
Abstract
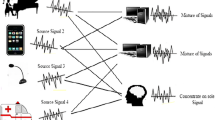
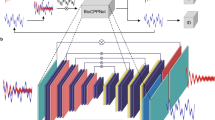
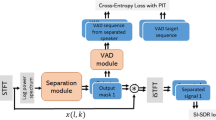
The cocktail party problem, i.e., tracing and recognizing the speech of a specific speaker when multiple speakers talk simultaneously, is one of the critical problems yet to be solved to enable the wide application of automatic speech recognition (ASR) systems. In this overview paper, we review the techniques proposed in the last two decades in attacking this problem. We focus our discussions on the speech separation problem given its central role in the cocktail party environment, and describe the conventional single-channel techniques such as computational auditory scene analysis (CASA), non-negative matrix factorization (NMF) and generative models, the conventional multi-channel techniques such as beamforming and multi-channel blind source separation, and the newly developed deep learning-based techniques, such as deep clustering (DPCL), the deep attractor network (DANet), and permutation invariant training (PIT). We also present techniques developed to improve ASR accuracy and speaker identification in the cocktail party environment. We argue effectively exploiting information in the microphone array, the acoustic training set, and the language itself using a more powerful model. Better optimization objective and techniques will be the approach to solving the cocktail party problem.
Similar content being viewed by others
Change history
11 June 2018
In the original version of this article, the affiliations are incorrect. The correct affiliations are given above.
The corresponding author’s E-mail address should be yanminqian@sjtu.edu.cn.
19 April 2019
In the original version of this article, there is a mistake about the result of DPCL++ (Isik et al., 2016) in Section 5.6 (Fig. 7). As reported in Isik et al. (2016), the SDR improvement was 10.3 dB, rather than 9.4 dB. For further information, the best performance in Isik et al. (2016) was 10.8 dB with the help of a more complicated architecture.
References
Abdel-Hamid O, Mohamed A, Jiang H, et al., 2014. Convolutional neural networks for speech recognition. Annual Conf of Int Speech Communication Association, p.1533–1545.
Anguera X, Wooters C, Hernando J, 2007. Acoustic beamforming for speaker diarization of meetings. IEEE Trans Audio Speech Lang Process, 15(7):2011–2022. https://doi.org/10.1109/TASL.2007.902460
Applebaum S, 1976. Adaptive arrays. IEEE Trans Antennas Propag, 24(9):585–598. https://doi.org/10.1109/TAP.1976.1141417
Barker J, Ma N, Coy A, et al., 2010. Speech fragment decoding techniques for simultaneous speaker identification and speech recognition. Comput Speech Lang, 24(1):94–111. https://doi.org/10.1016/j.csl.2008.05.003
Behnke S, 2003. Discovering hierarchical speech features using convolutional non-negative matrix factorization. Int Joint Conf on Neural Networks, p.2758–2763. https://doi.org/10.1109/IJCNN.2003.1224004
Bello RWJ, 2010. Identifying repeated patterns in music using sparse convolutive non-negative matrix factorization. 11th Int Society for Music Information Retrieval Conf, p.123–128.
Benesty J, Chen J, Huang Y, et al., 2007. On microphonearray beamforming from a MIMO acoustic signal processing perspective. IEEE Trans Audio Speech Lang Process, 15(3):1053–1065. https://doi.org/10.1109/TASL.2006.885251
Benesty J, Chen J, Huang Y, 2008. Automatic Speech Recognition: a Deep Learning Approach. Springer Berlin Heidelberg, New York, USA.
Bi M, Qian Y, Yu K, 2015. Very deep convolutional neural networks for LVCSR. 16th Annual Conf of Int Speech Communication Association, p.3259–3263.
Bregman AS, 1990. Auditory scene analysis. In: Smelzer NJ, Bates PB (Eds.), International Encyclopedia of the Social and Behavioral Sciences. Elsevier, Amsterdam.
Brown GJ, Cooke M, 1994. Computational auditory scene analysis. Comput Speech Lang, 8(4):297–336. https://doi.org/10.1006/csla.1994.1016
Capon J, 1969. High resolution frequency-wavenumber spectrum analysis. Proc IEEE, 57:1408–1418. https://doi.org/10.1109/PROC.1969.7278
Carter GC, Nuttall AH, Cable PG, 1973. The smoothed coherence transform. Proc IEEE, 61:1497–1498. https://doi.org/10.1109/PROC.1973.9300
Chang X, Qian Y, Yu D, 2018. Adaptive permutation invariant training with auxiliary information for monaural multi-talker speech recognition. Int Conf on Acoustics, Speech, and Signal Processing, in press.
Chen J, Benesty J, Huang Y, 2006. Time delay estimation in room acoustic environments: an overview. EURASIP J Adv Signal Process, 2006:026503. https://doi.org/10.1155/ASP/2006/26503
Chen N, Qian Y, Yu K, 2015. Multi-task learning for textdependent speaker verification. Annual Conf of Int Speech Communication Association, p.185–189.
Chen Z, 2017. Single Channel Auditory Source Separation with Neural Network. PhD Thesis, Columbia University, New York, USA.
Chen Z, Ellis DP, 2013. Speech enhancement by sparse, low-rank, and dictionary spectrogram decomposition. Workshop on Applications of Signal Processing to Audio and Acoustics, p.1–4. https://doi.org/10.1109/WASPAA.2013.6701883
Chen Z, McFee B, Ellis DP, 2014. Speech enhancement by low-rank and convolutive dictionary spectrogram decomposition. Annual Conf of Int Speech Communication Association, p.2833–2837.
Chen Z, Li J, Xiao X, et al., 2017a. Cracking the cocktail party problem by multi-beam deep attractor network. IEEE Workshop on Automatic Speech Recognition and Understanding, p.437–444.
Chen Z, Luo Y, Mesgarani N, 2017b. Deep attractor network for single-microphone speaker separation. Int Conf on Acoustics, Speech, and Signal Processing, p.246–250. https://doi.org/10.1109/ICASSP.2017.7952155
Chen Z, Droppo J, Li J, et al., 2017c. Progressive joint modeling in unsupervised single-channel overlapped speech recognition. http://arxiv.org/abs/1707.07048
Cherry EC, 1953. Some experiments on the recognition of speech, with one and with two ears. J Acoust Soc Am, 25(5):975–979. https://doi.org/10.1121/1.1907229
Cooke M, Hershey JR, Rennie SJ, 2010. Monaural speech separation and recognition challenge. Comput Speech Lang, 24(1):1–15. https://doi.org/10.1016/j.csl.2009.02.006
Dehak N, Kenny PJ, Dehak R, et al., 2011. Front-end factor analysis for speaker verification. IEEE Trans Audio Speech Lang Process, 19(4):788–798. https://doi.org/10.1109/TASL.2010.2064307
Doclo S, Moonen M, 2003. Design of far-field and near-field broadband beamformers using eigenfilters. IEEE Signal Process Lett, 83(12):2641–2673. https://doi.org/10.1016/j.sigpro.2003.07.005
Drude L, Haeb-Umbach R, 2017. Tight integration of spatial and spectral features for BSS with deep clustering embeddings. Annual Conf of Int Speech Communication Association, p.2650–2654.
Du J, Tu Y, Xu Y, et al., 2014. Speech separation of a target speaker based on deep neural networks. Int Conf on Signal Processing, p.473–477. https://doi.org/10.1109/ICOSP.2014.7015050
Ellis DPW, 1996. Prediction-Driven Computational Auditory Scene Analysis. PhD Thesis, Massachusetts Institute of Technology, Cambridge, USA.
Ephraim Y, Malah D, 1985. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans Audio Speech Lang Process, 33(2): 443–445. https://doi.org/10.1109/TASSP.1985.1164550
Erdogan H, Hershey JR, Watanabe S, et al., 2015. Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks. Int Conf on Acoustics Speech and Signal Processing, p.708–712. https://doi.org/10.1109/ICASSP.2015.7178061
Erdogan H, Hershey J, Watanabe S, et al., 2016. Improved MVDR beamforming using single-channel mask prediction networks. Annual Conf of Int Speech Communication Association, p.1981–1985.
Erdogan H, Hershey JR, Watanabe S, et al., 2017. Deep recurrent networks for separation and recognition of single-channel speech in nonstationary background audio. New Era for Robust Speech Recognition, p.165–186. https://doi.org/10.1007/978-3-319-64680-0_7
Fischer S, Simmer KU, 1996. Beamforming microphone arrays for speech acquisition in noisy environments. Speech Commun, 20(3-4):215–227. https://doi.org/10.1016/S0167-6393(96)00054-4
Frost OL, 1972. An algorithm for linearly constrained adaptive array processing. Proc IEEE, 60(8):926–935. https://doi.org/10.1109/PROC.1972.8817
Gannot S, Burshtein D, Weinstein E, 2001. Signal enhancement using beamforming and nonstationarity with applications to speech. IEEE Trans Signal Process, 49(8): 1614–1626. https://doi.org/10.1109/78.934132
Gannot S, Burshtein D, Weinstein E, 2004. Analysis of the power spectral deviation of the general transfer function GSC. IEEE Trans Signal Process, 52(4):1115–1120. https://doi.org/10.1109/TSP.2004.823487
Ghahramani Z, Jordan MI, 1996. Factorial hidden Markov models. NIPS, p.472–478.
Hassab JC, Boucher RE, 1981. Performance of the generalized cross correlator in the presence of a strong spectral peak in the signal. IEEE Trans Audio Speech Lang Process, 29(3):549–555. https://doi.org/10.1109/TASSP.1981.1163613
Hershey JR, Kristjansson T, Rennie S, et al., 2007. Single channel speech separation using factorial dynamics. NIPS, p.593–600.
Hershey JR, Rennie SJ, Olsen PA, et al., 2010. Super-human multi-talker speech recognition: a graphical modeling approach. Comput Speech Lang, 24(1):45–66. https://doi.org/10.1016/j.csl.2008.11.001
Hershey JR, Chen Z, Le Roux J, et al., 2016. Deep clustering: discriminative embeddings for segmentation and separation. Int Conf on Acoustics Speech and Signal Processing, p.31–35. https://doi.org/10.1109/ICASSP.2016.7471631
Heymanna J, Drudea L, Haeb-Umbacha R, 2017. A generic neural acoustic beamforming architecture for robust multi-channel speech processing. Comput Speech Lang, 46(C):374–385. https://doi.org/10.1016/j.csl.2016.11.007
Hinton G, Deng L, Yu D, et al., 2012. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Process Mag, 29(6):82–97. https://doi.org/10.1109/MSP.2012.2205597
Hoyer PO, 2004. Non-negative matrix factorization with sparseness constraints. J Mach Learn Res, 5:1457–1469.
Hu G, Wang D, 2004. Monaural speech segregation based on pitch tracking and amplitude modulation. IEEE Trans Neur Netw, 15(5):1135–1150. https://doi.org/10.1109/TNN.2004.832812
Hu G, Wang D, 2008. Segregation of unvoiced speech from nonspeech interference. J Acoust Soc Am, 124(2): 1306–1319. https://doi.org/10.1121/1.2939132
Hu G, Wang D, 2010. A tandem algorithm for pitch estimation and voiced speech segregation. IEEE Trans Audio Speech Lang Process, 18(8):2067–2079. https://doi.org/10.1109/TASL.2010.2041110
Hu K, Wang D, 2013. An unsupervised approach to cochannel speech separation. IEEE Trans Audio Speech Lang Process, 21(1):122–131. https://doi.org/10.1109/TASL.2012.2215591
Hu Y, Loizou PC, 2007. Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun, 49(7):588–601. https://doi.org/10.1016/j.specom.2006.12.006
Hu Y, Loizou PC, 2008. Evaluation of objective quality measures for speech enhancement. IEEE Trans Audio Speech Lang Process, 16(1):229–238. https://doi.org/10.1109/TASL.2007.911054
Huang Z, Wang S, Qian Y, 2018. Joint i-vector with end-toend system for short duration text-independent speaker verification. Int Conf on Acoustics, Speech, and Signal Processing, in press.
Hyvarinen A, Karhunen J, Oja E, 2001. Independent Component Analysis. John Wiley & Sons, Inc, New York, USA.
Isik Y, Roux JL, Chen Z, et al., 2016. Single-channel multispeaker separation using deep clustering. Annual Conf of Int Speech Communication Association, p.545–549. https://doi.org/10.21437/Interspeech.2016-1176
Kellermann W, 1997. Strategies for combining acoustic echo cancellation and adaptive beamforming microphone arrays. Int Conf on Acoustics Speech and Signal Processing, p.219–222. https://doi.org/10.1109/ICASSP.1997.599608
Kim T, Attias HT, Lee SY, et al., 2006. Blind source separation exploiting higher-order frequency dependencies. IEEE Trans Audio Speech Lang Process, 15(4):70–79. https://doi.org/10.1109/TASL.2006.872618
Kjems U, Boldt JB, Pedersen MS, et al., 2009. Role of mask pattern in intelligibility of ideal binary-masked noisy speech. J Acoust Soc Am, 126(3):1415–1426. https://doi.org/10.1121/1.3179673
Knapp CK, Carter GC, 1976. The generalized correlation method for estimation of time delay. IEEE Trans Audio Speech Lang Process, 24(4):320–327. https://doi.org/10.1109/TASSP.1976.1162830
Kolbæk M, Yu D, Tan ZH, et al., 2017a. Joint separation and denoising of noisy multi-talker speech using recurrent neural networks and permutation invariant training. IEEE Int Workshop on Machine Learning for Signal Processing. http://arxiv.org/abs/1708.09588
Kolbæk M, Yu D, Tan ZH, et al., 2017b. Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks. IEEE Trans Audio Speech Lang Process, 25(10):1901–1913. https://doi.org/10.1109/TASLP.2017.2726762
Kristjansson T, Hershey J, Olsen P, et al., 2006. Superhuman multi-talker speech recognition: the IBM 2006 speech separation challenge system. Int Conf on Spoken Language Processing, Paper 1775-Mon1WeS.7.
Kuhl PK, 1991. Human adults and human infants show a “perceptual magnet effect” for the prototypes of speech categories, monkeys do not. Percept Psychol, 50(2):93–107. https://doi.org/10.3758/BF03212211
Larcher A, Lee KA, Ma B, et al., 2014. Textdependent speaker verification: classifiers, databases and RSR2015. Speech Commun, 60:56–77. https://doi.org/10.1016/j.specom.2014.03.001
Lee DD, Seung HS, 2001. Algorithms for non-negative matrix factorization. NIPS, p.556–562.
Lee TW, 1998. Independent Component Analysis—Theory and Applications. Kluwer Academic Publishers, Boston, USA.
Lei Y, Scheffer N, Ferrer L, et al., 2014. A novel scheme for speaker recognition using a phonetically-aware deep neural network. Int Conf on Acoustics Speech and Signal Processing, p.1695–1699. https://doi.org/10.1109/ICASSP.2014.6853887
Li P, Guan Y, Wang S, et al., 2010. Monaural speech separation based on MAXVQ and CASA for robust speech recognition. Comput Speech Lang, 24(1):30–44. https://doi.org/10.1016/j.csl.2008.05.005
Liu Y, Qian Y, Chen N, et al., 2015. Deep feature for text-dependent speaker verification. Speech Commun, 73:1–13. https://doi.org/10.1016/j.specom.2015.07.003
Lovekin JM, Yantorno RE, Krishnamachari KR, et al., 2001. Developing usable speech criteria for speaker identification technology. Int Conf on Acoustics Speech and Signal Processing, p.421–424. https://doi.org/10.1109/ICASSP.2001.940857
Mandel MI, Weiss RJ, Ellis DPW, 2010. Model-based expectation maximization source separation and localization. IEEE Trans Audio Speech Lang Process, 18(2):382–394. https://doi.org/10.1109/TASL.2009.2029711
McDermott JH, 2009. The cocktail party problem. Curr Biol, 19(22):R1024–R1027.
Mesgarani N, Chang EF, 2012. Selective cortical representation of attended speaker in multi-talker speech perception. Nature, 485(7397):233–236. https://doi.org/10.1038/nature11020
Mowlaee P, Saeidi R, Tan ZH, et al., 2010. Joint singlechannel speech separation and speaker identification. Int Conf on Acoustics Speech and Signal Processing, p.4430–4433. https://doi.org/10.1109/ICASSP.2010.5495619
Mowlaee P, Saeidi R, Christensen MG, et al., 2012. A joint approach for single-channel speaker identification and speech separation. IEEE Trans Audio Speech Lang Process, 20(9):2586–2601. https://doi.org/10.1109/TASL.2012.2208627
Narayanan A, Wang D, 2013. Ideal ratio mask estimation using deep neural networks for robust speech recognition. Int Conf on Acoustics Speech and Signal Processing, p.7092–7096. https://doi.org/10.1109/ICASSP.2013.6639038
Ono N, 2011. Stable and fast update rules for independent vector analysis based on auxiliary function technique. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics. https://doi.org/10.1109/ASPAA.2011.6082320
Peddinti V, Povey D, Khudanpur S, 2015. A time delay neural network architecture for efficient modeling of long temporal contexts. Annual Conf of Int Speech Communication Association, p.3214–3218.
Pedersen MS, Larsen J, Kjems U, et al., 2007. A Survey of Convolutive Blind Source Separation Methods. Springer Press, New York, USA.
Qian YM, Bi M, Tan T, et al., 2016. Very deep convolutional neural networks for noise robust speech recognition. IEEE Trans Audio Speech Lang Process, 24(12):2263–2276. https://doi.org/10.1109/TASLP.2016.2602884
Qian YM, Chang XK, Yu D, 2017. Single-channel multitalker speech recognition with permutation invariant training. http://arxiv.org/abs/1707.06527
Qian YM, Tan T, Hu H, et al., 2018. Noise robust speech recognition on Aurora4 by humans and machines. Int Conf on Acoustics, Speech, and Signal Processing, in press.
Raj B, Virtanen T, Chaudhuri S, et al., 2010. Non-negative matrix factorization based compensation of music for automatic speech recognition. Annual Conf of Int Speech Communication Association, p.717–720.
Rennie SJ, Hershey JR, Olsen PA, 2010. Single-channel multitalker speech recognition. IEEE Signal Process Mag, 27(6):66–80. https://doi.org/10.1109/MSP.2010.938081
Reynolds DA, Quatieri TF, Dunn RB, 2000. Speaker verification using adapted gaussian mixture models. Dig Signal Process, 10(1-3):19–41. https://doi.org/10.1006/dspr.1999.0361
Rix AW, Beerends JG, Hollier MP, et al., 2001. Perceptual evaluation of speech quality (PESQ)—a new method for speech quality assessment of telephone networks and codecs. Int Conf on Acoustics, Speech, and Signal Processing, p.749–752. https://doi.org/10.1109/ICASSP.2001.941023
Roth P, 1971. Effective measurements using digital signal analysis. IEEE Spectr, 8(4):62–70.
Sainath TN, Mohamed A, Kingsbury B, et al., 2013. Deep convolutional neural networks for LVCSR. Int Conf on Acoustics Speech and Signal Processing, p.8614–8618.
Sainath TN, Vinyals O, Senior A, et al., 2015. Convolutional, long short-term memory, fully connected deep neural networks. Int Conf on Acoustics Speech and Signal Processing, p.4580–4584. https://doi.org/10.1109/ICASSP.2015.7178838
Sawada H, Araki S, Makino S, 2007. A two-stage frequencydomain blind source separation method for underdetermined convolutive mixtures. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, p.139–142. https://doi.org/10.1109/ASPAA.2007.4393012
Schmidt MN, Olsson RK, 2006. Single-channel speech separation using sparse non-negative matrix factorization. Annual Conf of Int Speech Communication Association, Paper 1652-Thu2FoP.10.
Schuller B, Weninger F, Wöllmer M, et al., 2010. Nonnegative matrix factorization as noise-robust feature extractor for speech recognition. Int Conf on Acoustics Speech and Signal Processing, p.4562–4565. https://doi.org/10.1109/ICASSP.2010.5495567
Sercu T, Puhrsch C, Kingsbury B, et al., 2016. Very deep multilingual convolutional neural networks for LVCSR. Int Conf on Acoustics Speech and Signal Processing, p.4955–4959. https://doi.org/10.1109/ICASSP.2016.7472620
Shao Y, Wang D, 2003. Co-channel speaker identification using usable speech extraction based on multi-pitch tracking. Int Conf on Acoustics, Speech, and Signal Processing, p.205–208. https://doi.org/10.1109/ICASSP.2003.1202330
Shao Y, Wang D, 2006. Model-based sequential organization in cochannel speech. IEEE Trans Audio Speech Lang Process, 14(1):289–298. https://doi.org/10.1109/TSA.2005.854106
Souden M, Benesty J, Affes S, 2010. On optimal frequencydomain multichannel linear filtering for noise reduction. IEEE Trans Signal Process, 18(2):260–276. https://doi.org/10.1109/TASL.2009.2025790
Souden M, Araki S, Kinoshita K, et al., 2013. A multichannel MMSE-based framework for speech source separation and noise reduction. IEEE Trans Signal Process, 21(9):1913–1928. https://doi.org/10.1109/TASL.2013.2263137
Sydow C, 1994. Broadband beamforming for a microphone array. J Acoust Soc Am, 96(8):845–849. https://doi.org/10.1121/1.410323
Taal CH, Hendriks RC, Heusdens R, et al., 2010. A shorttime objective intelligibility measure for time-frequency weighted noisy speech. Int Conf on Acoustics Speech and Signal Processing, p.4214–4217. https://doi.org/10.1109/ICASSP.2010.5495701
Tan T, Qian Y, Yu D, 2018. Knowledge transfer in permutation invariant training for single-channel multi-talker speech recognition. Int Conf on Acoustics, Speech, and Signal Processing, in press.
Tu Y, Du J, Xu Y, et al., 2014a. Deep neural network based speech separation for robust speech recognition. Int Conf on Signal Processing, p.532–536. https://doi.org/10.1109/ICOSP.2014.7015061
Tu Y, Du J, Xu Y, et al., 2014b. Speech separation based on improved deep neural networks with dual outputs of speech features for both target and interfering speakers. Int Symp on Chinese Spoken Language Processing, p.250–254. https://doi.org/10.1109/ISCSLP.2014.6936615
Variani E, Lei X, McDermott E, et al., 2014. Deep neural networks for small footprint text-dependent speaker verification. Int Conf on Acoustics Speech and Signal Processing, p.4052–4056. https://doi.org/10.1109/ICASSP.2014.6854363
Vincent E, Gribonval R, Févotte C, 2006. Performance measurement in blind audio source separation. IEEE Trans Audio Speech Lang Process, 14(4):1462–1469. https://doi.org/10.1109/TSA.2005.858005
Virtanen T, 2006. Speech recognition using factorial hidden Markov models for separation in the feature space. Annual Conf of Int Speech Communication Association, Paper 1850-Mon1WeS.5.
Virtanen T, 2007. Monaural sound source separation by nonnegative matrix factorization with temporal continuity and sparseness criteria. IEEE Trans Audio Speech Lang Process, 15(3):1066–1074. https://doi.org/10.1109/TASL.2006.885253
Wang D, 2005. On ideal binary mask as the computational goal of auditory scene analysis. In: Divenyi P (Ed.), Speech Separation by Humans and Machines. Springer, Boston, USA, p.181–197. https://doi.org/10.1007/0-387-22794-6_12
Wang D, Brown GJ, 2006. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Wiley-IEEE Press, New York, USA.
Wang S, Qian Y, Yu K, 2018. Focal KL-divergence based dilated convolutional neural networks for co-channel speaker identification. Int Conf on Acoustics, Speech, and Signal Processing, in press.
Wang Y, Narayanan A, Wang D, 2014. On training targets for supervised speech separation. IEEE Trans Audio Speech Lang Process, 22(12):1849–1858. https://doi.org/10.1109/TASLP.2014.2352935
Weng C, Yu D, Seltzer ML, et al., 2015. Deep neural networks for single-channel multi-talker speech recognition. IEEE Trans Audio Speech Lang Process, 23(10):1670–1679. https://doi.org/10.1109/TASLP.2015.2444659
Weninger F, Erdogan H, Watanabe S, et al., 2015. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. Int Conf on Latent Variable Analysis and Signal Separation, p.91–99. https://doi.org/10.1007/978-3-319-22482-4_11
Xiao X, Zhao SK, Jones DL, et al., 2017. On time-frequency mask estimation for MVDR beamforming with application in robust speech recognition. Int Conf on Acoustics Speech and Signal Processing, p.3246–3250. https://doi.org/10.1109/ICASSP.2017.7952756
Xiong W, Droppo J, Huang X, et al., 2016. Achieving human parity in conversational speech recognition. http://arxiv.org/abs/1610.05256
Xu Y, Du J, Dai LR, et al., 2014. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process Lett, 21(1):65–68. https://doi.org/10.1109/LSP.2013.2291240
Yilmaz O, Rickard S, 2004. Blind separation of speech mixtures via time-frequency masking. IEEE Trans Signal Process, 52(7):1830–1847. https://doi.org/10.1109/TSP.2004.828896
Yu D, Deng L, 2014. Automatic Speech Recognition: a Deep Learning Approach. Springer, New York, USA.
Yu D, Li, JY, 2017. Recent progresses in deep learning based acoustic models. IEEE/CAA J Automat Sin, 4(3):396–409. https://doi.org/10.1109/JAS.2017.7510508
Yu D, Xiong W, Droppo J, et al., 2016. Deep convolutional neural networks with layer-wise context expansion and attention. Annual Conf of Int Speech Communication Association, p.17–21. https://doi.org/10.21437/Interspeech.2016-251
Yu D, Chang X, Qian Y, 2017a. Recognizing multi-talker speech with permutation invariant training. Annual Conf of Int Speech Communication Association, p.2456–2460.
Yu D, Kolbæk M, Tan ZH, et al., 2017b. Permutation invariant training of deep models for speaker-independent multi-talker speech separation. Int Conf on Acoustics, Speech and Signal Processing, p.241–245. https://doi.org/10.1109/ICASSP.2017.7952154
Yu F, Koltun V, 2015. Multi-scale context aggregation by dilated convolutions. http://arxiv.org/abs/1511.07122
Zhang C, Koishida K, 2017. End-to-end text-independent speaker verification with triplet loss on short utterances. Annual Conf of Int Speech Communication Association, p.1487–1491. https://doi.org/10.21437/Interspeech.2017-1608
Zhang L, Chen Z, Zheng M, et al., 2011. Robust nonnegative matrix factorization. Front. Electr. Electron. Eng. China, 6(2):192–200. https://doi.org/10.1007/s11460-011-0128-0
Zhao X, Wang Y, Wang D, 2015a. Cochannel speaker identification in anechoic and reverberant conditions. IEEE Trans Audio Speech Lang Process, 23(11):1727–1736. https://doi.org/10.1109/TASLP.2015.2447284
Zhao X, Wang Y, Wang D, 2015b. Deep neural networks for cochannel speaker identification. Int Conf on Acoustics, Speech and Signal Processing, p.4824–4828. https://doi.org/10.1109/ICASSP.2015.7178887
Zhou Y, Qian Y, 2018. Robust mask estimation by integrating neural network-based and clustering-based approaches for adaptive acoustic beamforming. Int Conf on Acoustics, Speech, and Signal Processing, in press.
Zmolikova K, Delcroix M, Kinoshita K, et al., 2017. Speakeraware neural network based beamformer for speaker extraction in speech mixtures. Annual Conf of Int Speech Communication Association, p.2655–2659. https://doi.org/10.21437/Interspeech.2017-667
Author information
Authors and Affiliations
Corresponding author
Additional information
Project supported by the Tencent and Shanghai Jiao Tong University Joint Project
Rights and permissions
About this article

Cite this article
Qian, Ym., Weng, C., Chang, Xk. et al. Past review, current progress, and challenges ahead on the cocktail party problem. Frontiers Inf Technol Electronic Eng 19, 40–63 (2018). https://doi.org/10.1631/FITEE.1700814
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1631/FITEE.1700814
Keywords
- Cocktail party problem
- Computational auditory scene analysis
- Non-negative matrix factorization
- Permutation invariant training
- Multi-talker speech processing