

Abstract
The main focus of this work is a novel framework for the joint reconstruction and segmentation of parallel MRI (PMRI) brain data. We introduce an image domain deep network for calibrationless recovery of undersampled PMRI data. The proposed approach is the deep-learning (DL) based generalization of local low-rank based approaches for uncalibrated PMRI recovery including CLEAR [6]. Since the image domain approach exploits additional annihilation relations compared to k-space based approaches, we expect it to offer improved performance. To minimize segmentation errors resulting from undersampling artifacts, we combined the proposed scheme with a segmentation network and trained it in an end-to-end fashion. In addition to reducing segmentation errors, this approach also offers improved reconstruction performance by reducing overfitting; the reconstructed images exhibit reduced blurring and sharper edges than independently trained reconstruction network.
Index Terms—: Parallel MRI, calibrationless, CNN
1. INTRODUCTION
The segmentation of MR images is vital for the quantification of disease progression. For instance, the atrophy of important brain regions (e.g. hippocampal sub-regions, cortical thickness) are established biomarkers for progression in Alzhiemers disease; the volume estimates of these regions play important roles in the early diagnosis and prognosis of dementia subjects. Several segmentation methods, including classical k-means clustering algorithms, deformable templates, and state of the art convolutional neural networks are available. These methods exploit the coherence of image intensities within similar tissues (e.g. gray matter, white matter) as well as edges between tissue boundaries to obtain good segmentation. Clearly, the ability to accurately resolve the small sub-regions depend on the spatial resolution of the images.
A challenge with the acquisition of high resolution MRI data is the long scan time, which is especially challenging for older adults. Long acquisition times are also associated with extensive motion artifacts. Modern MRI methods often rely on acceleration methods including PMRI and compressive sensing to reduce the scan time. Calibrated methods such as SENSE/GRAPPA [1, 2] as well as recent calibrationless structured low-rank methods [3, 4] have been introduced to recover the images from undersampled measurements. Our recent work has shown that linear relations between their k-space measurements can be capitalized using k-space DL strategies [5], which are more computationally efficient than classical methods. Despite the great progress made in image reconstruction, undersampling artifacts and blurring of image edges are inevitable at high acceleration factors; these artifacts can deteriorate the performance of segmentation algorithms that exploit the edges and the coherence of image intensities within regions that would be impacted by undersampling.
We introduce a novel framework for deep-learning based calibration-free MRI reconstruction and segmentation. The main contributions of this work are (1) the development of a novel image domain deep structured low-rank framework for calibration-free PMRI, motivated by locally low-rank methods used for PMRI [6] and (2) the development of a joint segmentation-reconstruction framework to minimize segmentation errors introduced by undersampling artifacts and to improve reconstruction quality. The CLEAR formulation exploits the low-rank structure of image patches from sensitivity weighted images [6]. The low-rank structure results in inter and intra patch annihilation relations on the sensitivity weighted images. The annihilation relations vary spatially, depending on the coil sensitivities. An iterative reweighted formulation of the nuclear norm minimization algorithm in CLEAR as in [5] results in an alternating scheme; the algorithm alternates between data consistency steps and denoising/projection using a spatially varying filterbank. Motivated by [5], we propose to replace the filterbank with an image domain CNN module [5]. In this work, we propose to use a UNET for the image domain CNN. We pre-learn the parameters of the unrolled algorithm, where the CNN parameters are shared across iterations, from exemplar data. The main distinction of this work with [5] is the formulation in the image domain; the increased number of annihilation relations between multi-channel images in the image domain compared to k-space that is exploited by [2, 3, 4, 5] translate to improved performance.
To reduce the sensitivity of the segmentation algorithm to undersampling artifacts, we consider the end-to-end training of a cascade of the proposed reconstruction network with a segmentation network. We use a loss-metric, which is the sum of the mean square image reconstruction error and segmentation error to train the cascade network. The end-to-end training is expected to reduce segmentation errors compared to the straightforward cascade of individual algorithm. Because the loss metric is a combination of reconstruction and segmentation errors, one would expect the quality of the training images recovered by the reconstruction network to be inferior to the one trained with only the reconstruction loss. However, we conjecture that the segmentation loss term further reduces the generalization error, thus improving the mean square error on the test data. Specifically, the end-to-end optimization strategy ensures that the reconstructed images preserve edges and exhibit good coherence between regions with similar anatomical properties, and preserve edges, which will ensure good segmentation. In this work, we propose to use a UNET for segmentation; as in the case with the reconstruction, any segmentation network can be used within the proposed framework. In this work, we consider a simple segmentation setting, where we consider the segmentation of MR images to gray matter (GM), white matter (WM), and cerebrospinal fluid (CSF) regions.
2. METHODS
2.1. Image Domain Deep-SLR for PMRI
The forward model for PMRI recovery can be defined as,
| (1) |
where bi are noisy Fourier coefficients of ith coil image γi corrupted by Gaussian noise ni, N is the total number of coils, is the Fourier operator and denotes the sampling operator. The CLEAR formulation makes the locally-low rank assumption; it assumes that matrix composed of patches of γi(s) are low-rank. Specifically, if we assume to be a patch extraction operator that extracts M × M patches centered at s0, the matrices
| (2) |
are low-rank. The CLEAR approach solves for Γ = [γ1, .., γN] as the nuclear norm minimization problem
| (3) |
If we assume the rank of Γs to be r < N, this implies that there exists N − r null-space vectors us,j and vs,j such that us,jΓs = 0 and Γsvs,j = 0. If we consider the vertical concatenation of the patches denoted by the vector ps, we can express the above relations compactly as
| (4) |
Here, ei denotes the canonical basis vectors of the patches. We note that the inner-products of the patches with the M2 + N row vectors in (4) can be viewed as the convolution of the multichannel volume Γ by flipped filters of size M ×M ×N, evaluated at s. Hence, (4) can be compactly expressed as
| (5) |
where (qs * Γ) (s)denotes the output of a multichannel filter bank qs evaluated at s. We note that the image domain formulation has more annihilation relations than the corresponding k-space approaches [2, 3, 4, 5]. Specifically, any local filter than annihilates ρ (e.g wavelet filters that vanish in smooth regions) will annihilate all of the multichannel patches. We expect the ability of the formulation to exploit intra and inter channel annihilation relations to translate to improved performance.
Using the iterative reweighted formulation in [5] to minimize the nuclear norm minimization problem (3), we alternate between
| (6) |
and the derivation of the qs matrices as in [5, 4]. We note that qs is a spatially varying filterbank that is derived from the signal patches Γs itself. Motivated by [5], we replace the spatially varying and signal-dependent filterbank by a deep CNN; we note that CNNs can closely approximate spatial variations in the linear filterbank structure. The proposed algorithm is formulated as
| (7) |
where denotes a residual multichannel CNN; the input to the filterbank has N channels corresponding to the coil sensitivity weighted images. Here, is a spatial domain CNN. We choose as a 2D spatial domain
| (8) |
| (9) |
We propose to learn the parameters of the CNN in the unrolled algorithm from exemplar data using an end-to-end optimization strategy. The loss of the supervised training is chosen as , where Γ is the output of the unrolled CNN and Γgs is the gold standard multicoil data obtained from fully sampled measurements. The Adam optimizer is used to minimize training loss at a learning rate of 10−4 for all the experiments. It is named as Image Domain Deep-SLR (I-DSLR).
I-DSLR eliminates the need for calibration data for estimating the coil sensitivities or linear filters Qs. Moreover, this approach eliminates the need for singular value decompositions at each iterations that contributes heavily to the computational complexity of CLEAR [6]. Similar to MoDL [7] and [5], we share the parameters of the CNN block across iterations.
3. JOINT RECONSTRUCTION & SEGMENTATION
As discussed previously, the straightforward cascade of reconstruction and segmentation algorithms can result in the propagation of error, thus downgrading segmentation quality. Specifically, the residual alias artifacts as well as blurring caused by undersampling can result in segmentation errors. To minimize this issue, we propose a multi-task deep network as shown in Fig. 1. The reconstruction network is I-DSLR (described in Section 2) with shared weights across iterations. A segmentation network is attached to the final iteration of the I-DSLR. The combined network is trained end-to-end.
Fig. 1.
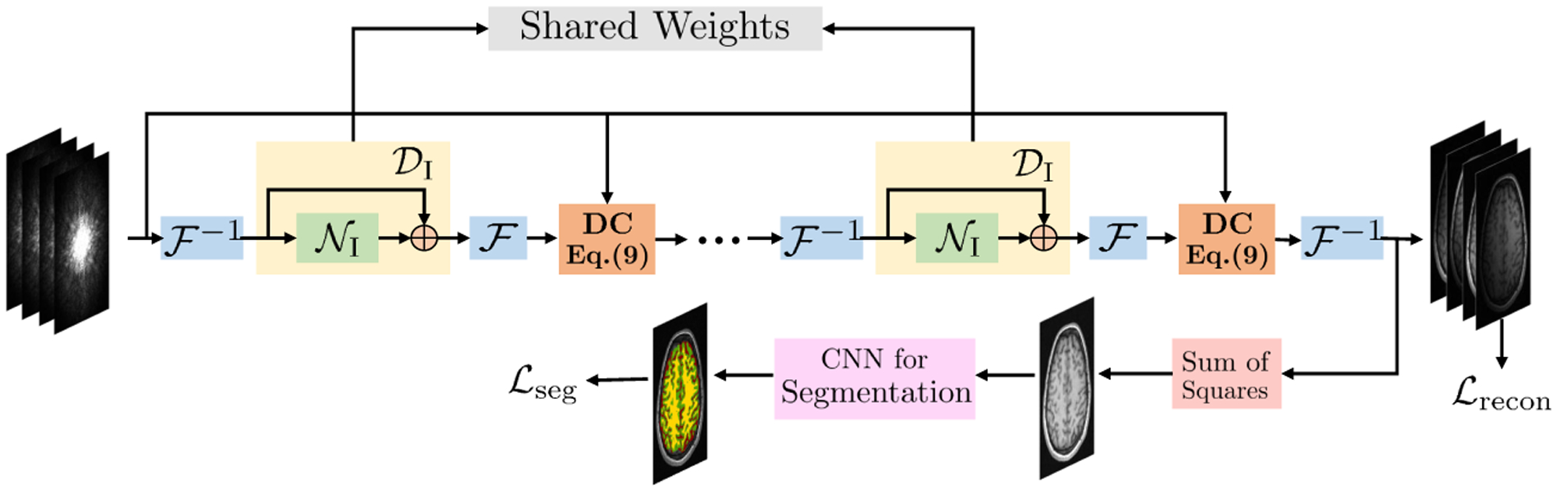
Proposed I-DSLR-SEG-E2E network architecture. A K-iteration I-DSLR network is cascaded with a CNN for segmentation. It is trained end-to-end.
We use a weighted linear combination of normalized mean squared error and pixel-wise multi-label cross entropy error for training. For each pixel p, ϕgs is the gold standard segmentation on the sum-of-squares image obtained from Γgs and ϕ is the segmentation CNN output.
| (10) |
The proposed multi-task network is initialized with weights obtained from pre-trained reconstruction and segmentation networks for training. Specifically, the segmentation UNET is pre-trained with fully sampled images. The reconstruction network is trained with undersampled k-space measurements. The pre-training for both the tasks were done with the brain images described in section 4. β = 1 is chosen to equally weigh both the losses.
4. EXPERIMENTS AND RESULTS
We perform experiments on the publicly available Calgary Campinas Dataset (CCP) [8]. It consists of 12-channel raw k-space data of T1-weighted brain MRI scans from a Discovery MR750 3T scanner for 67 subjects. The slice dimensions are 208 × 170 for axial view of the brain. Ground truth segmentations for the slices were generated using the FAST software which uses the standard k-means clustering technique for segmentation. Forty subjects (40 × 256 = 10240 slices) were used for training, 7 for validation and the remaining 20 for testing purposes. 2D non-uniform cartesian variable density undersampling masks with different acceleration factors were used for experiments; readout direction is orthogonal to axial slices.
The proposed image domain Deep-SLR approach with segmentation algorithms pre-trained using fully sampled data (I-DSLR-SEG) is compared against k-space Deep-SLR method(K-DSLR-SEG), total variation (TV-SEG) and undersampled (US-SEG) in the same setting. We also show the benefit of end-to-end training by comparing the above methods against I-DSLR-SEG-E2E, which is a cascade of I-DSLR and UNET Segmentation networks trained end-to-end (E2E). I-DSLR-SEG is the direct cascade of pre-trained I-DSLR and UNET-based segmentation networks. In TV-SEG, the segmentation network is trained and tested on images reconstructed using TV. Similarly, for US, the segmentation network is trained and tested on undersampled datasets.
A comparison of the methods is recorded and shown in Table 1 and Fig. 2 respectively. The I-DSLR reconstructions have sharper edges with more information preserved compared to US, TV and K-DSLR. The corresponding segmentation performance improves with increase in reconstruction quality. The end-to-end training strategy in I-DSLR-SEG-E2E further improves quality over I-DSLR-SEG. Its improved reconstruction can be attributed to the regularization by the segmentation network and vice-versa. I-DSLR-SEG-E2E alleviates errors propagated from reconstruction to segmentation unlike K-DSLR-SEG and I-DSLR-SEG settings.
Table 1.
Quantitative comparisons of reconstruction (SNR in dB) and segmentation (dice coefficients) quality for different methods. The metrics are averaged over 20 subjects.
| 8-Fold Accelerated Reconstruction and Segmentation | ||||
|---|---|---|---|---|
| Methods | SNR | Dice CSF | Dice GM | Dice WM |
| US-SEG | 10.21 | 0.658 | 0.745 | 0.763 |
| TV-SEG | 16.13 | 0.701 | 0.772 | 0.803 |
| K-DSLR-SEG | 17.82 | 0.749 | 0.781 | 0.835 |
| I-DSLR-SEG | 19.28 | 0.763 | 0.799 | 0.856 |
| I-DSLR-SEG-E2E | 19.85 | 0.802 | 0.862 | 0.907 |
Fig. 2.
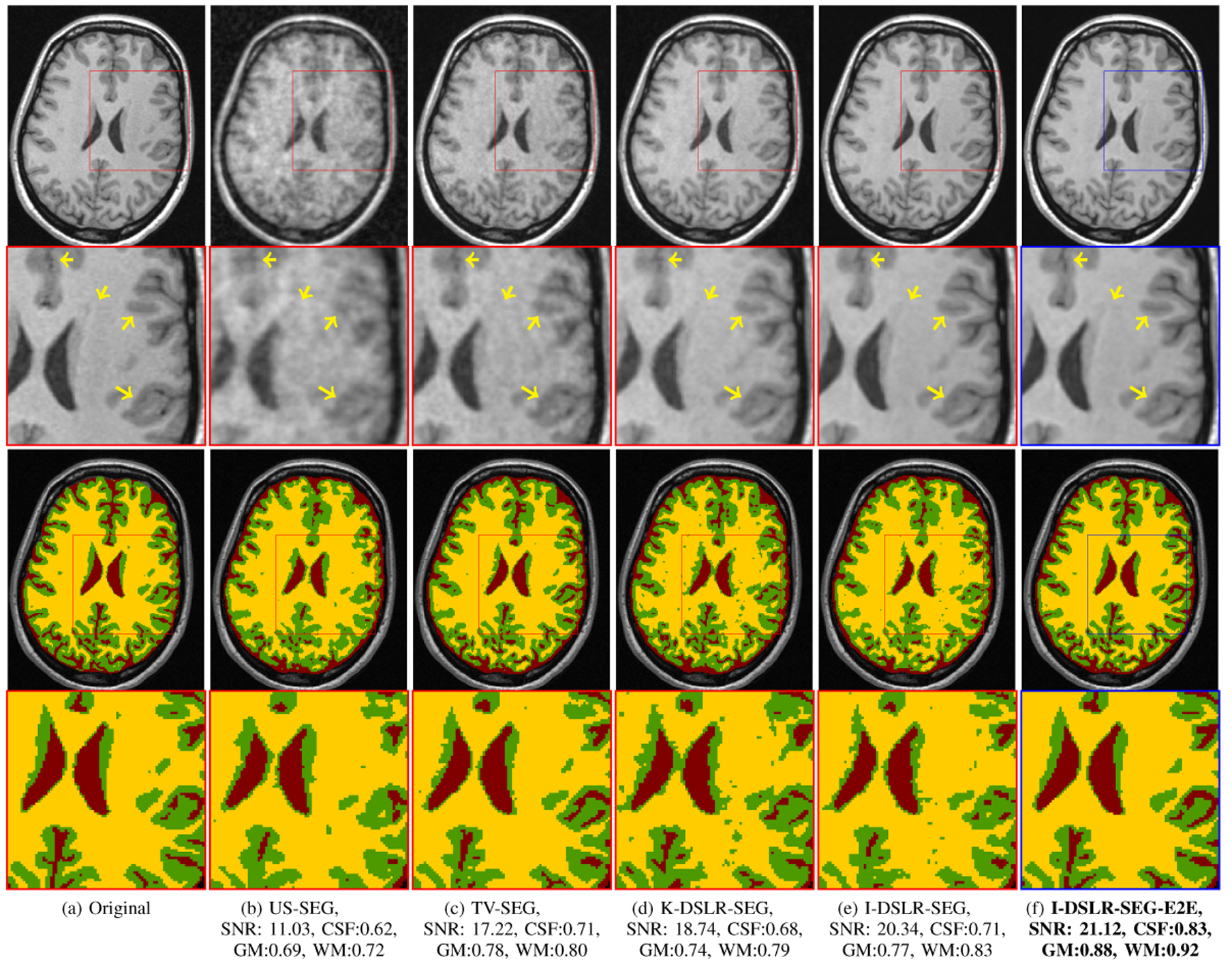
Comparison of reconstruction and segmentation quality of various methods on 6-fold undersampled k-space measurements. Reconstruction SNR in dB along with dice coefficients for CSF, GM and WM are reported for the particular slice. The methods in red box typically cascade separately trained tasks and the blue one is the proposed end-to-end training approach.
5. CONCLUSION
We introduced a novel image domain model-based DL approach for calibrationless PMRI recovery. It is a non-linear extension of locally low rank methods for calibrationless parallel MRI. The experiments show that additional annihilation relations exploited by I-DSLR approach offers better performance over k-space approach K-DSLR [5]. We introduce a multi-task framework where I-DSLR is cascaded with a segmentation dedicated DL network which is trained end-to-end. The networks regularize each other, thereby reducing the errors caused from undersampling artifacts. Experiments show that the segmentation accuracy depends on the reconstruction quality. I-DSLR-SEG-E2E reduces the propagation of errors from reconstruction to segmentation, this outperforming methods that cascade independently trained networks.
Acknowledgments
This work is supported by NIH 1R01EB019961-01A1.
Footnotes
COMPLIANCE WITH ETHICAL STANDARDS
This research study was conducted using a public domain Calgary Campinas Dataset (CCP) [8].
7. REFERENCES
- [1].Pruessmann et al. , “SENSE: sensitivity encoding for fast MRI,” MRM, vol. 42, no. 5, pp. 952–962, 1999. [PubMed] [Google Scholar]
- [2].Griswold et al. , “Generalized autocalibrating partially parallel acquisitions (GRAPPA),” MRM, vol. 47, no. 6, pp. 1202–1210, 2002. [DOI] [PubMed] [Google Scholar]
- [3].Uecker et al. , “ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA,” MRM, vol. 71, no. 3, pp. 990–1001, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Mathews et al. , “Structured Low-Rank Algorithms: Theory, Magnetic Resonance Applications, and Links to Machine Learning,” IEEE SPM, vol. 37, no. 1, pp. 54–68, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Pramanik et al. , “Deep Generalization of Structured Low-Rank Algorithms (Deep-SLR),” IEEE TMI, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Trzasko Joshua D and Manduca Armando, “CLEAR: Calibration-free parallel imaging using locally low-rank encouraging reconstruction,” in ISMRM, 2012, vol. 517. [Google Scholar]
- [7].Aggarwal et al. , “MoDL: Model-based deep learning architecture for inverse problems,” IEEE TMI, vol. 38, no. 2, pp. 394–405, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Souza et al. , “An open, multi-vendor, multi-field-strength brain mr dataset and analysis of publicly available skull stripping methods agreement,” NeuroImage, vol. 170, pp. 482–494, 2018. [DOI] [PubMed] [Google Scholar]