
Abstract
In the last few years, a lot of research has been devoted to developing new techniques for improving the recall and the precision of current web search engines. Few works deal with the interesting problem of identifying the communities to which pages belong. Most of the previous approaches try to cluster data by means of spectral techniques or by means of traditional hierarchical algorithms. The main problem with these techniques is that they ignore the relevant fact that web communities are social networks with distinctive statistical properties.
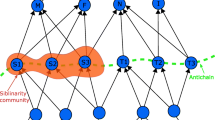
In this paper we analyze web communities on the basis of the evolution of an initial set of hubs and authoritative pages. The evolution law captures the behaviour of page authors with respect to the popularity of existing pages for the topics of interest. Assuming such a model, we have found interesting properties of web communities. On the basis of these properties we have proposed a technique for computing relevant properties for specific topics. Several experiments confirmed the validity of both the model and identification method.
Similar content being viewed by others


References
D. Achlioptas, A. Fiat, A. Karlin, and F. McSherry, “Web search through hub synthesis,” in Proc. of FOCS Conf., 2001, pp. 500–509.
L. A. Adamic, “The Small World Web,” in Proc. of ECDL'99, Lecture Notes in Computer Science, Vol. 1696, Springer, 1999, pp. 443–452.
W. Aiello, F. Chung, and L. Lu, “A random graph model for massive graphs,” in Proc. of STOC Conf., 2001, pp. 171–180.
W. Aiello, F. Chung, and L. Lu, “Random evolution of massive graphs,” in Proc. of FOCS Conf., 2001, pp. 510–519.
A.-L. Barabasi and R. Albert, “Emergence of scaling in random networks,” Science 286, 1999, 509–512.
K. Bharat and M. R. Henzinger, “Improved algorithms for topic distillation in a hyperlinked environment,” in Proc. of SIGIR Conf., 1998, pp. 104–111.
A. Broder, R. Kumar, F. Maghoul, P. Raghavan, S. Rajogo-palan, R. Stata, A. Tompkins, and J. Wiener, “Graph structure in the Web,” in Proc. of WWW Conf., 2000, pp. 309–321.
D. Cohn and H. Chang, “Learning to probabilistic identify authoritative documents,” Artificial Intelligence, 2000.
J. Dean and M. Henzinger, “Finding related pages in the World Wide Web,” in Proc. of WWW Conf., 1999.
G. W. Flake, S. Lawrence, and G. C. Lee, “Efficient identification of Web communities,” in Proc. of KDD Conf., 2000, pp. 150–160.
D. Gibson, J. M. Kleinberg, and P. Raghavan, Inferring Web Communities from Link Topology,” in Proc. of ACM Conf. on Hypertext and Hypermedia, 1998, pp. 225–234.
M. Girvan and M. E. J. Newman, “Community structure in social and biological networks,” Proc. Natl. Acad. Sci. USA, submitted.
G. Greco, S. Greco, and E. Zumpano, “A probabilistic approach for distillation and ranking of web pages,” WWW Journal 4(3), 2001, 189–207.
G. Greco, S. Greco, and E. Zumpano, “A probabilistic approach for discovering authoritative web pages,” in Proc. of WISE Conf., 2001.
L. Ikpaahindi, “An overview of bibliometrics: its measurements, laws and their applications,” Libri 35, 1985, 163–177.
D. Kempe, J. M. Kleinberg, and A. J. Demers, “Spatial gossip and resource location protocols,” in Proc. of STOC Conf., 2001, pp. 163–172.
M. Kessler, “Bibliographic coupling between scientific papers,” American Documentation, 14, 1963, 10–25.
J. M. Kleinberg, “Authoritative sources in a hyperlinked environment,” Journal of the ACM 46(5), 1999, 604–632.
J. M. Kleinberg, “The small-world phenomenon: an algorithm perspective,” in Proc. of STOC Conf., 2000, pp. 163–170.
R. Kumar, P. Raghavan, S. Rajagopalan, and A. Tomkins, “Extracting large-scale knowledge bases from the Web,” in Proc. of VLDB Conf., 1999, pp. 639–650.
R. Kumar, P. Raghavan, S. Rajagopalan, D. Sivakumar, A. Tomkins, and E. Upfal, “Stochastic models for the Web graph,” in Proc. of FOCS Conf., 2000.
T. Murata, “Discovery of Web communities based on the co-occurrence of references,” in Discovery Science: Third International Conference, DS'2000, Vol. 1967, 2000, pp. 65–75.
M. E. J. Newman, “Clustering and preferential attachment in growing networks,” Phys. Rev. E 64, 2001.
S. Nomura, S. Oyama, and T. Hayamizu, “Analysis and improvements of HITS algorithm for detecting Web communities,” 2001.
C. H. Papadimitriou, H. Tamaki, P. Raghavan, and S. Vempala, “Latent semantic indexing: A probabilistic analysis,” in Proc. of PODS Conf., 1998, pp. 159–168.
S. R. Ravi Kumar, P. Raghavan, S. Rajagopalan, and A. Tomkins, “Trawling the Web for emerging cybercommunities,” in Proc. of WWW Conf., 1999, pp. 1481–1493.
H. Small, “Co-citation in the scientific literature: A new measure of the relationship between two documents,” J. American Soc. for Inf. Sci. 24(4), 1999, 1172–1177.
T. Walsh, “Search in a Small World,” in Proc. of IJCAI, 1999, pp. 1172–1177.
D. J. Watts, Small World, Princeton University Press, 1999.
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Greco, G., Greco, S. & Zumpano, E. Web Communities: Models and Algorithms. World Wide Web 7, 59–82 (2004). https://doi.org/10.1023/B:WWWJ.0000015865.63749.b2
Issue Date:
DOI: https://doi.org/10.1023/B:WWWJ.0000015865.63749.b2