Hoiberg, D., Clancy, D., Norvig, P., Orwant, J., Pinker, S., Nowak, M. A., & Aiden, E. L. (2011). Quantitative analysis of culture using millions of digitized books. Science, 331, 176–182.
Medimorec, S., & Risko, E. F. (2017). Pauses in written composition: On the importance of where writers pause. Reading and Writing, 30, 1–19. https://doi.org/10.1007/s11145-017-9723-7.
Page, E. B. (2003). Project Essay Grade: PEG. In M. Shermis & J. Burstein (Eds.), Automated Essay Scoring: A Cross-disciplinary Perspective. Lawrence Erlbaum (pp. 43–54). Mahwah: Lawrence Erlbaum Associates.
Paschall, K.W., Gershoff, E.T. & Kuhfeld, M. (2018). A two-decade examination of historical race/ethnicity disparities in educational achievement by poverty status. Journal of Youth and Adolescence, 47, 1164–1177. https://link.springer.com/article/10.1007%2Fs10964-017-0800-7
Quinlan, T., Higgins, D., & Wolff, S. (2009). Evaluating the construct-coverage of the e-rater® scoring engine (ETS RR-09-01). ETS Research Report Series, 2009(1), i-35. https://doi.org/10.1002/j.2333-8504.2009.tb02158.x.
Reilly, D., Neumann, D.L., & Andrews, G. (2019). Gender differences in reading and writing achievement: Evidence from the National Assessment of educational Progress (NAEP). American Psychologist 74, 4, 445–458. https://doi.apa.org/doiLanding?doi=10.1037%2Famp0000356
Sabatini, J. P., O'Reilly, T., Halderman, L. K., & Bruce, K. (2014). Integrating scenario-based and component reading skill measures to understand the reading behavior of struggling readers. Learning Disabilities Research & Practice, 29(1), 36–43. https://doi.org/10.1111/ldrp.12028.
Sheehan, K. M. (2016). A review of evidence presented in support of three key claims in the validity argument for the TextEvaluator® text analysis tool (ETS RR-16-12). ETS Research Report Series, 2015(1), 1–16. https://doi.org/10.1002/ets2.12100.
Sheehan, K. M., Kostin, I., Napolitano, D., & Flor, M. (2014). The TextEvaluator tool: Helping teachers and test developers select texts for use in instruction and assessment. The Elementary School Journal, 115(2), 184–209. https://doi.org/10.1086/678294.
Sheehan, K. M., & O'Reilly, T. (2011). The CBAL reading assessment: An approach for balancing measurement and learning goals (ETS RR-11-21). ETS Research Report Series, 2011(1), i-26. https://doi.org/10.1002/j.2333-8504.2011.tb02257.x.
Shermis, M. D., Mzumara, H. R., Olson, J., & Harrington, S. (2001). On-line grading of student essays: PEG goes on the world wide web. Assessment & Evaluation in Higher Education, 26(3), 247–259. https://doi.org/10.1080/02602930120052404.
Smarter Balanced Assessment Consortium. (2017). Smarter Balanced Assessment Consortium: 2016–17 technical report. Retrieved from https://portal.smarterbalanced.org/library/en/2016-17-summative-assessment-technical-report.pdf
Smarter Balanced Assessment Consortium. (2018a). Answers to questions about Smarter Balanced 2017 test results. Retrieved from http://portal.smarterbalanced.org/library/en/answers-to-questions-about-2017-test-results.pdf
Smarter Balanced Assessment Consortium. (2018b). Smarter Balanced Assessment Consortium: 2017–18 summative technical report. Retrieved from http://www.smarterbalanced.org/wp-content/uploads/2019/08/2017-18-Summative-Assessment-Technical-Report.pdf
Somasundaran, S., Burstein, J. & Chodorow, M. (2014). Lexical chaining for measuring discourse coherence in test-taker essays. Proceedings of COLING 2014, the 25th international conference on computational linguistics: Technical papers, pp. 950–961, Dublin, Ireland, august 23–29, 2014.
Song, Y., Deane, P., & Fowles, M. (2017). Examining students' ability to critique arguments and exploring the implications for assessment and instruction (ETS RR-17-16). ETS Research Report Series, 2017(1), 1–12. https://doi.org/10.1002/ets2.12166.
van Rijn, P. W., Graf, E. A., & Deane, P. (2014). Empirical recovery of argumentation learning progressions in scenario-based assessments of English language arts. Psicología Educativa, 20(2), 109–115. https://doi.org/10.1016/j.pse.2014.11.004.
Van Waes, L., Leijten, M., Wengelin, Å., & Lindgren, E. (2012). Logging tools to study digital writing processes. In V. W. Berninger (Ed.), Past, present, and future contributions of cognitive writing research to cognitive psychology (pp. 507–536). New York and London: Psychology Press.
Wilson, J., & Roscoe, R. D. (2020). Automated writing evaluation and feedback: Multiple metrics of efficacy. Journal of Educational Computing Research 58(1), 87-125. 10.1177%2F0735633119830764.
Zhang, M., & Deane, P. (2015). Process features in writing: Internal structure and incremental value over product features (ETS RR-15-27). ETS Research Report Series, 2015(2), 1–12. https://doi.org/10.1002/ets2.12075.
Zhang, M., Deane, P., Feng, G., & Guo, H. (2019a). Investigating an approach to evaluating keyboarding fluency. Paper presented at the Society for Text and Discourse, New York, NY.
Zhang, M., Hao, J., Li, C., & Deane, P. (2016). Classification of writing patterns using keystroke logs. Paper presented at the quantitative psychology research. The 80th annual meeting of the psychometric society, Beijing. China.
Zhang, M., van Rijn, P. W., Deane, P., & Bennett, R. E. (2019b). Scenario-based assessments in writing: An experimental study. Educational Assessment, 24(2), 73–90. https://doi.org/10.1080/10627197.2018.1557515.
Zhang, M., Zou, D., Wu, A. D., Deane, P., & Li, C. (2017). An investigation of writing processes employed in scenario-based assessment. In B. D. Zumbo & A. M. Humbley (Eds.), Understanding and investigating response processes in validation research (pp. 321–339). New York: Springer.
Zipf, G.K. (1935). The Psycho-biology of Language: An Introduction to Dynamic Philology. Houghton Mifflin Company, 1935; MIT press, 1965.
Funding
All work conducted in this study was funded as internal research by the Educational Testing Service and the University of Delaware.
Author information
Authors and Affiliations
Contributions
Paul Deane and Joshua Wilson developed the study conception and design, which was reviewed and agreed to by the other authors. Material preparation and data collection were performed by Paul Deane, Joshua Wilson, Amanda Roth, Eowyn Winchester, and Theresa Richter. Analysis was performed by Paul Deane, Joshua Wilson, Mo Zhang, Chen Li, Peter Van Rijn, and Hongwen Guo. The first draft of the manuscript was written by Paul Deane and elaborated by Joshua Wilson, and then circulated among the other authors for comments and edits. Their feedback informed subsequent revisions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
None.
Code Availability
The code used to calculate the AWE and writing process features is proprietary ETS software. However, the algorithms implemented in this code base are fully documented in the publications cited in this paper, and comparable open-source implementation of similar algorithms can be found in the literature.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Codebook for Field Notes
-
1.
The level of integration of CBAL materials into their instruction (curriculum, unit design)
-
a.
Use CBAL as the main instructional materials
-
b.
Use CBAL as supplementary materials
-
c.
No CBAL material
-
a.
-
2.
The form of CBAL/lesson integration
-
a.
Computer-based
-
b.
Print-based
-
c.
Both
-
a.
-
3.
Level of interaction/scaffolding between teachers and students within instruction (pedagogy)
-
a.
Building and activating background knowledge
-
i.
Connecting to prior learning in the year
-
ii.
Connecting to previous experience or prior knowledge
-
i.
-
b.
I Do
-
i.
Presents information related to the argumentative writing and CBAL materials
-
ii.
Models
-
i.
-
c.
We do
-
i.
Students are asked to read off a worksheet or PowerPoint for other students in the class
-
ii.
Soliciting student response - defined as questioning or probing for understanding (launching question)
-
iii.
Feedback (teacher-to-student)
-
i.
-
d.
You do
-
i.
Students do independent practice (e.g., complete CBAL tasks independently)
-
ii.
Students do collaborative practice (e.g., partner reading)
-
iii.
Homework (e.g., complete the task at home)
-
i.
-
a.
-
4.
Student factors
-
a.
Engagement - on task behavior/ interest?
-
i.
More engaged (e.g., paying attention to the task, no talking or chatting with other students)
-
ii.
Less engaged (e.g., raising a hand to go to bathroom, talking or chatting with other students)
-
i.
-
b.
Attitude toward task
-
i.
Positive (e.g., like it, happy)
-
ii.
Negative (e.g., get bored, dislike)
-
i.
-
c.
Familiarity with computer-based testing vs. computer-based learning
-
d.
Familiarity with the content/genre
-
e.
Ability
-
i.
Easy
-
ii.
hard
-
i.
-
a.
-
5.
Classroom factors
-
a.
Classroom management (“control”)- effective
-
b.
Classroom management (“control”)- ineffective
-
a.
-
6.
Technical Issues
Appendix 2: Model Parameters
Rights and permissions
About this article

Cite this article
Deane, P., Wilson, J., Zhang, M. et al. The Sensitivity of a Scenario-Based Assessment of Written Argumentation to School Differences in Curriculum and Instruction. Int J Artif Intell Educ 31, 57–98 (2021). https://doi.org/10.1007/s40593-020-00227-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40593-020-00227-x