
Abstract
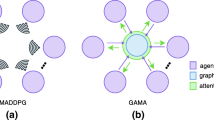
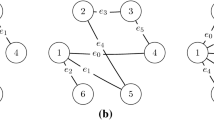
The recent progress in multi-agent deep reinforcement learning (MADRL) makes it more practical in real-world tasks, but its relatively poor scalability and the partially observable constraint raise more challenges for its performance and deployment. Based on our intuitive observation that human society could be regarded as a large-scale partially observable environment, where everyone has the functions of communicating with neighbors and remembering his/her own experience, we propose a novel network structure called the hierarchical graph recurrent network (HGRN) for multi-agent cooperation under partial observability. Specifically, we construct the multi-agent system as a graph, use a novel graph convolution structure to achieve communication between heterogeneous neighboring agents, and adopt a recurrent unit to enable agents to record historical information. To encourage exploration and improve robustness, we design a maximum-entropy learning method that can learn stochastic policies of a configurable target action entropy. Based on the above technologies, we propose a value-based MADRL algorithm called Soft-HGRN and its actor-critic variant called SAC-HGRN. Experimental results based on three homogeneous tasks and one heterogeneous environment not only show that our approach achieves clear improvements compared with four MADRL baselines, but also demonstrate the interpretability, scalability, and transferability of the proposed model.
摘要
近年来,多智能体深度强化学习(multi-agent deep reinforcement learning, MADRL)的研究进展使其在现实世界的任务中更加实用,但其相对较差的可扩展性和部分可观测的限制为MADRL模型的性能和部署带来了更多的挑战。人类社会可以被视为一个大规模的部分可观测环境,其中每个人都具备与他人交流并记忆经验的功能。基于人类社会的启发,我们提出一种新的网络结构,称为层次图递归网络(hierarchical graph recurrent network, HGRN),用于部分可观测环境下的多智能体合作任务。具体来说,我们将多智能体系统构建为一个图,利用新颖的图卷积结构来实现异构相邻智能体之间的通信,并采用一个递归单元来使智能体具备记忆历史信息的能力。为了鼓励智能体探索并提高模型的鲁棒性,我们进而设计一种最大熵学习方法,令智能体可以学习可配置目标行动熵的随机策略。基于上述技术,我们提出一种名为Soft-HGRN的基于值的MADRL算法,及其名为SAC-HGRN的actor-critic变体。在三个同构场景和一个异构环境中进行实验;实验结果不仅表明我们的方法相比四个MADRL基线取得了明显的改进,而且证明了所提模型的可解释性、可扩展性和可转移性。
Similar content being viewed by others

Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Change history
27 March 2023
An Erratum to this paper has been published: https://doi.org/10.1631/FITEE.22e0073
References
Adler JL, Satapathy G, Manikonda V, et al., 2005. A multi-agent approach to cooperative traffic management and route guidance. Trans Res Part B, 39(4):297–318. https://doi.org/10.1016/j.trb.2004.03.005
Cho K, van Merriënboer B, Gulcehre C, et al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. Proc Conf on Empirical Methods in Natural Language Processing, p.1724–1734. https://doi.org/10.3115/v1/D14-1179
Chu TS, Wang J, Codecà L, et al., 2020. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Trans Intell Transp Syst, 21(3):1086–1095. https://doi.org/10.1109/TITS.2019.2901791
Claus C, Boutilier C, 1998. The dynamics of reinforcement learning in cooperative multiagent systems. Proc 15th National Conf on Artificial Intelligence and 10th Innovative Applications of Artificial Intelligence Conf, p.746–752.
Foerster JN, Assael YM, de Freitas N, et al., 2016. Learning to communicate with deep multi-agent reinforcement learning. Proc 30th Int Conf on Neural Information Processing Systems, p.2145–2153.
Haarnoja T, Tang HR, Abbeel P, et al., 2017. Reinforcement learning with deep energy-based policies. Proc 34th Int Conf on Machine Learning, p.1352–1361.
Haarnoja T, Zhou A, Abbeel P, et al., 2018. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. Proc 35th Int Conf on Machine Learning, p.1861–1870.
Hausknecht M, Stone P, 2015. Deep recurrent Q-learning for partially observable MDPs. Proc AAAI Fall Symp Series, p.29–37.
He KM, Zhang XY, Ren SQ, et al., 2016. Deep residual learning for image recognition. Proc IEEE Conf on Computer Vision and Pattern Recognition, p.770–778. https://doi.org/10.1109/CVPR.2016.90
Iqbal S, Sha F, 2019. Actor-attention-critic for multi-agent reinforcement learning. Proc 36th Int Conf on Machine Learning, p.2961–2970.
Jiang JC, Dun C, Huang TJ, et al., 2020. Graph convolutional reinforcement learning. Proc 8th Int Conf on Learning Representations.
Kingma DP, Ba J, 2015. Adam: a method for stochastic optimization. Proc 3rd Int Conf on Learning Representations.
Lillicrap TP, Hunt JJ, Pritzel A, et al., 2015. Continuous control with deep reinforcement learning. Proc 4th Int Conf on Learning Representations.
Lin LJ, 1992. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach Learn, 8(3–4):293–321. https://doi.org/10.1007/BF00992699
Lowe R, Wu Y, Tamar A, et al., 2017. Multi-agent actor-critic for mixed cooperative-competitive environments. Proc 31st Int Conf on Neural Information Processing Systems, p.6382–6393.
Mnih V, Kavukcuoglu K, Silver D, et al., 2015. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533. https://doi.org/10.1038/nature14236
Mnih V, Badia AP, Mirza M, et al., 2016. Asynchronous methods for deep reinforcement learning. Proc 33rd Int Conf on Machine Learning, p.1928–1937.
Rashid T, Samvelyan M, Schroeder C, et al., 2018. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. Proc 35th Int Conf on Machine Learning, p.4295–4304.
Rui P, 2010. Multi-UAV formation maneuvering control based on Q-learning fuzzy controller. Proc 2nd Int Conf on Advanced Computer Control, p.252–257. https://doi.org/10.1109/ICACC.2010.5486961
Ryu H, Shin H, Park J, 2020. Multi-agent actor-critic with hierarchical graph attention network. Proc AAAI Conf Artif Intell, p.7236–7243. https://doi.org/10.1609/aaai.v34i05.6214
Sukhbaatar S, Szlam A, Fergus R, 2016. Learning multi-agent communication with backpropagation. Proc 30th Int Conf on Neural Information Processing Systems, p.2252–2260.
Vaswani A, Shazeer N, Parmar N, et al., 2017. Attention is all you need. Proc 31st Int Conf on Neural Information Processing Systems, p.6000–6010. https://doi.org/10.5555/3295222.3295349
Veličković P, Cucurull G, Casanova A, et al., 2018. Graph attention networks. Proc 6th Int Conf on Learning Representations.
Wang RE, Everett M, How JP, 2020. R-MADDPG for partially observable environments and limited communication. https://doi.org/10.48550/arXiv.2002.06684
Watkins CJCH, Dayan P, 1992. Q-learning. Mach Learn, 8(3–4):279–292. https://doi.org/10.1007/BF00992698
Ye DY, Zhang MJ, Yang Y, 2015. A multi-agent framework for packet routing in wireless sensor networks. Sensors, 15(5):10026–10047. https://doi.org/10.3390/s150510026
Ye ZH, Chen YN, Jiang XH, et al., 2022a. Improving sample efficiency in multi-agent actor-critic methods. Appl Intell, 52(4):3691–3704. https://doi.org/10.1007/s10489-021-02554-5
Ye ZH, Wang K, Chen YN, et al., 2022b. Multi-UAV navigation for partially observable communication coverage by graph reinforcement learning. IEEE Trans Mobile Comput, early access. https://doi.org/10.1109/TMC.2022.3146881
Zhang KQ, Yang ZR, Liu H, et al., 2018. Fully decentralized multi-agent reinforcement learning with networked agents. Proc 35th Int Conf on Machine Learning, p.5872–5881.
Zhang Y, Mou ZY, Gao FF, et al., 2020. UAV-enabled secure communications by multi-agent deep reinforcement learning. IEEE Trans Veh Technol, 69(10):11599–11611. https://doi.org/10.1109/TVT.2020.3014788
Zheng LM, Yang JC, Cai H, et al., 2018. MAgent: a many-agent reinforcement learning platform for artificial collective intelligence. Proc 32nd AAAI Conf on Artificial Intelligence, p.8222–8223.
Author information
Authors and Affiliations
Contributions
Zhenhui YE, Yixiang REN, and Guanghua SONG designed the research. Zhenhui YE and Yixiang REN processed the data. Zhenhui YE drafted the paper. Yixiang REN helped organize and revise the paper. Yining CHEN, Xiaohong JIANG, and Guanghua SONG revised and finalized the paper.
Corresponding author
Additional information
Compliance with ethics guidelines
Yixiang REN, Zhenhui YE, Yining CHEN, Xiaohong JIANG, and Guanghua SONG declare that they have no conflict of interest.
List of supplementary materials
1 Detailed derivations for Section 4
2 Environment details
Fig. S1 Screenshots of the tested simulation environments
3 Experimental settings and results
Table S1 Hyper-parameter settings of all environments
Fig. S2 Comparison of Soft-HGRN with different communication structures in UAV-MBS
Fig. S3 Learning curves in the UAV-MBS environment
Fig. S4 Learning curves in the Surviving environment
Fig. S5 Learning curves in the Pursuit environment
Project supported by the National Key R&D Program of China (No. 2018AAA010230)
Supplementary materials for
Rights and permissions
About this article

Cite this article
Ren, Y., Ye, Z., Chen, Y. et al. Soft-HGRNs: soft hierarchical graph recurrent networks for multi-agent partially observable environments. Front Inform Technol Electron Eng 24, 117–130 (2023). https://doi.org/10.1631/FITEE.2200073
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1631/FITEE.2200073
Key words
- Deep reinforcement learning
- Graph-based communication
- Maximum-entropy learning
- Partial observability
- Heterogeneous settings